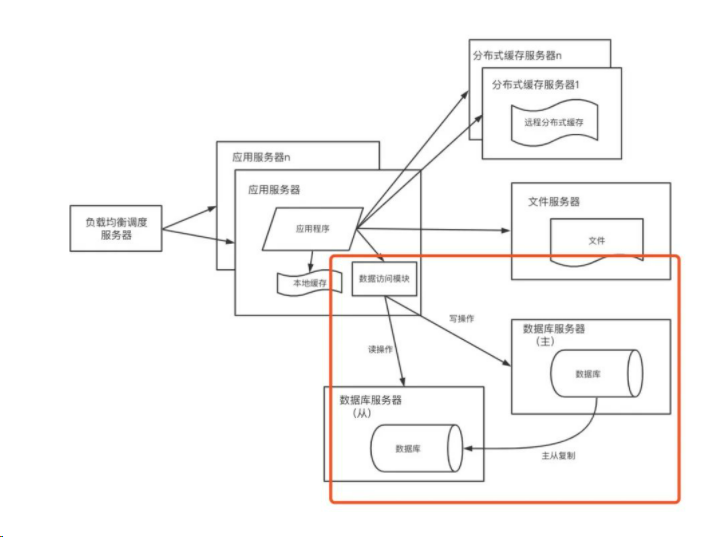
MySQL-高可用
1、分库分表
分库分表包括分库和分表两个部分,通常包括:垂直分库、水平分库、垂直分表、水平分表四种方式。
垂直分表
定义:将一个表按照字段分成多表,每个表存储其中一部分字段。
json它带来的提升是: 1.为了避免IO争抢并减少锁表的几率 2.充分发挥热门数据的操作效率 一般来说,某业务实体中的各个数据项的访问频次是不一样的,部分数据项可能是占用存储空间比较大的BLOB或是TEXT。例如上例中的商品描述。所以,当表数据量很大时,可以将表按字段切开,将热门字段、冷门字段分开放置在不同库中,这些库可以放在不同的存储设备上,避免IO争抢。垂直切分带来的性能提升主要集中在热门数据的操作效率上,而且磁盘争用情况减少。 通常我们按以下原则进行垂直拆分: 1. 把不常用的字段单独放在一张表; 2. 把text,blob等大字段拆分出来放在附表中; 3. 经常组合查询的列放在一张表中;
垂直分库
定义:垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。
json它带来的提升是: 解决业务层面的耦合,业务清晰 能对不同业务的数据进行分级管理、维护、监控、扩展等 高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈 垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题
水平分库
定义:水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上
json它带来的提升是: 解决了单库大数据,高并发的性能瓶颈 提高了系统的稳定性及可用性 当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库了,经过水平切分的优化,往往能解决单库存储量及性能瓶颈。但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度
水平分表
定义:水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
json它带来的提升是: 优化单一表数据量过大而产生的性能问题 避免IO争抢并减少锁表的几率库内的水平分表,解决了单一表数据量过大的问题,分出来的小表中只包含一部分数据,使得单个表的数据量变小,提高检索性能。
Sharding 策略
- 哈希取模:hash(key)%N
- 范围:可以是 ID 范围也可以是时间范围
- 映射表:使用单独的一个数据库来存储映射关系
分库分表带来的问题
事务一致性问题 - 分布式事务解决方案
跨节点关联查询 - 可以将原来的连接分解成多个单表查询,然后在用户程序中进行连接。
跨节点分页、排序函数
主键避重 - 单独设计全局主键,避免跨库主键重复问题
- 使用全局唯一 ID (GUID)
- 为每个分片指定一个 ID 范围
- 分布式 ID 生成器(如 Twitter 的 Snowflake 算法)
公共表
2、主从复制
主从复制是指将主数据库的DDL和DML操作通过二进制日志传到从数据库上,然后在从数据库上对这些日志进行重新执行,从而使从数据库和主数据库的数据保持一致。
主从复制原理
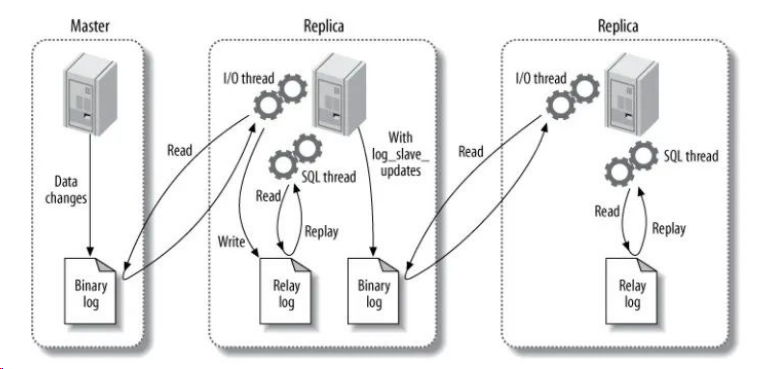
主要涉及三个线程:binlog 线程、I/O 线程和 SQL 线程。
- binlog 线程 :负责将主服务器上的数据更改写入二进制日志(Binary log)中。
- I/O 线程 :负责从主服务器上读取- 二进制日志,并写入从服务器的中继日志(Relay log)。
- SQL 线程 :负责读取中继日志,解析出主服务器已经执行的数据更改并在从服务器中重放(Replay)。
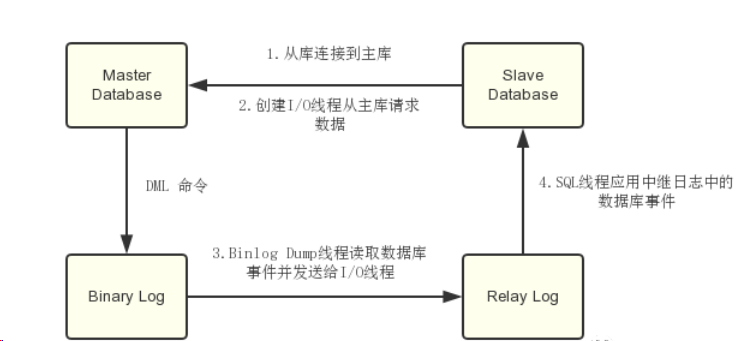
- sql主库在事务提交时会把数据变更作为事件记录在二进制日志Binlog中;
- 主库推送二进制日志文件Binlog中的事件到从库的中继日志Relay Log中,之后从库根据中继日志重做数据变更操作,通过逻辑复制来达到主库和从库的数据一致性;
- sql通过三个线程来完成主从库间的数据复制,其中Binlog Dump线程跑在主库上,I/O线程和SQL线程跑着从库上;
- 当在从库上启动复制时,首先创建I/O线程连接主库,主库随后创建Binlog Dump线程读取数据库事件并发送给I/O线程,I/O线程获取到事件数据后更新到从库的中继日志Relay Log中去,之后从库上的SQL线程读取中继日志Relay Log中更新的数据库事件并应用,如下图所示。
实例搭建
主实例搭建
- 运行sql主实例:
docker run -p 3307:3306 --name sql-master \
-v /mydata/sql-master/log:/var/log/sql \
-v /mydata/sql-master/data:/var/lib/sql \
-v /mydata/sql-master/conf:/etc/sql \
-e sql_ROOT_PASSWORD=root \
-d sql:5.7- 在sql的配置文件夹
/mydata/sql-master/conf中创建一个配置文件my.cnf:
touch my.cnf- 修改配置文件my.cnf,配置信息如下:
[sqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=sql
## 开启二进制日志功能
log-bin=mall-sql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062- 修改完配置后重启实例:
docker restart sql-master- 进入
sql-master容器中:
docker exec -it sql-master /bin/bash- 在容器中使用sql的登录命令连接到客户端:
sql -uroot -proot- 创建数据同步用户:
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%';从实例搭建
- 运行sql从实例:
docker run -p 3308:3306 --name sql-slave \
-v /mydata/sql-slave/log:/var/log/sql \
-v /mydata/sql-slave/data:/var/lib/sql \
-v /mydata/sql-slave/conf:/etc/sql \
-e sql_ROOT_PASSWORD=root \
-d sql:5.7- 在sql的配置文件夹
/mydata/sql-slave/conf中创建一个配置文件my.cnf:
touch my.cnf- 修改配置文件my.cnf:
[sqld]
## 设置server_id,同一局域网中需要唯一
server_id=102
## 指定不需要同步的数据库名称
binlog-ignore-db=sql
## 开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用
log-bin=mall-sql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log配置中继日志
relay_log=mall-sql-relay-bin
## log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
## slave设置为只读(具有super权限的用户除外)
read_only=1- 修改完配置后重启实例:
docker restart sql-slave主从连接
- 连接到主数据库的sql客户端,查看主数据库状态:
show master status;- 主数据库状态显示如下:

- 进入
sql-slave容器中:
docker exec -it sql-slave /bin/bash- 在容器中使用sql的登录命令连接到客户端:
sql -uroot -proot- 在从数据库中配置主从复制:
change master to master_host='192.168.6.132', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-sql-bin.000001', master_log_pos=617, master_connect_retry=30;主从复制命令参数说明:
- master_host:主数据库的IP地址;
- master_port:主数据库的运行端口;
- master_user:在主数据库创建的用于同步数据的用户账号;
- master_password:在主数据库创建的用于同步数据的用户密码;
- master_log_file:指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数;
- master_log_pos:指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数;
- master_connect_retry:连接失败重试的时间间隔,单位为秒。
查看主从同步状态:
show slave status \G;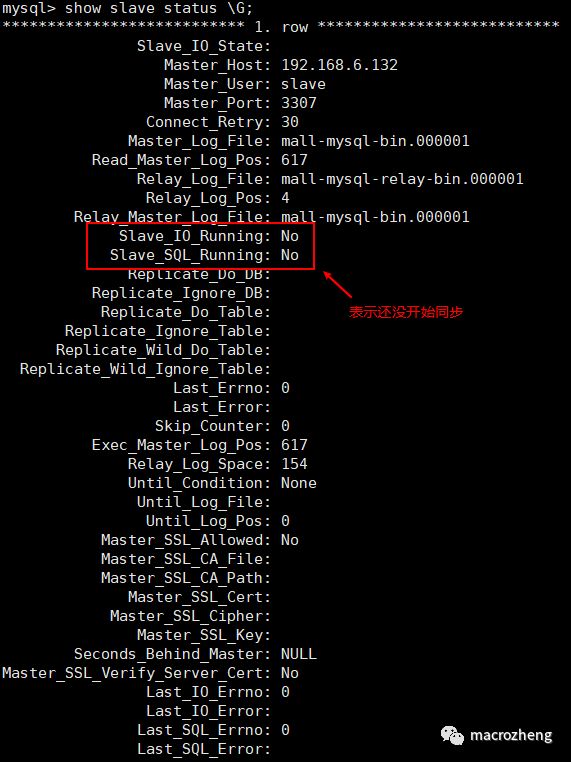
- 开启主从同步:
start slave;- 查看从数据库状态发现已经同步:
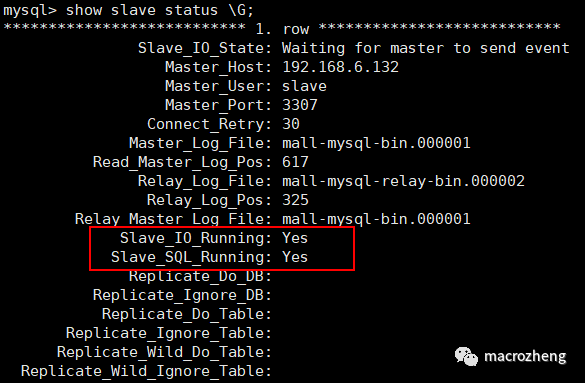
主从复制测试
主从复制的测试方法有很多,可以在主实例中创建一个数据库,看看从实例中是否有该数据库,如果有,表示主从复制已经搭建成功。
3、读写分离
主服务器处理写操作以及实时性要求比较高的读操作,而从服务器处理读操作。
读写分离能提高性能的原因在于:
- 主从服务器负责各自的读和写,极大程度缓解了锁的争用;
- 从服务器可以使用 MyISAM,提升查询性能以及节约系统开销;
- 增加冗余,提高可用性。
读写分离常用代理方式来实现,代理服务器接收应用层传来的读写请求,然后决定转发到哪个服务器。