MySQL-性能优化
1、查询性能优化
查看执行频次
sql 客户端连接成功后,通过show [session|global] status 命令可以提供服务器状态信息,通过如下指令可以查看数据的INSERT,UPDATE,DELETE,SELECT 的访问频次
SHOW GLOBAL STATUS LIKE 'Com_______';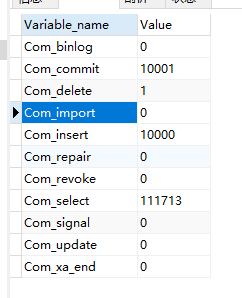
慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL 语句的日志。
sql 的慢查询日志默认没有开启,需要在sql 的配置文件(/etc/my.cnf)中配置如下信息:
# 开启慢查询日志开关
slow_query_log=1
# 设置慢查询日志时间为2秒
long_query_time=2配置完毕之后,重启sql 服务器,查看慢日志文件中的记录信息 /var/lib/sql/localhost-slow.log。
# Time 2022-03-05T15:45:39.688679Z
# User@Host: root[root] @ locahost [] Id: 8
# Query_time: 13.350650 Lock_time 0.000358 Rows_sent: 1 Rows_examined: 0
use xxx;
SET timestamp=1635435926;
select count(1) from user_operation_log;show profiles
show profile能够在做SQL优化是帮助我们了解时间都消耗到哪里去了,通过have_profiling 参数,能够看到当前sql 是否支持profile操作
select @@have_profiling;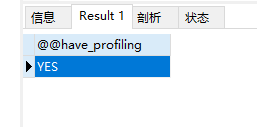
默认profiling 是关闭的 (select @@profiling),可以通过set 语句在session/global 级别开启profiling:
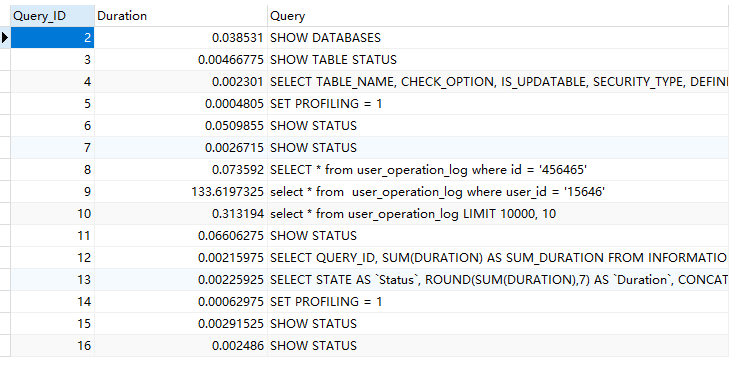
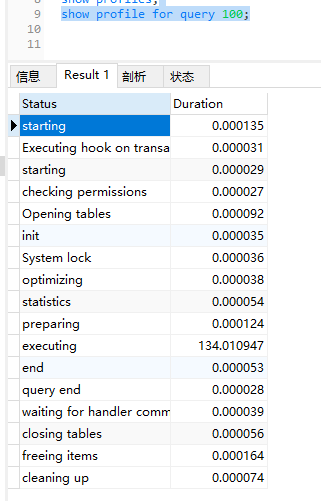
SET profiling = 1;执行一系列的业务SQL的操作,然后通过如下指令查看SQL 的执行耗时
-- 查看每一条SQL的耗时情况
show profiles;
-- 查看指定Query_id的SQL语句各个阶段的耗时情况
show profile for query query_id;
-- 查看query_id的SQL cpu使用情况
show profile cpu for query query_id;执行了3条SQL
SELECT * from user_operation_log where id = '456465';
select * from user_operation_log where user_id = '15646';
select * from user_operation_log LIMIT 10000, 10;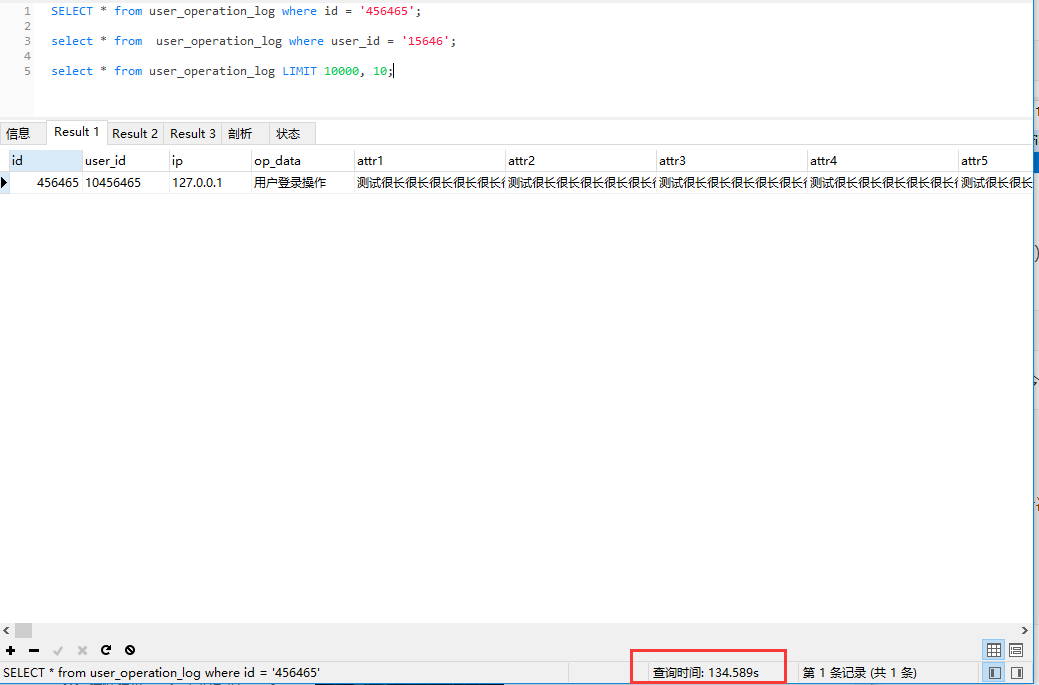
trace
trace 分析优化器如何选择执行计划,通过 trace 文件能够进一步了解为什么优惠券选择 A 执行计划而不选择 B 执行计划。
set optimizer_trace="enabled=on";
set optimizer_trace_max_mem_size=1000000;
select * from information_schema.optimizer_trace;explain 执行计划
详见
sql官方文档 :https://dev.sql.com/doc/refman/5.7/en/explain-output.html#jointype_index_merge
EXPLAIN 或者 DESC 命令获取sql 如何语句的信息,包括在SELECT 语句执行过程中表如何连接和连接顺序
-- 在SQL语句前加上关键字 EXPLAIN
EXPLAIN SELECT col0,clo1,... from table_name WHERE condition;
当Explain 与 SQL语句一起使用时,sql 会显示来自优化器关于SQL执行的信息。也就是说,sql解释了它将如何处理该语句,包括如何连接表以及什么顺序连接表等。
- 表的加载顺序
sql的查询类型- 可能用到哪些索引,哪些索引又被实际使用
- 表与表之间的引用关系
- 一个表中有多少行被优化器查询
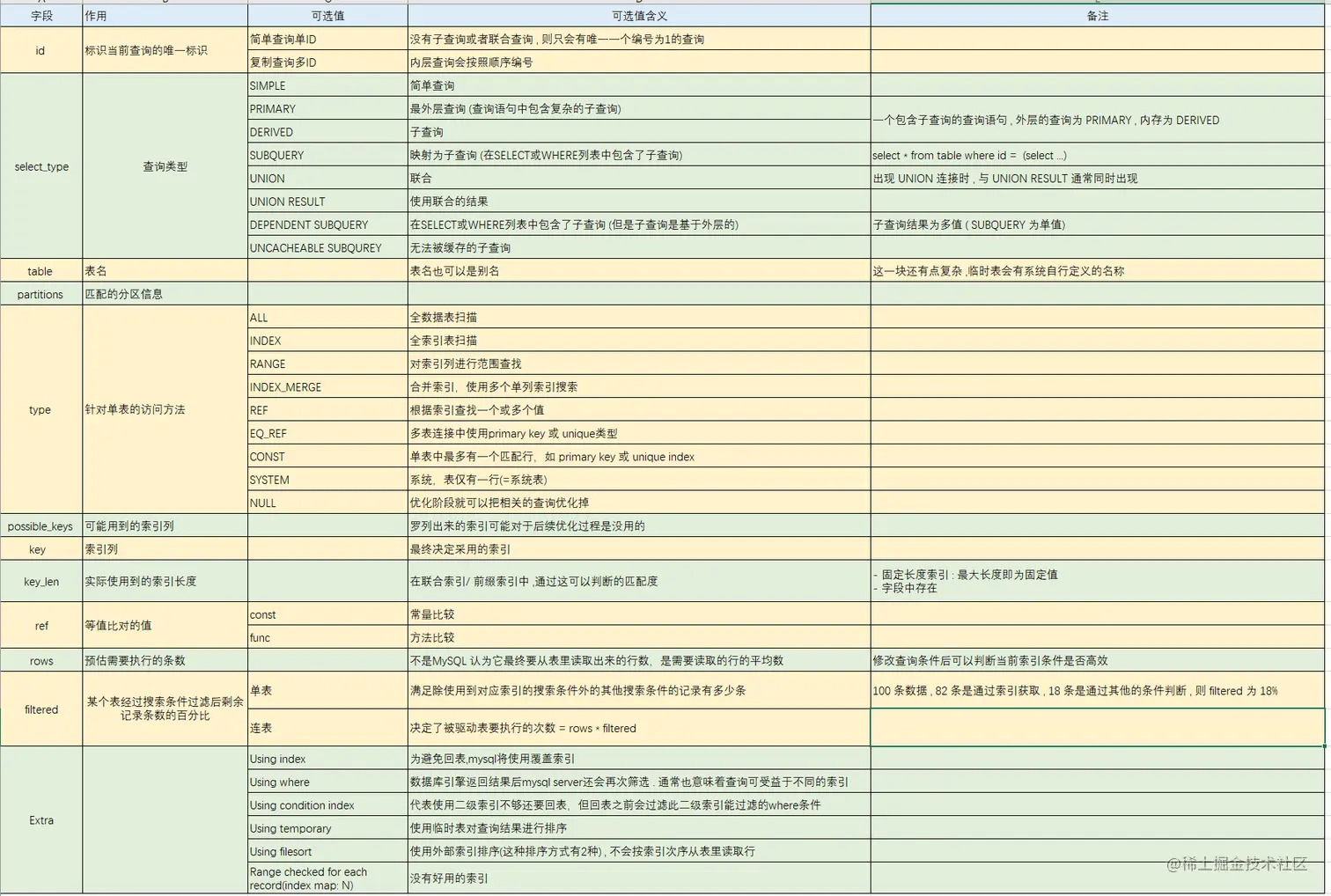
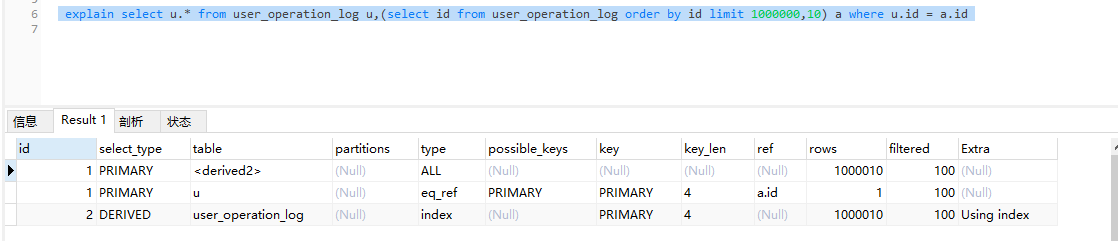
Explain 执行计划包含字段信息如下:分别是
id、select_type、table、partitions、type、possible_keys、key、key_len、ref、rows、filtered、Extra 12个字段。
1.id 执行顺序
id: :表示查询中执行select子句或者操作表的顺序,id的值越大,代表优先级越高,越先执行。id大致会出现 3种情况:
id相同
看到三条记录的id都相同,可以理解成这三个表为一组,具有同样的优先级,执行顺序由上而下,具体顺序由优化器决定。
id不同
如果我们的 SQL 中存在子查询,那么 id的序号会递增,id值越大优先级越高,越先被执行 。当三个表依次嵌套,发现最里层的子查询 id最大,最先执行。
以上两种同时存在
相同id划分为一组,这样就有三个组,同组的从上往下顺序执行,不同组 id值越大,优先级越高,越先执行。
2.select_type 查询类型
select_type:表示select查询的类型,主要是用于区分各种复杂的查询,例如:普通查询、联合查询、子查询等。
SIMPLE
表示最简单的 select 查询语句,也就是在查询中不包含子查询或者 union交并差集等操作。
PRIMARY
当查询语句中包含任何复杂的子部分,最外层查询则被标记为PRIMARY。
SUBQUERY
当 select 或 where 列表中包含了子查询,该子查询被标记为:SUBQUERY 。
DERIVED
表示包含在from子句中的子查询的select,在我们的 from 列表中包含的子查询会被标记为derived 。
UNION
如果union后边又出现的select 语句,则会被标记为union;若 union 包含在 from 子句的子查询中,外层 select 将被标记为 derived。
UNION RESULT
代表从union的临时表中读取数据
3.table 查询表名
查询的表名,并不一定是真实存在的表,有别名显示别名,也可能为临时表
4.partitions 分区信息
查询时匹配到的分区信息,对于非分区表值为
NULL,当查询的是分区表时,partitions显示分区表命中的分区情况。
5.type 索引查询类型
由上至下,效率越来越高
- ALL 全表扫描
- index 索引全扫描
- range 索引范围扫描,常用语<,<=,>=,between,in等操作
- ref 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中
- eq_ref 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
- const/system 单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询
- null sql不访问任何表或索引,直接返回结果
经常用到的索引查询类型
- const:使用主键或者唯一索引进行查询的时候只有一行匹配
- ref:使用非唯一索引
- range:使用主键、单个字段的辅助索引、多个字段的辅助索引的最后一个字段进行范围查询
- index:和all的区别是扫描的是索引树
- all:扫描全表
system
触发条件:表只有一行,这是一个 const type 的特殊情况
const
触发条件:在使用主键或者唯一索引进行查询的时候只有一行匹配。
eq_ref
触发条件:在进行联接查询的,使用主键或者唯一索引并且只匹配到一行记录的时候
ref
区别于
eq_ref,ref表示使用非唯一性索引,会找到很多个符合条件的行。触发条件:使用非唯一索引
ref_or_null
这种连接类型类似于 ref,区别在于
sql会额外搜索包含NULL值的行。
index_merge
index_merge:使用了索引合并优化方法,查询使用了两个以上的索引。
unique_subquery
unique_subquery:替换下面的IN子查询,子查询返回不重复的集合。sqlvalue IN (SELECT primary_key FROM single_table WHERE some_expr)
index_subquery
index_subquery:区别于unique_subquery,用于非唯一索引,可以返回重复值。sqlvalue IN (SELECT key_column FROM single_table WHERE some_expr)
range
触发条件:只有在使用 主键、单个字段的辅助索引、多个字段的辅助索引的最后一个字段 进行范围查询 才是 range
使用索引选择行,仅检索给定范围内的行。简单点说就是针对一个有索引的字段,给定范围检索数据。在
where语句中使用bettween...and、<、>、<=、in等条件查询type都是range。
index
触发条件:只扫描索引树
1)查询的字段是索引的一部分,覆盖索引。
2)使用主键进行排序
ALL
触发条件:全表扫描,不走索引
6.possible_keys 可能索引
possible_keys:表示在sql中通过哪些索引,能让我们在表中找到想要的记录,一旦查询涉及到的某个字段上存在索引,则索引将被列出,但这个索引并不定一会是最终查询数据时所被用到的索引。
7.key 实际索引
key:区别于possible_keys,key是查询中实际使用到的索引,若没有使用索引,显示为NULL。当
type为index_merge时,可能会显示多个索引。
8.key_len 索引长度
key_len:表示查询用到的索引长度(字节数),原则上长度越短越好 。
- 单列索引,那么需要将整个索引长度算进去;
- 多列索引,不是所有列都能用到,需要计算查询中实际用到的列。
注意:
key_len只计算where条件中用到的索引长度,而排序和分组即便是用到了索引,也不会计算到key_len中。
9.ref 关联字段名
ref:常见的有:const,func,null,字段名。
- 当使用常量等值查询,显示
const,- 当关联查询时,会显示相应关联表的
关联字段- 如果查询条件使用了
表达式、函数,或者条件列发生内部隐式转换,可能显示为func- 其他情况
null
10.rows 读取行数
rows:以表的统计信息和索引使用情况,估算要找到我们所需的记录,需要读取的行数。这是评估
SQL性能的一个比较重要的数据,sql需要扫描的行数,很直观的显示SQL性能的好坏,一般情况下rows值越小越好。
11.filtered 记录数百分比
filtered这个是一个百分比的值,表里符合条件的记录数的百分比。这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例.在sql5.7以前版本想要显示filtered需要使用explain extended命令。sql.5.7后,默认explain直接显示partitions和filtered的信息
12.Extra 额外信息
Using index
Using index:我们在相应的select操作中使用了覆盖索引,通俗一点讲就是查询的列被索引覆盖,使用到覆盖索引查询速度会非常快,SQl优化中理想的状态。
Using index condition
**Using index condition:**sql5.6 之后新增的 ICP,using index condtion 就是可能使用了 ICP(索引下推)
在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据。
Using where
Using where:查询时未找到可用的索引,进而通过where条件过滤获取所需数据,但要注意的是并不是所有带where语句的查询都会显示Using where。下边示例
create_time并未用到索引,type为ALL,即sql通过全表扫描后再按where条件筛选数据。sql> EXPLAIN SELECT one_name from one where create_time ='2020-05-18';
Using temporary
Using temporary:表示查询后结果需要使用临时表来存储,一般在排序或者分组查询时用到。性能很差,需要重点优化sql> EXPLAIN SELECT one_name from one where one_id in (1,2) group by one_name;
Using filesort
Using filesort:表示无法利用索引完成的排序操作,也就是ORDER BY的字段没有索引,性能较差,通常这样的SQL都是需要优化的。sql> EXPLAIN SELECT one_id from one ORDER BY create_time;如果
ORDER BY字段有索引就会用到覆盖索引,相比执行速度快很多。sql> EXPLAIN SELECT one_id from one ORDER BY one_id;
Using join buffer
Using join buffer:在我们联表查询的时候,如果表的连接条件没有用到索引,需要有一个连接缓冲区来存储中间结果。
Impossible where
Impossible where:表示在我们用不太正确的where语句,导致没有符合条件的行。sql> EXPLAIN SELECT one_name from one WHERE 1=2;
No tables used
No tables used:我们的查询语句中没有FROM子句,或者有FROM DUAL子句。sql> EXPLAIN select now();
| 列 | 含义 |
|---|---|
| id | select 查询的序号,表示查询中的执行select 子句或者操作表的顺序(id相同,顺序从上到下,id 不同值越大越先执行) |
| select_type | 表示 SELECT 的类型,常见的取值有 SIMPLE (简单表,不使用表连接和子查询),PRIMIAY(主查询,即外层的查询),UNION ,SUBQUERY (select/where 之后包含了子查询)等 |
| table | |
| partitions | |
| type | 表示连接的类型,性能由好到差的连接类型为 NULL,system,const,eq_ref,ref,range,index,all |
| possible_keys | 可能用到的索引 |
| key | 实际用到的索引 |
| key_len | 表示索引使用的字节数 |
| ref | |
| rows | 查询预估值 |
| filtered | 返回结果占读取行数的百分比,越大越好 |
| Extra | 额外信息 |
优化数据访问
减少请求的数据量
- 只返回必要的列:最好不要使用 SELECT * 语句。
- 只返回必要的行:使用 LIMIT 语句来限制返回的数据。
- 缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
重构查询方式
切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
sqlDELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH); ----------> rows_affected = 0 do { rows_affected = do_query( "DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH) LIMIT 10000") } while rows_affected > 0分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
- 让缓存更高效。对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
- 分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
- 减少锁竞争;
- 在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
- 查询本身效率也可能会有所提升。
2、SQL优化
插入数据
批量操作
2-1000条
insert into emp (1, '1', '柳岩', '女', 20, '123456789012345678', '北京', '2000-01-01'),
(2, '2', '张无忌', '男', 18, '123456789012345670', '北京', '2005-09-01');手动提交事务
start transaction;
insert ....
commit;如果一次性涉及大批量数据,insert 语句性能较低,此时可以使用sql 的load 指令进行插入
# 客户端连接服务器时,加上参数,--local-infile
sql --local-infile -uroot -p
# 设置全局参数local-infile 为1 开启从本地加载文件导入数据的开关
set global local_infile = 1;
# 执行load 指令将准备好的数据,加载到表结构当中
load data local file '/home/xxx.log' into table 'xxx' fields terminated by ',' lines terminated '\n';主键优化
在InnoDB 存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(Index Organized Table IOT)。
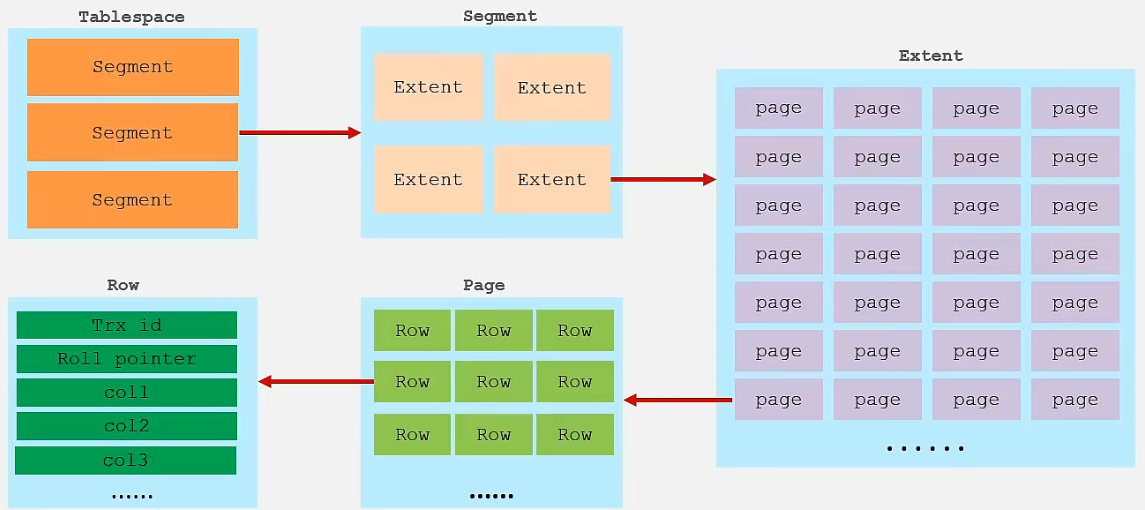
一个Page 默认是16K ,一个Extent 是固定的,是1M。一个Page 是InnoDB 磁盘管理的最小单元。
页分裂
页可以为空,也可以填充一半,也可以填充满。每个页包含了2-N行数据(如果一行数据过大,会行溢出),根据主键排序。
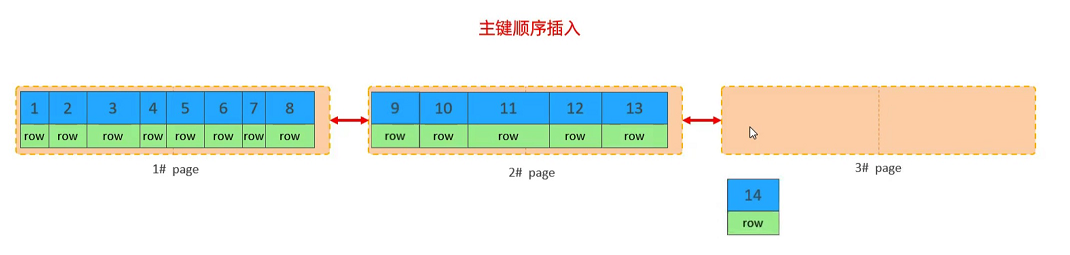
首先会新获取一个page, 将page 页的50%之后的数据,迁移到新开辟的页面,就新数据50插入到新页面,然后重新设置页的表指针。这个操作成为页分裂。
页合并
当删除一行记录时,实际上记录并没有被物理删除,而是被标记(flaged)为删除并且它的空间变得被其他记录声明使用。当页中删除的记录达到MERGE_THREADSHOLD(默认页的50%),InnoDB 会开始寻找最靠近的页看看是否可以将2个页合并优化空间使用。

MERGE_THREADSHOLD:合并页的阈值,可以自己设置,在创建表或者创建索引时指定。
主键设计原则
- 满足业务需求的情况下,尽量降低主键的长度(二级索引存储聚集索引的值)。
- 插入数据时,尽量选择顺序插入,选择AUTO_INCREMENT 自增主键。
- 尽量不要使用UUID 做主键或者是其他自然主键。
- 业务操作时,避免对主键的修改。
order by 优化
- using filesort : 通过表的索引或者扫描权标,读取满足条件的数据行,然后在排序缓冲区sort buffer 中完成排序操作,所有不是通过索引直接返回排序结果的排序都是 FileSort 排序。
- using index : 通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。
将emp中的idcard索引删除。
-- 删除索引
DROP INDEX idx_id_card ON emp;
EXPLAIN select * FROM `emp` order by idcard;
explain select id, workno, age,idcard from emp order by workno desc, age desc ,idcard desc;
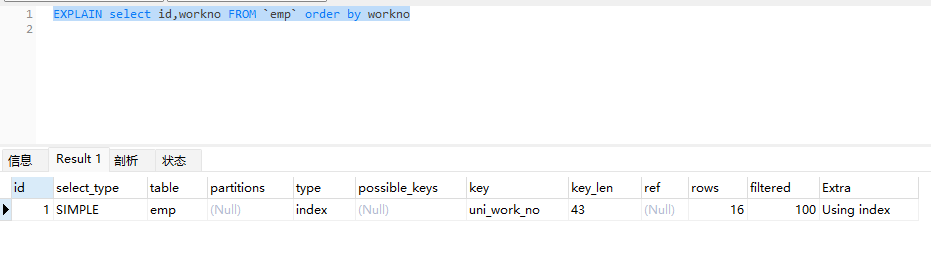

然而根据最左原则,排序字段应该也要跟着索引指定的字段顺序进行排序

当select 字段不出现在索引中,需要回表操作,此时,缓冲区会用filesort 进行排序。
小结
- 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
- 尽量使用覆盖索引。
- 多字段排序,一个升序,一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC )。
- 如果不可避免的出现filesort,大数据量排序,可适当增大排序缓冲区大小 sort_buffer_size(默认256k)。
group by 优化
先删除表上其他索引
drop index xxx on TABLE;
explain select workaddress,count(1) from emp group by workaddress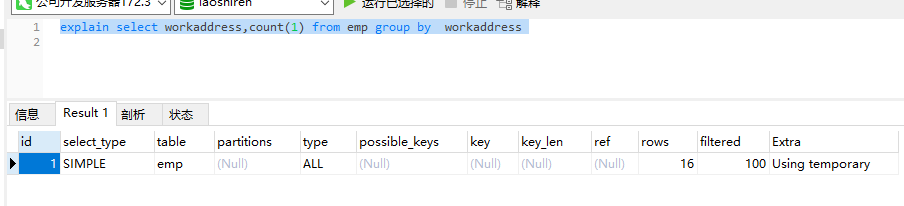
Using temporary使用临时表性能非常低。
-- 创建一个联合索引
create index idx_add_gender on emp(workaddress,gender);
explain select workaddress,count(1) from emp group by workaddress
当group by 不满足最左前缀法则,则用不到索引,先会使用临时表。
当查询涉及如上的查询,在查询条件添加where 条件且刚好满足最左原则则查询可以使用索引。

分组操作时,索引的适合用也是尽可能满足最左前缀法则。
limit 优化
user_operation_log这张表有1000w的数据。
select * from user_operation_log limit 1000000,10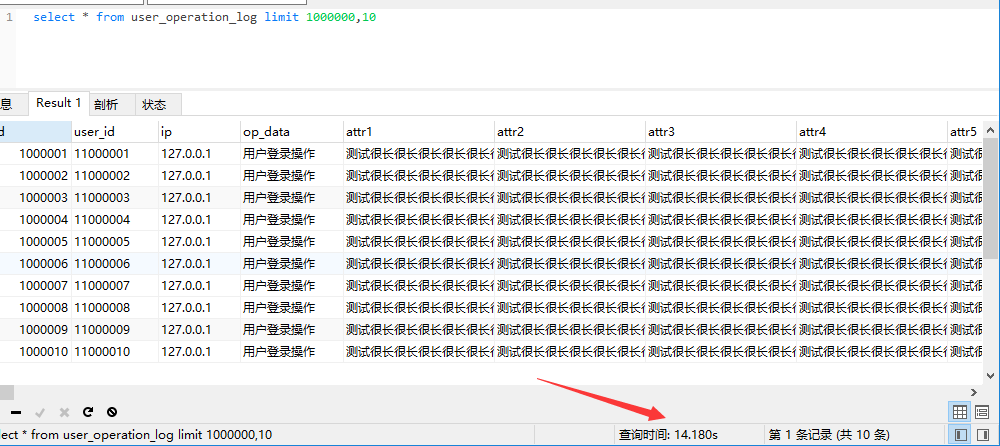
时长显然是不可接受的。在对于limit 来说,大数据量的情况下,越往后效率越低,耗时越长。sql需要排序前N 条记录,仅仅返回N-(N+n)条记录,其他记录设计,查询排序的代价非常大。
官方推荐使用覆盖索引加子查询的方式。
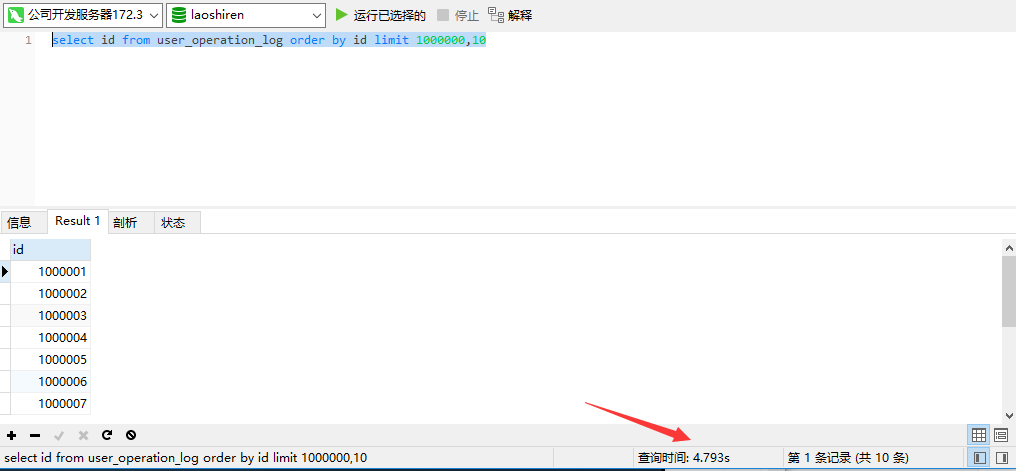
sql 不支持此类语法 select * from user_operation_log where id in (select id from user_operation_log order by id limit 1000000,10)limit,所以要修改写法。
select * from user_operation_log u,(select id from user_operation_log order by id limit 1000000,10) a where u.id = a.id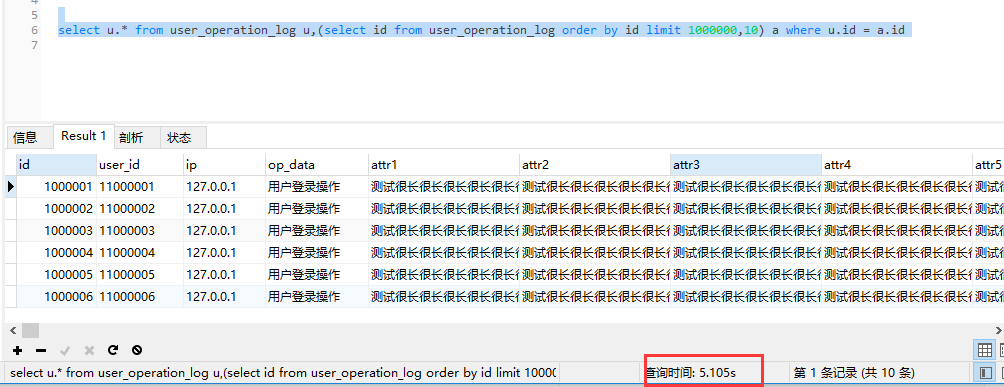
count 优化
MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高。而在InnoDB 引擎就麻烦了,他执行count(*)的时候,需要把数据一行一行地从引擎里读,然后累积计数。
count
count()是一个聚合函数,对于返回的结果集,一行行地判断,如果count() 函数的参数不是NULL 就累加1,否则不加,最后返回累计值。
InnoDB 在count(主键)时,会遍历整张表,把每一行的主键ID的值都取出来,返回给服务层。服务层拿到主键后,直接进行累加(主键不可能为null)。
count(1),遍历整张表,不取值,对于返回的每一层,放一个数字1,进行累加。
count(*),InnoDB引擎不会把全部字段取出来,而是专门做了优化,直接按行进行累加。
按照效率 count(字段)< count(pk)< count(1)≈count(*)
update 优化
update 时候尽量使用ID作为条件更新,不然update 会因为没有索引,从而将行锁升级为表锁。InnoDB 的行锁只针对索引加的锁,不是针对记录加的锁,并且索引不能失效,否则会从行锁升级为表锁。