如何做好性能优化
1.索引
通过查看线上日志或者监控报告,查到某个接口用到的某条sql语句耗时比较长。
这时可能会有下面这些疑问:
- 该sql语句加索引了没?
- 加的索引生效了没?
- mysql选错索引了没?
1.1 没加索引
sql语句中
where条件的关键字段,或者order by后面的排序字段,忘了加索引,这个问题在项目中很常见。项目刚开始的时候,由于表中的数据量小,加不加索引sql查询性能差别不大。
后来,随着业务的发展,表中数据量越来越多,就不得不加索引了。
可以通过命令:能单独查看某张表的索引情况。
sqlshow index from `order`;也可以通过命令:查看整张表的建表语句,里面同样会显示索引情况
sqlshow create table `order`;添加索引:
sqlALTER TABLE `order` ADD INDEX idx_name (name); #通过ALTER TABLE命令可以添加索引 CREATE INDEX idx_name ON `order` (name); #通过CREATE INDEX命令添加索引tips:目前在mysql中如果想要通过命令修改索引,只能先删除索引,再重新添加新的。
1.2 索引没生效
使用
explain命令,查看mysql的执行计划,它会显示索引的使用情况。
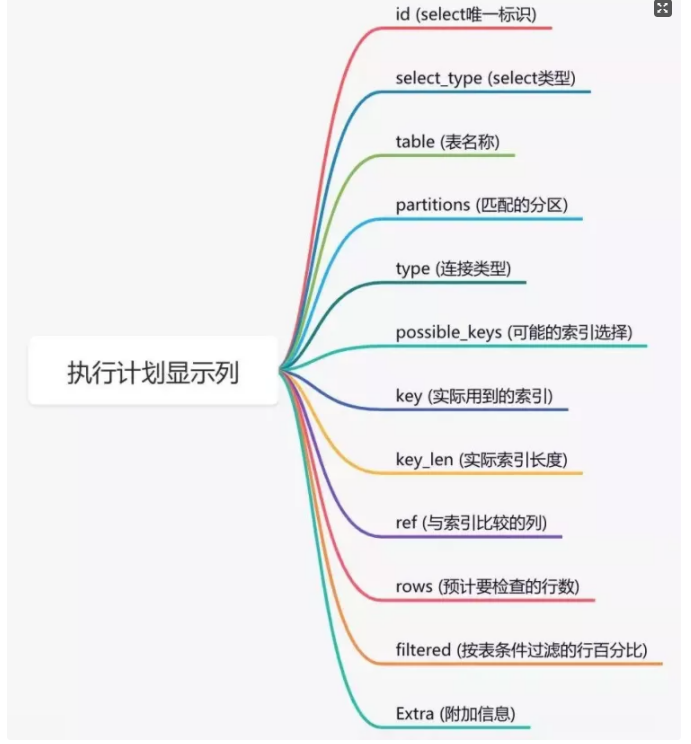
1.3 选错索引
mysql会选错索引。
必要时可以使用
force index来强制查询sql走某个索引。
2.SQL优化
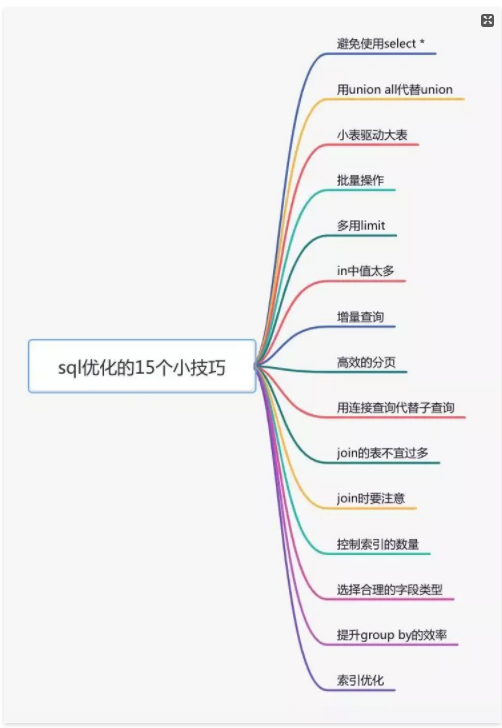
3.远程调用
串行调用远程接口性能是非常不好的,调用远程接口总的耗时为所有的远程接口耗时之和。
优化远程接口性能
3.1 并行调用
在java8之前可以通过实现
Callable接口,获取线程返回结果。java8以后通过
CompleteFuture类实现该功能。这里以CompleteFuture为例:
3.2 数据异构
在高并发的场景下,为了提升接口性能,远程接口调用大概率会被去掉,而改成保存冗余数据的数据异构方案
但需要注意的是,如果使用了数据异构方案,就可能会出现数据一致性问题。
4.重复调用
4.1 循环查数据库
提供一个根据用户id集合批量查询用户的接口,只远程调用一次,就能查询出所有的数据。
这里有个需要注意的地方是:id集合的大小要做限制,最好一次不要请求太多的数据。要根据实际情况而定,建议控制每次请求的记录条数在500以内
4.2 死循环
4.3 无限递归
建议写递归方法时,设定一个递归的深度,比如:分类最大等级有4级,则深度可以设置为4。然后在递归方法中做判断,如果深度大于4时,则自动返回,这样就能避免无限循环的情况。
5.异步处理
核心逻辑可以同步执行,同步写库。非核心逻辑,可以异步执行,异步写库。
5.1 线程池
使用线程池有个小问题就是:如果服务器重启了,或者是需要被执行的功能出现异常了,无法重试,会丢数据。
5.2 mq
发送了mq消息到mq服务器。然后由mq消费者消费消息
6.避免大事务
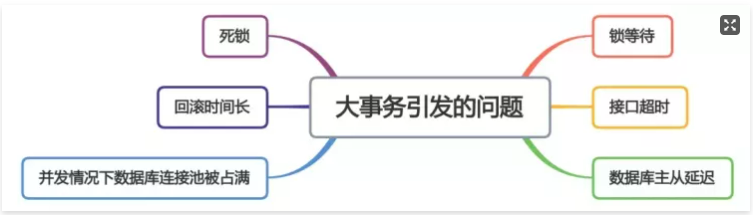
从图中能够看出,大事务问题可能会造成接口超时,对接口的性能有直接的影响。
该如何优化大事务呢?
少用
@Transactional注解将查询(select)方法放到事务外
事务中避免远程调用
事务中避免一次性处理太多数据
有些功能可以非事务执行
有些功能可以异步处理
7.锁粒度
在某些业务场景中,为了防止多个线程并发修改某个共享数据,造成数据异常。
为了解决并发场景下,多个线程同时修改数据,造成数据不一致的情况。通常情况下,会:加锁。
但如果锁加得不好,导致锁的粒度太粗,也会非常影响接口性能。
7.1 synchronized
在方法上加锁 (锁的粒度有点粗)和 在代码块上加锁(锁的粒度变小)。
synchronized只能保证一个节点加锁是有效的,但如果有多个节点如何加锁呢?
7.2 redis分布式锁
7.3 数据库分布式锁
mysql数据库中主要有三种锁:
表锁:加锁快,不会出现死锁。但锁定粒度大,发生锁冲突的概率最高,并发度最低。
行锁:加锁慢,会出现死锁。但锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
间隙锁:开销和加锁时间界于表锁和行锁之间。它会出现死锁,锁定粒度界于表锁和行锁之间,并发度一般。
并发度越高,意味着接口性能越好。
所以数据库锁的优化方向是:
优先使用行锁,其次使用间隙锁,再其次使用表锁。
8.分页处理
8.1 同步调用
8.2 异步调用
使用
CompletableFuture类,多个线程异步调用远程接口,最后汇总结果统一返回
9.加缓存
解决接口性能问题,加缓存是一个非常高效的方法。
但不能为了缓存而缓存,还是要看具体的业务场景。毕竟加了缓存,会导致接口的复杂度增加,它会带来数据不一致问题。
9.1 redis缓存
9.2 二级缓存
基于内存的缓存
实现参考
caffeine
10.分库分表
路由的算法挺多的:
根据id取模,比如:id=7,有4张表,则7%4=3,模为3,路由到用户表3。
给id指定一个区间范围,比如:id的值是0-10万,则数据存在用户表0,id的值是10-20万,则数据存在用户表1。
一致性hash算法
分库分表主要有两个方向:垂直和水平。
说实话垂直方向(即业务方向)更简单。
在水平方向(即数据方向)上,分库和分表的作用,其实是有区别的,不能混为一谈。
分库:是为了解决数据库连接资源不足问题,和磁盘IO的性能瓶颈问题。
分表:是为了解决单表数据量太大,sql语句查询数据时,即使走了索引也非常耗时问题。此外还可以解决消耗cpu资源问题。
分库分表:可以解决 数据库连接资源不足、磁盘IO的性能瓶颈、检索数据耗时 和 消耗cpu资源等问题。
如果在有些业务场景中,用户并发量很大,但是需要保存的数据量很少,这时可以只分库,不分表。
如果在有些业务场景中,用户并发量不大,但是需要保存的数量很多,这时可以只分表,不分库。
如果在有些业务场景中,用户并发量大,并且需要保存的数量也很多时,可以分库分表。
11.辅助功能
11.1 开启慢查询日志
通常情况下,为了定位sql的性能瓶颈,需要开启mysql的慢查询日志。把超过指定时间的sql语句,单独记录下来,方面以后分析和定位问题。
开启慢查询日志需要重点关注三个参数:
slow_query_log慢查询开关
slow_query_log_file慢查询日志存放的路径
long_query_time超过多少秒才会记录日志通过mysql的
set命令可以设置:sqlset global slow_query_log='ON'; set global slow_query_log_file='/usr/local/mysql/data/slow.log'; set global long_query_time=2;设置完之后,如果某条sql的执行时间超过了2秒,会被自动记录到slow.log文件中。
当然也可以直接修改配置文件my.cnf (需要重启mysql服务)
sql[mysqld] slow_query_log = ON slow_query_log_file = /usr/local/mysql/data/slow.log long_query_time = 2
11.2 监控
Prometheus
官方文档: https://prometheus.io/
可以用它监控如下信息:
接口响应时间
调用第三方服务耗时
慢查询sql耗时
cpu使用情况
内存使用情况
磁盘使用情况
数据库使用情况
11.3 链路跟踪
skywalking
官网:https://skywalking.apache.org/
skywalking中可以通过
traceId(全局唯一的id),串联一个接口请求的完整链路。