Java基础
1、数据类型
Java语言数据类型分为两种:基本数据类型和引用数据类型。
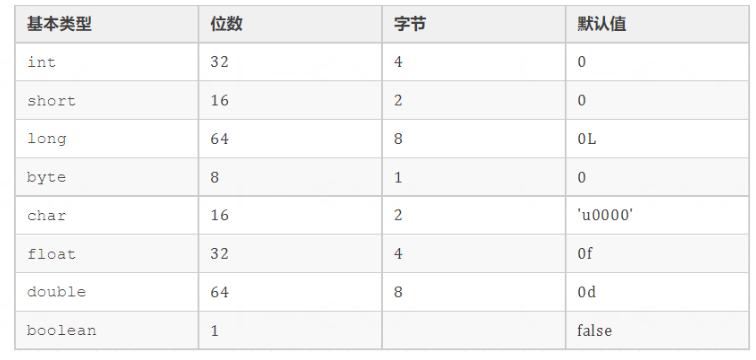
1.1、基本数据类型
- 数值型
- 整数类型(byte、short、long)
- 浮点类型(float、long)
- 字符型(char)
- 布尔型(boolean)
1.2、引用数据类型
- 类(class)
- 接口(interface)
- 数组([])
1.3、类型转换
1.3.1、自动&强制类型转换
Java 所有的数值型变量可以相互转换,当把一个表数范围小的数值或变量直接赋给另一个表数范围大的变量时,可以进行自动类型转换;反之,需要强制转换(有溢出的风险)。
float f=3.4,对吗?
不正确。3.4 是单精度数,将双精度型(double)赋值给浮点型(float)属于下转型(down-casting,也称为窄化)会造成精度损失,因此需要强制类型转换float f =(float)3.4;或者写成float f =3.4F
short s1 = 1; s1 = s1 + 1;对吗?short s1 = 1; s1 += 1;对吗?
对于 short s1 = 1; s1 = s1 + 1;编译出错,由于 1 是 int 类型,因此 s1+1 运算结果也是 int型,需要强制转换类型才能赋值给 short 型。
而 short s1 = 1; s1 += 1;可以正确编译,因为 s1+= 1;相当于 s1 = (short(s1 + 1);其中有隐含的强制类型转换。
1.3.2、自动装箱&拆箱
- 装箱:将基本类型用它们对应的引用类型包装起来;
- 拆箱:将包装类型转换为基本数据类型;
2、基础语法
break ,continue ,return 的区别及作用?
break 跳出整个循环,不再执行循环(结束当前的循环体)
continue 跳出本次循环,继续执行下次循环(结束正在执行的循环 进入下一个循环条件)
return 程序返回,不再执行下面的代码(结束当前的方法 直接返回)
面向对象有哪些特性
封装
封装把⼀个对象的属性私有化,同时提供⼀些可以被外界访问的属性的⽅法。
继承
继承是使⽤已存在的类的定义作为基础创建新的类,新类的定义可以增加新的属性或新的方法,也可以继承父类的属性和方法。通过继承可以很方便地进行代码复用。
关于继承有以下三个要点:
- ⼦类拥有⽗类对象所有的属性和⽅法(包括私有属性和私有⽅法),但是⽗类中的私有属性和⽅法⼦类是⽆法访问,只是拥有。
- ⼦类可以拥有⾃⼰属性和⽅法,即⼦类可以对⽗类进⾏扩展。
- ⼦类可以⽤⾃⼰的⽅式实现⽗类的⽅法。
多态
所谓多态就是指程序中定义的引⽤变量所指向的具体类型和通过该引⽤变量发出的⽅法调⽤在编程时并不确定,⽽是在程序运⾏期间才确定,即⼀个引⽤变量到底会指向哪个类的实例对象,该引⽤变量发出的⽅法调⽤到底是哪个类中实现的⽅法,必须在由程序运⾏期间才能决定。
在 Java 中有两种形式可以实现多态:继承(多个⼦类对同⼀⽅法的重写)和接⼝(实现接⼝并覆盖接⼝中同⼀⽅法)。
重载(overload)和重写(override)的区别
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。
- 重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载;
- 重写发生在子类与父类之间,重写要求子类被重写方法与父类被重写方法有相同的返回类型,比父类被重写方法更好访问,不能比父类被重写方法声明更多的异常(里氏代换原则)。
方法重载的规则:
- 方法名一致,参数列表中参数的顺序,类型,个数不同。
- 重载与方法的返回值无关,存在于父类和子类,同类中。
- 可以抛出不同的异常,可以有不同修饰符。
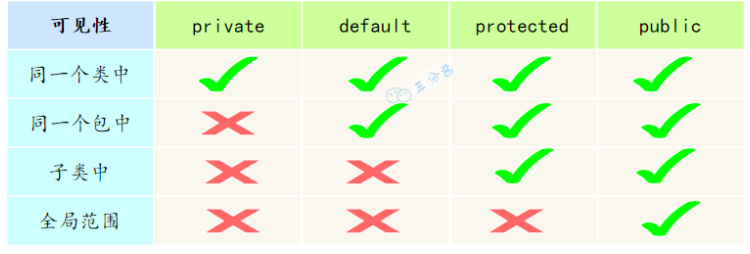
访问修饰符public、private、protected、以及不写(默认)时的区别
- default (即默认,什么也不写): 在同一包内可见,不使用任何修饰符。可以修饰在类、接口、变量、方法。
- private : 在同一类内可见。可以修饰变量、方法。注意:不能修饰类(外部类)
- public : 对所有类可见。可以修饰类、接口、变量、方法
- protected : 对同一包内的类和所有子类可见。可以修饰变量、方法。注意:不能修饰类(外部类)。
this关键字有什么作用
this是自身的一个对象,代表对象本身,可以理解为:指向对象本身的一个指针。
this的用法在Java中大体可以分为3种:
- 普通的直接引用,this相当于是指向当前对象本身
- 形参与成员变量名字重名,用this来区分:
- 引用本类的构造函数
final关键字有什么作用
final表示不可变的意思,可用于修饰类、属性和方法:
- 被final修饰的类不可以被继承
- 被final修饰的方法不可以被重写
- 被final修饰的变量不可变,被final修饰的变量必须被显式第指定初始值,还得注意的是,这里的不可变指的是变量的引用不可变,不是引用指向的内容的不可变。
抽象类(abstract class)和接口(interface)有什么区别
- 接⼝的⽅法默认是 public ,所有⽅法在接⼝中不能有实现(Java 8 开始接⼝⽅法可以有默认实现),⽽抽象类可以有⾮抽象的⽅法。
- 接⼝中除了 static 、 final 变量,不能有其他变量,⽽抽象类中则不⼀定。
- ⼀个类可以实现多个接⼝,但只能实现⼀个抽象类。接⼝⾃⼰本身可以通过 extends 关键字扩展多个接⼝。
- 接⼝⽅法默认修饰符是 public ,抽象⽅法可以有 public 、 protected 和 default 这些修饰符(抽象⽅法就是为了被重写所以不能使⽤ private 关键字修饰!)。
- 从设计层⾯来说,抽象是对类的抽象,是⼀种模板设计,⽽接⼝是对⾏为的抽象,是⼀种⾏为的规范。
- 在 JDK8 中,接⼝也可以定义静态⽅法,可以直接⽤接⼝名调⽤。实现类和实现是不可以调⽤的。如果同时实现两个接⼝,接⼝中定义了⼀样的默认⽅法,则必须重写,不然会报错。
- jdk9 的接⼝被允许定义私有⽅法 。
3、Java 泛型
3.1、泛型简述
泛型就是在定义类、接口、方法的时候指定某一种特定类型,让类、接口、方法的使用者来决定具体用哪一种类型的参数。Java的泛型是在1.5引入的,只在编译期做泛型检查,运行期泛型就会消失,我们把这称为“泛型擦除”,最终类型都会变成 Object。
//将Score转变为泛型类<T>
public class Score<T> {
String name;
String id;
//T为泛型,根据用户提供的类型自动变成对应类型
T score;
//提供的score类型即为T代表的类型
public Score(String name, String id, T score) {
this.name = name;
this.id = id;
this.score = score;
}
public static void main(String[] args) {
//直接确定Score的类型是字符串类型的成绩
Score<String> score = new Score<String>("数据结构与算法基础", "EP074512", "优秀");
//编译不通过,因为成员变量score类型被定为String!
Integer i = score.score;
}
}泛型将数据类型的确定控制在了编译阶段,在编写代码的时候就能明确泛型的类型!如果类型不符合,将无法通过编译!泛型本质上也是一个语法糖(并不是JVM所支持的语法,编译后会转成编译器支持的语法,比如之前的foreach就是),在编译后会被擦除,变回上面的Object类型调用,但是类型转换由编译器帮我们完成,而不是我们自己进行转换(安全)
3.2、泛型类
类上定义泛型,作用于类的成员变量与函数,代码实例如下
public class GenericClass<T> {
// 成员变量
private T t;
public void function(T t) {
}
public T function2(T t) {
return t;
}
}3.3、泛型接口
接口上定义泛型,作用于函数,代码实例如下
public interface GenericInterface<T> {
T get();
void set(T t);
T delete(T t);
default T defaultFunction(T t) {
return t;
}
}3.4、泛型函数
函数返回类型旁加上泛型,作用于函数,代码实例如下
public class GenericFunction {
public <T> void function(T t) {
}
public <T> T function2(T t) {
return t;
}
public <T> String function3(T t) {
return "";
}
}3.5、通配符
<?>:无界通配符,即类型不确定,任意类型<? extends T>:上边界通配符,即?是继承自T的任意子类型,遵守只读不写<? super T>:下边界通配符,即?是T的任意父类型,遵守只写不读
public static void main(String[] args) {
// 创建泛型为Number的List类,Integer、Double、Long等都是Number的子类
List<Number> numbers = new ArrayList<>();
// 添加Integer类型
numbers.add(1);
// 添加Double类型
numbers.add(0.5);
// 添加Long类型
numbers.add(100L);
// 编译错误
//List<Number> numbers2 = new ArrayList<Integer>();
}「通配符限定的范围是体现在确认“参数化类型”的时候,而不是“参数化类型”填充后」
<? extends T>上边界通配符不作为函数入参,只作为函数返回类型,比如List<? extends T>的使用add函数会编译不通过,get函数则没问题<? super T>下边界通配符不作为函数返回类型,只作为函数入参,比如List<? super T>的add函数正常调用,get函数也没问题,但只会返回Object,所以意义不大
最后总结一下,什么时候用通配符,如果参数泛型类即要读也要写,那么就不推荐使用,使用正常的泛型即可,如果参数泛型类只读或写,就可以根据原则采用对应的上下边界,是不是十分简单,最后再说一次读写的含义,这块确实很容易晕
- 读:所谓读是指参数泛型类,泛型只作为该参数类的函数返回类型,那这个函数就是读,
List作为参数泛型类,它的get函数就是读 - 写:所谓写是指参数泛型类,泛型只作为该参数类的函数入参,那这个函数就是写,
List作为参数泛型类,它的add函数就是读
泛型无法使用基本类型,如果需要基本类型,只能使用基本类型的包装类进行替换!
那么为什么泛型无法使用基本类型呢?由于JVM没有泛型概念,因此泛型最后还是会被编译器编译为Object,并采用强制类型转换的形式进行类型匹配,而我们的基本数据类型和引用类型之间无法进行类型转换,所以只能使用基本类型的包装类来处理。
3.6、泛型擦除
什么是泛型擦除?
Java 的泛型是伪泛型,这是因为 Java 在编译期间,所有的类型信息都会被擦掉。
也就是说,在运行的时候是没有泛型的。
因为Java的范型只存在于源码里,编译的时候给你静态地检查一下范型类型是否正确,而到了运行时就不检查了。
为什么要类型擦除呢?
主要是为了向下兼容,因为JDK5之前是没有泛型的,为了让JVM保持向下兼容,就出了类型擦除这个策略。
4、Java 反射
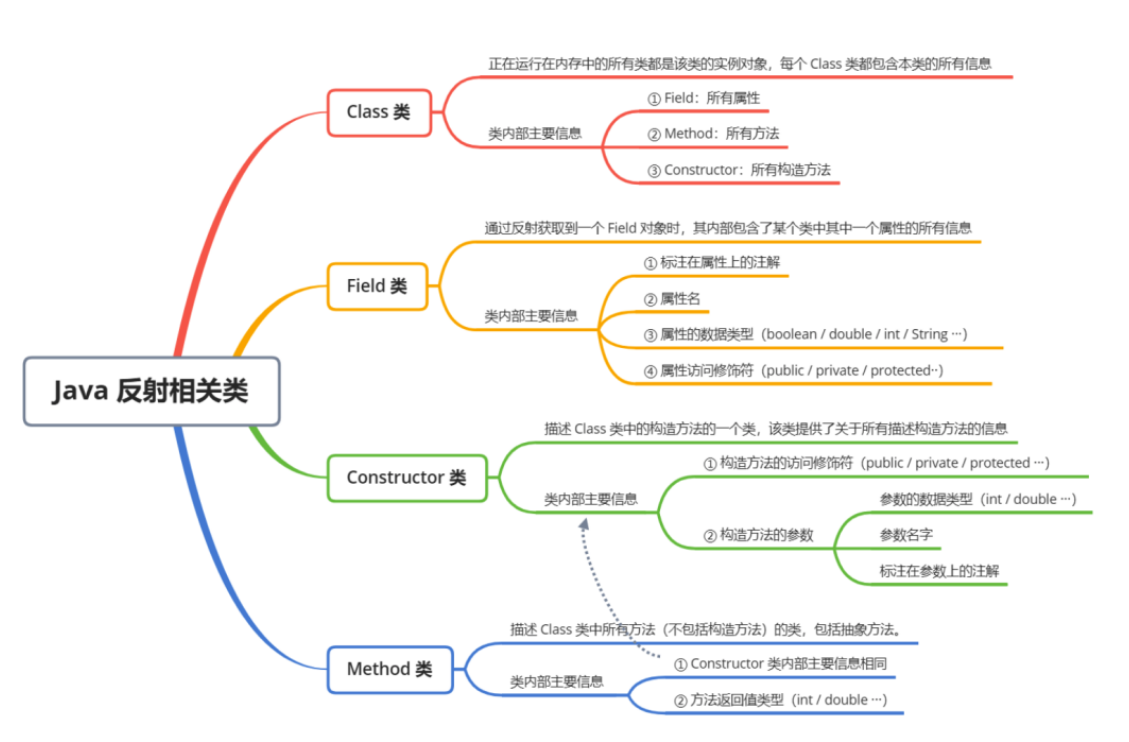
如何获取到每个类对应的Class对象?
- 使用class关键字,通过类名获取
- 使用Class类静态方法forName(),通过包名.类名获取,注意返回值是Class<?>
- 通过实例对象获取 对象.getClasss() ,返回值是Class<?>
public static void main(String[] args) throws ClassNotFoundException {
Class<String> clazz = String.class; //使用class关键字,通过类名获取
Class<?> clazz2 = Class.forName("java.lang.String"); //使用Class类静态方法forName(),通过包名.类名获取,注意返回值是Class<?>
Class<?> clazz3 = new String("cpdd").getClass(); //通过实例对象获取
// 实际上都和第一个返回的是同一个对象
System.out.println(clazz == clazz2);
System.out.println(clazz == clazz3);
}基本数据类型有Class对象吗?
实际上,基本数据类型也有对应的Class对象(反射操作可能需要用到),而且我们不仅可以通过class关键字获取,其实本质上是定义在对应的包装类中的:
/**
* The {@code Class} instance representing the primitive type
* {@code int}.
*
* @since JDK1.1
*/
@SuppressWarnings("unchecked")
public static final Class<Integer> TYPE = (Class<Integer>) Class.getPrimitiveClass("int");
/*
* Return the Virtual Machine's Class object for the named
* primitive type
*/
static native Class<?> getPrimitiveClass(String name); //C++实现,并非Java定义每个包装类中(包括Void),都有一个获取原始类型Class方法,注意,getPrimitiveClass获取的是原始类型,并不是包装类型,只是可以使用包装类来表示。
public static void main(String[] args) {
Class<?> clazz = int.class;
System.out.println(Integer.TYPE == int.class);
}通过对比,我们发现实际上包装类型都有一个TYPE,其实也就是基本类型的Class,那么包装类的Class和基本类的Class一样吗?
public static void main(String[] args) {
System.out.println(Integer.TYPE == Integer.class);
}我们发现,包装类型的Class对象并不是基本类型Class对象。数组类型也是一种类型,只是编程不可见,因此我们可以直接获取数组的Class对象:
public static void main(String[] args) {
Class<String[]> clazz = String[].class;
System.out.println(clazz.getName()); //获取类名称(得到的是包名+类名的完整名称)
System.out.println(clazz.getSimpleName());
System.out.println(clazz.getTypeName());
System.out.println(clazz.getClassLoader()); //获取它的类加载器
System.out.println(clazz.cast(new Integer("10"))); //强制类型转换
}Java类对象如何比较?
使用
instanceof进行类型比较javapublic static void main(String[] args) { String str = ""; System.out.println(str instanceof String); }判断一个对象是否为此接口或是类的实现或是子类
javapublic static void main(String[] args) { String str = ""; System.out.println(str.getClass() == String.class); //直接判断是否为这个类型 }需要判断是否为子类或是接口/抽象类的实现
javapublic static void main(String[] args) { Integer i = 10; // 当Integer不是Number的子类时,会产生异常 i.getClass().asSubclass(Number.class); }
如何获取一个类的父类信息?
通过getSuperclass()方法,我们可以获取到父类的Class对象:
public static void main(String[] args) {
Integer i = 10;
System.out.println(i.getClass().getSuperclass());
}也可以通过getGenericSuperclass()获取父类的原始类型的Type:
public static void main(String[] args) {
Integer i = 10;
Type type = i.getClass().getGenericSuperclass();
System.out.println(type);
System.out.println(type instanceof Class);
}我们发现Type实际上是Class类的父接口,但是获取到的Type的实现并不一定是Class。
同理,我们也可以像上面这样获取父接口:
public static void main(String[] args) {
Integer i = 10;
for (Class<?> anInterface : i.getClass().getInterfaces()) {
System.out.println(anInterface.getName());
}
for (Type genericInterface : i.getClass().getGenericInterfaces()) {
System.out.println(genericInterface.getTypeName());
}
}如何反射创建类对象?
通过使用
newInstance()方法来创建对应类型的实例,返回泛型Tjavapublic static void main(String[] args) throws Exception { Class<Student> clazz = Student.class; Student student = clazz.newInstance(); student.test(); } static class Student{ public void test(){ System.out.println("萨日朗"); } }注意它会抛出InstantiationException和IllegalAccessException异常:
- 当类默认的构造方法被带参构造覆盖时,会出现InstantiationException异常,因为
newInstance()只适用于默认无参构造。 - 当默认无参构造的权限不是
public时,会出现IllegalAccessException异常,表示我们无权去调用默认构造方法。
- 当类默认的构造方法被带参构造覆盖时,会出现InstantiationException异常,因为
通过获取构造器,来实例化对象
java//反射 Student student = clazz.getConstructor(String.class).newInstance("what's up"); //暴力反射 Constructor<Student> constructor = clazz.getDeclaredConstructor(String.class); constructor.setAccessible(true); //修改访问权限 Student student = constructor.newInstance("what's up");
如何反射调用类的方法?
// invoke()
// 通过方法名和形参类型获取类中的方法
Method method = clazz.getMethod("test", String.class);
// 通过Method对象的invoke方法来调用方法
method.invoke(instance, "what's up");
// 暴力反射
Method method = clazz.getDeclaredMethod("test", String.class);
method.setAccessible(true);
method.invoke(instance, "what's up");
// 当方法的参数为可变参数时
Method method = clazz.getDeclaredMethod("test", String[].class);
System.out.println(method.getName()); //获取方法名称
System.out.println(method.getReturnType()); //获取返回值类型如何修改类的属性?
通过反射访问一个类中定义的成员字段也可以修改一个类的对象中的成员字段值
public static void main(String[] args) throws ReflectiveOperationException {
Class<?> clazz = Class.forName("com.test.Student");
Object instance = clazz.newInstance();
Field field = clazz.getField("i"); //获取类的成员字段i
field.set(instance, 100); //将类实例instance的成员字段i设置为100
Method method = clazz.getMethod("test");
method.invoke(instance);
}在得到Field之后,我们就可以直接通过set()方法为某个对象,设定此属性的值,比如上面,我们就为instance对象设定值为100,当访问private字段时,同样可以按照上面的操作进行越权访问:
public static void main(String[] args) throws ReflectiveOperationException {
Class<?> clazz = Class.forName("com.test.Student");
Object instance = clazz.newInstance();
Field field = clazz.getDeclaredField("i"); //获取类的成员字段i
field.setAccessible(true);
field.set(instance, 100); //将类实例instance的成员字段i设置为100
Method method = clazz.getMethod("test");
method.invoke(instance);
}思考:如果字段被标记为final呢?
private final int i = 10public static void main(String[] args) throws ReflectiveOperationException {
Integer i = 10;
Field field = Integer.class.getDeclaredField("value");
// 这里要获取Field类的modifiers字段进行修改
Field modifiersField = Field.class.getDeclaredField("modifiers");
modifiersField.setAccessible(true);
modifiersField.setInt(field,field.getModifiers(),Modifier.FINAL); //去除final标记
field.setAccessible(true);
field.set(i, 100); //强行设置值
System.out.println(i);
}// 整个ArrayList体系由于我们的反射操作,导致被破坏,因此它已经无法正常工作了!
public static void main(String[] args) throws ReflectiveOperationException {
List<String> i = new ArrayList<>();
Field field = ArrayList.class.getDeclaredField("size");
field.setAccessible(true);
field.set(i, 10);
i.add("测试"); //只添加一个元素
System.out.println(i.size()); //大小直接变成11
i.remove(10); //瞎移除都不带报错的
}如何通过反射自定义ClassLoader加载类?
定义一个类:
package com.test;
public class Test {
public String text;
public void test(String str){
System.out.println(text+" > 我是测试方法!"+str);
}
}通过javac命令,手动编译一个.class文件:
javac src/main/java/com/test/Test.java编译后,得到一个class文件,我们把它放到根目录下,然后编写一个我们自己的ClassLoader,因为普通的ClassLoader无法加载二进制文件,因此我们编写一个自己的来让它支持:
//定义一个自己的ClassLoader
static class MyClassLoader extends ClassLoader{
public Class<?> defineClass(String name, byte[] b){
return defineClass(name, b, 0, b.length); //调用protected方法,支持载入外部class文件
}
}public static void main(String[] args) throws IOException {
MyClassLoader classLoader = new MyClassLoader();
FileInputStream stream = new FileInputStream("Test.class");
byte[] bytes = new byte[stream.available()];
stream.read(bytes);
// 类名必须和我们定义的保持一致
Class<?> clazz = classLoader.defineClass("com.test.Test", bytes);
// 成功加载外部class文件
System.out.println(clazz.getName());
}将此class文件读取并解析为Class了,现在我们就可以对此类进行操作了(注意,我们无法在代码中直接使用此类型,因为它是我们直接加载的),我们来试试看创建一个此类的对象并调用其方法:
try {
Object obj = clazz.newInstance();
Method method = clazz.getMethod("test", String.class); //获取我们定义的test(String str)方法
method.invoke(obj, "哥们这瓜多少钱一斤?");
}catch (Exception e){
e.printStackTrace();
}修改成员字段之后,再来调用此方法:
try {
Object obj = clazz.newInstance();
Field field = clazz.getField("text"); //获取成员变量 String text;
field.set(obj, "华强");
Method method = clazz.getMethod("test", String.class); //获取我们定义的test(String str)方法
method.invoke(obj, "哥们这瓜多少钱一斤?");
}catch (Exception e){
e.printStackTrace();
}实现外部加载甚至是网络加载一个类,只需要把类文件传递即可,这样就无需再将代码写在本地,而是动态进行传递,不仅可以一定程度上防止源代码被反编译,而且在更多情况下,我们还可以对byte[]进行加密,保证在传输过程中的安全性。
5、Java 注解
注解被标注在任意地方,包括方法上、类名上、参数上、成员属性上、注解定义上等,注解可以通过反射在运行时获取,注解可以选择是否保留到运行时。
5.1、预设注解
JDK预设了以下注解,作用于代码:
- @Override - 检查(仅仅是检查,不保留到运行时)该方法是否是重写方法。如果发现其父类,或者是引用的接口中并没有该方法时,会报编译错误。
- @Deprecated - 标记过时方法。如果使用该方法,会报编译警告。
- @SuppressWarnings - 指示编译器去忽略注解中声明的警告(仅仅编译器阶段,不保留到运行时)
- @FunctionalInterface - Java 8 开始支持,标识一个匿名函数或函数式接口。
- @SafeVarargs - Java 7 开始支持,忽略任何使用参数为泛型变量的方法或构造函数调用产生的警告。
5.2、元注解
元注解是作用于注解上的注解,用于我们编写自定义的注解:
- @Retention - 标识这个注解怎么保存,是只在代码中,还是编入class文件中,或者是在运行时可以通过反射访问。
- @Documented - 标记这些注解是否包含在用户文档中。
- @Target - 标记这个注解应该是哪种 Java 成员。
- @Inherited - 标记这个注解是继承于哪个注解类(默认 注解并没有继承于任何子类)
- @Repeatable - Java 8 开始支持,标识某注解可以在同一个声明上使用多次。
@Override是如何定义的:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}该注解由@Target限定为只能作用于方法上,ElementType是一个枚举类型,用于表示此枚举的作用域,一个注解可以有很多个作用域。@Retention表示此注解的保留策略,包括三种策略,在上述中有写到,而这里定义为只在代码中。一般情况下,自定义的注解需要定义1个@Retention和1-n个@Target。
尝试定义一个自己的注解:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
}这里我们定义一个Test注解,并将其保留到运行时,同时此注解可以作用于方法或是类上:
@Test
public class Main {
@Test
public static void main(String[] args) {
}
}5.3、注解使用
我们还可以在注解中定义一些属性,注解的属性也叫做成员变量,注解只有成员变量,没有方法。注解的成员变量在注解的定义中以“无形参的方法”形式来声明,其方法名定义了该成员变量的名字,其返回值定义了该成员变量的类型:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String value();
}默认只有一个属性时,我们可以将其名字设定为value,否则,我们需要在使用时手动指定注解的属性名称,使用value则无需填入:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String test();
}public class Main {
@Test(test = "")
public static void main(String[] args) {
}
}我们也可以使用default关键字来为这些属性指定默认值:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String value() default "都看到这里了,给个三连吧!";
}当属性存在默认值时,使用注解的时候可以不用传入属性值。当属性为数组时呢?
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String[] value();
}当属性为数组,我们在使用注解传参时,如果数组里面只有一个内容,我们可以直接传入一个值,而不是创建一个数组:
@Test("关注点了吗")
public static void main(String[] args) {
}public class Main {
@Test({"value1", "value2"}) //多个值时就使用花括号括起来
public static void main(String[] args) {
}
}5.4、反射获取注解
既然我们的注解可以保留到运行时,那么我们来看看,如何获取我们编写的注解,我们需要用到反射机制:
public static void main(String[] args) {
Class<Student> clazz = Student.class;
for (Annotation annotation : clazz.getAnnotations()) {
System.out.println(annotation.annotationType()); //获取类型
System.out.println(annotation instanceof Test); //直接判断是否为Test
Test test = (Test) annotation;
System.out.println(test.value()); //获取我们在注解中写入的内容
}
}通过反射机制,我们可以快速获取到我们标记的注解,同时还能获取到注解中填入的值,那么我们来看看,方法上的标记是不是也可以通过这种方式获取注解:
public static void main(String[] args) throws NoSuchMethodException {
Class<Student> clazz = Student.class;
for (Annotation annotation : clazz.getMethod("test").getAnnotations()) {
System.out.println(annotation.annotationType()); //获取类型
System.out.println(annotation instanceof Test); //直接判断是否为Test
Test test = (Test) annotation;
System.out.println(test.value()); //获取我们在注解中写入的内容
}
}无论是方法、类、还是字段,都可以使用getAnnotations()方法来快速获取我们标记的注解。
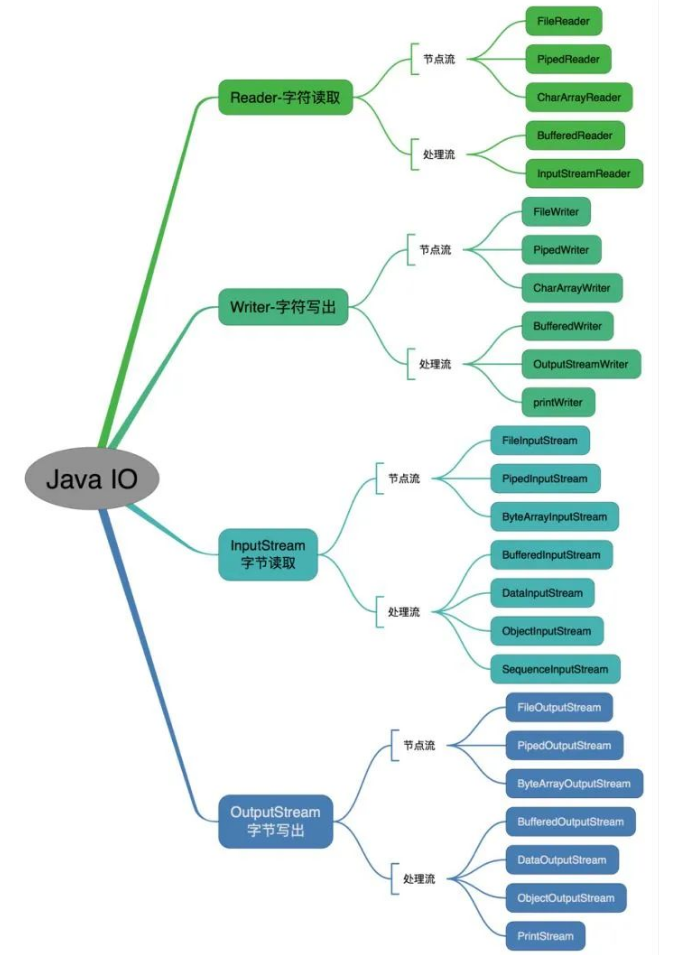
6、Java IO
6.1、IO流
流按照不同的特点,有很多种划分方式。
- 按照流的流向分,可以分为输入流和输出流;
- 按照操作单元划分,可以划分为字节流和字符流;
- 按照流的角色划分为节点流和处理流
Java Io流共涉及40多个类,看上去杂乱,其实都存在一定的关联, Java I0流的40多个类都是从如下4个抽象类基类中派生出来的。
- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
6.2、序列化
序列化就是把Java对象转为二进制流,方便存储和传输。
反序列化就是把二进制流恢复成对象。
Serializable接口有什么用?
serialVersionUID 就是起验证作用。验证序列化的对象和反序列化对应的对象ID 是否一致。
如果没有显示指定 serialVersionUID ,则编译器会根据类的相关信息自动生成一个,可以认为是一个指纹。如果你没有定义一个 serialVersionUID, 结果序列化一个对象之后,在反序列化之前把对象的类的结构改了,比如增加了一个成员变量,则此时的反序列化会失败。
Java 序列化不包含静态变量?
序列化的时候是不包含静态变量的。
如果有些变量不想序列化,怎么办?
对于不想进行序列化的变量,使用transient关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。transient 只能修饰变量,不能修饰类和方法。
有几种序列化方式?
- Java对象流列化 :Java原生序列化方法即通过Java原生流(InputStream和OutputStream之间的转化)的方式进行转化,一般是对象输出流
ObjectOutputStream和对象输入流ObjectI叩utStream。 - Json序列化:这个可能是我们最常用的序列化方式,Json序列化的选择很多,一般会使用jackson包,通过ObjectMapper类来进行一些操作,比如将对象转化为byte数组或者将json串转化为对象。
- ProtoBuff序列化:ProtocolBuffer是一种轻便高效的结构化数据存储格式,ProtoBuff序列化对象可以很大程度上将其压缩,可以大大减少数据传输大小,提高系统性能。
6.3、BIO
BIO模型是最早的jdk提供的一种处理网络连接请求的模型,是同步阻塞结构,通常由一个独立的Acceptor线程负责监听客户端的连接,它接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成后,通过输出流返回应答给客户端,线程销毁。即典型的一请求一应答模型。
BIO是同步阻塞式IO,通常在while循环中服务端会调用accept方法等待接收客户端的连接请求,一旦接收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成。
如果BIO要能够同时处理多个客户端请求,就必须使用多线程,即每次accept阻塞等待来自客户端请求,一旦受到连接请求就建立通信套接字同时开启一个新的线程来处理这个套接字的数据读写请求,然后立刻又继续accept等待其他客户端连接请求,即为每一个客户端连接请求都创建一个线程来单独处理。
6.4、NIO
NIO是同步非阻塞的,服务器端用一个线程处理多个连接,客户端发送的连接请求会注册到多路复用器上,多路复用器轮询到连接有IO请求就进行处理。
NIO的数据是面向缓冲区Buffer的,必须从Buffer中读取或写入。
所以完整的NIO示意图:
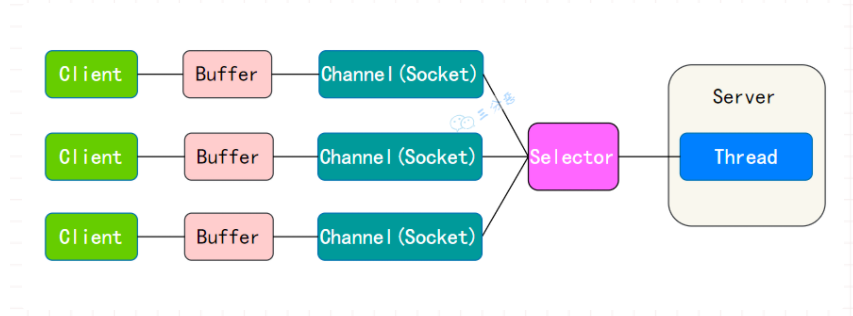
可以看出,NIO的运行机制:
- 每个Channel对应一个Buffer。
- Selector对应一个线程,一个线程对应多个Channel。
- Selector会根据不同的事件,在各个通道上切换。
- Buffer是内存块,底层是数据。
NIO模型事件处理流程:
- Acceptor注册Selector,监听accept事件;
- 当客户端连接后,触发accept事件;
- 服务器构建对应的Channel,并在其上注册Selector,监听读写事件;
- 当发生读写事件后,进行相应的读写处理。
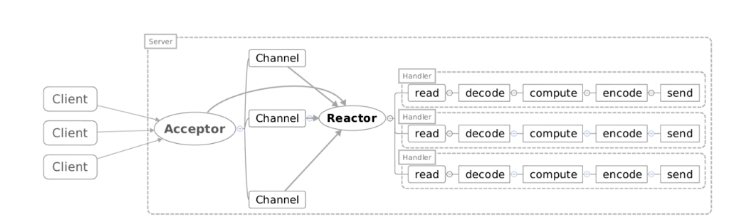
Reactor模型
Reactor单线程模型
这是最简单的单Reactor单线程模型。Reactor线程负责多路分离套接字、accept新连接,并分派请求到处理器链中。该模型适用于处理器链中业务处理组件能快速完成的场景。不过,这种单线程模型不能充分利用多核资源,所以实际使用的不多。
Reactor多线程模型
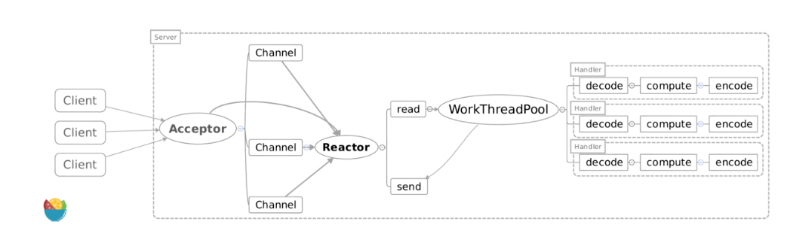
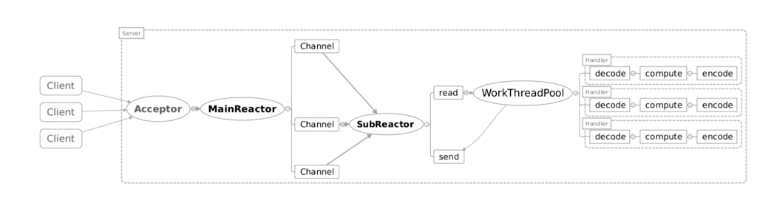
主从Reactor多线程模型
主从Reactor多线程模型是将Reactor分成两部分,mainReactor负责监听server socket,accept新连接,并将建立的socket分派给subReactor。subReactor负责多路分离已连接的socket,读写网络数据,对业务处理功能,其扔给worker线程池完成。通常,subReactor个数上可与CPU个数等同:
主Reactor用于响应连接请求,从Reactor用于处理IO操作请求。
AIO:JDK 7 引入了 Asynchronous I/O,是异步不阻塞的 IO。在进行 I/O 编程中,常用到两种模式:Reactor 和 Proactor。Java 的 NIO 就是 Reactor,当有事件触发时,服务器端得到通知,进行相应的处理,完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用。
7、Java HTTP
一次完整的HTTP请求步骤
- 根据域名和 DNS 解析到服务器的IP地址 (DNS + CDN)
- 通过ARP协议获得IP地址对应的物理机器的MAC地址
- 浏览器对服务器发起 TCP 3 次握手
- 建立 TCP 连接后发起 HTTP 请求报文
- 服务器响应 HTTP 请求,将响应报文返回给浏览器
- 短连接情况下,请求结束则通过 TCP 四次挥手关闭连接,长连接在没有访问服务器的若干时间后,进行连接的关闭
- 浏览器得到响应信息中的 HTML 代码, 并请求 HTML 代码中的资源(如js、css、图片等)
- 浏览器对页面进行渲染并呈现给用户
HTTP状态码
14种常用的HTTP状态码列表
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 2xx | ||
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 206 | Partial Content | 是对资源某一部分的请求,服务器成功处理了部分GET请求,响应报文中包含由Content-Range指定范围的实体内容。 |
| 3xx | ||
| 301 | Moved Permanently | 永久性重定向。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时性重定向。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与302类似。使用GET请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向,会按照浏览器标准,不会从POST变成GET。 |
| 4xx | ||
| 400 | Bad Request | 客户端请求报文中存在语法错误,服务器无法理解。 |
| 401 | Unauthorized | 请求要求用户的身份认证,通过HTTP认证(BASIC认证,DIGEST认证)的认证信息,若之前已进行过一次请求,则表示用户认证失败 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面。也可以在服务器拒绝请求且不想说明理由时使用 |
| 5xx | ||
| 500 | Internal Server Error | 服务器内部错误,无法完成请求,也可能是web应用存在bug或某些临时故障 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
7.1、TCP
三次握手四次挥手
一个TCP连接通常分为三个阶段:连接、数据传输、退出(关闭)。通过三次握手建立一个连接,通过四次挥手来关闭一个连接。当一个连接被建立或被终止时,交换的报文段只包含TCP头部,而没有数据。
三次握手
三次握手的本质是确认通信双方收发数据的能力
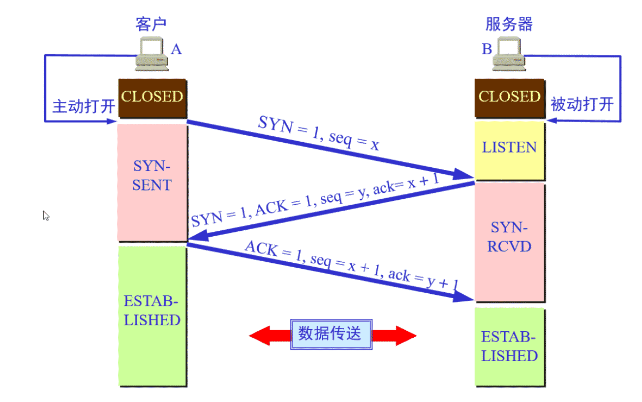
第一次握手:客户端要向服务端发起连接请求,首先客户端随机生成一个起始序列号ISN(比如是100),那客户端向服务端发送的报文段包含SYN标志位(也就是SYN=1),序列号seq=100。第二次握手:服务端收到客户端发过来的报文后,发现SYN=1,知道这是一个连接请求,于是将客户端的起始序列号100存起来,并且随机生成一个服务端的起始序列号(比如是300)。然后给客户端回复一段报文,回复报文包含SYN和ACK标志(也就是SYN=1,ACK=1)、序列号seq=300、确认号ack=101(客户端发过来的序列号+1)第三次握手:客户端收到服务端的回复后发现ACK=1并且ack=101,于是知道服务端已经收到了序列号为100的那段报文;同时发现SYN=1,知道了服务端同意了这次连接,于是就将服务端的序列号300给存下来。然后客户端再回复一段报文给服务端,报文包含ACK标志位(ACK=1)、ack=301(服务端序列号+1)、seq=101(第一次握手时发送报文是占据一个序列号的,所以这次seq就从101开始,需要注意的是不携带数据的ACK报文是不占据序列号的,所以后面第一次正式发送数据时seq还是101)。当服务端收到报文后发现ACK=1并且ack=301,就知道客户端收到序列号为300的报文了,就这样客户端和服务端通过TCP建立了连接。
四次挥手
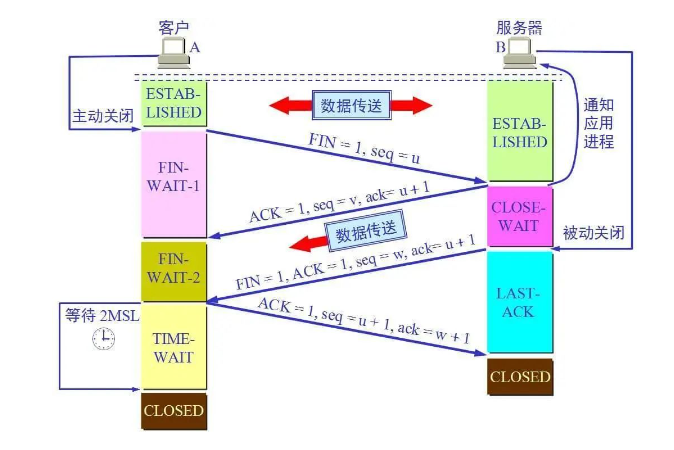
比如客户端初始化的序列号ISA=100,服务端初始化的序列号ISA=300。TCP连接成功后客户端总共发送了1000个字节的数据,服务端在客户端发FIN报文前总共回复了2000个字节的数据。
第一次挥手:当客户端的数据都传输完成后,客户端向服务端发出连接释放报文(当然数据没发完时也可以发送连接释放报文并停止发送数据),释放连接报文包含FIN标志位(FIN=1)、序列号seq=1101(100+1+1000,其中的1是建立连接时占的一个序列号)。需要注意的是客户端发出FIN报文段后只是不能发数据了,但是还可以正常收数据;另外FIN报文段即使不携带数据也要占据一个序列号。第二次挥手:服务端收到客户端发的FIN报文后给客户端回复确认报文,确认报文包含ACK标志位(ACK=1)、确认号ack=1102(客户端FIN报文序列号1101+1)、序列号seq=2300(300+2000)。此时服务端处于关闭等待状态,而不是立马给客户端发FIN报文,这个状态还要持续一段时间,因为服务端可能还有数据没发完。第三次挥手:服务端将最后数据(比如50个字节)发送完毕后就向客户端发出连接释放报文,报文包含FIN和ACK标志位(FIN=1,ACK=1)、确认号和第二次挥手一样ack=1102、序列号seq=2350(2300+50)。第四次挥手:客户端收到服务端发的FIN报文后,向服务端发出确认报文,确认报文包含ACK标志位(ACK=1)、确认号ack=2351、序列号seq=1102。注意客户端发出确认报文后不是立马释放TCP连接,而是要经过2MSL(最长报文段寿命的2倍时长)后才释放TCP连接。而服务端一旦收到客户端发出的确认报文就会立马释放TCP连接,所以服务端结束TCP连接的时间要比客户端早一些。
7.2、UDP
TODO
8、Java 集合
Java 集合框架如下图所示:
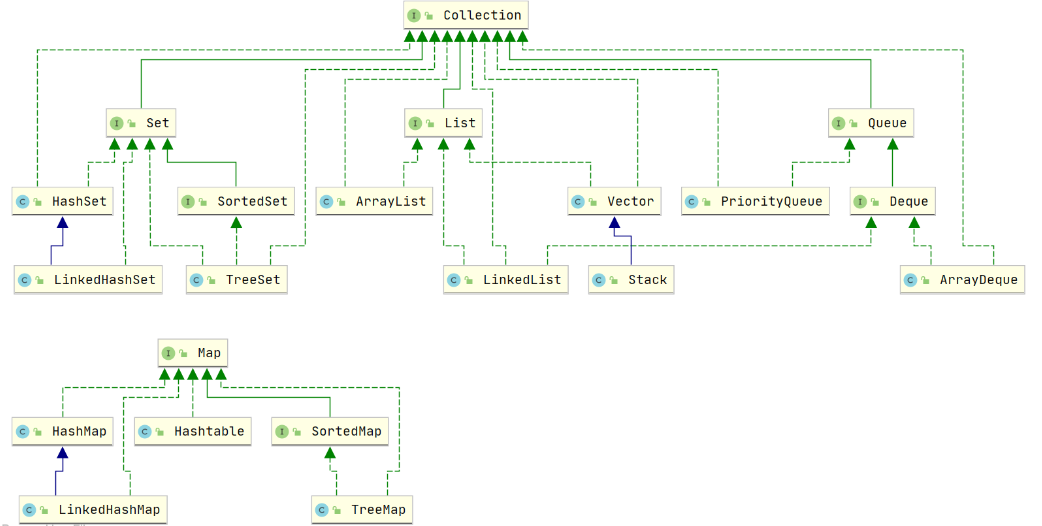
8.1、List
ArrayList:Object[]数组Vector:Object[]数组LinkedList: 双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)
8.1.1、ArrayList
public class ArrayListTest {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("1");
String s = list.get(0);
list.set(1, "2");
list.add("3");
}
// ArraryList#get
public E get(int index) {
// 检查index 是否超过 list size的 超过抛出越界的异常
rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
// ArrayList#set
public E set(int index, E element) {
// 范围检查
rangeCheck(index);
// 获取老的元素
E oldValue = elementData(index);
// 元素覆盖
elementData[index] = element;
// 将老元素返回
return oldValue;
}
// ArrayList#add
public boolean add(E e) {
// 首先确保容量够用
ensureCapacityInternal(size + 1); // Increments modCount!!
// 然后赋值到数组对应的 size++的位置
elementData[size++] = e;
return true;
}
// 判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
// 右移一位 newCapacity = oldCapacity + 一半的oldCapacity
// 然后在拷贝到新数组里
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
}ArrayList源码分析
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
/**
* 默认初始容量大小
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 空数组(用于空实例)
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* 用于默认大小空实例的共享空数组实例
* 我们把它从EMPTY_ELEMENTDATA数组中区分出来,以知道在添加第一个元素时容量需要增加多少
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 保存ArrayList数据的数组
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* ArrayList 所包含的元素个数
*/
private int size;
/**
* 带初始容量参数的构造函数(用户可以在创建ArrayList对象时自己指定集合的初始大小)
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//如果传入的参数大于0,创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//如果传入的参数等于0,创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
//其他情况,抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* 默认无参构造函数
* DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10
* 也就是说初始其实是空数组,当添加第一个元素的时候数组容量才变成10
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
*/
public ArrayList(Collection<? extends E> c) {
//将指定集合转换为数组
elementData = c.toArray();
//如果elementData数组的长度不为0
if ((size = elementData.length) != 0) {
// 如果elementData不是Object类型数据
//(c.toArray可能返回的不是Object类型的数组所以加上下面的语句用于判断)
if (elementData.getClass() != Object[].class)
//将原来不是Object类型的elementData数组的内容,赋值给新的Object类型的elementData数组
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 其他情况,用空数组代替
this.elementData = EMPTY_ELEMENTDATA;
}
}
/**
* 修改这个ArrayList实例的容量是列表的当前大小
* 应用程序可以使用此操作来最小化ArrayList实例的存储
*/
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
/**
* ArrayList的扩容机制
* @param minCapacity 所需的最小容量
*/
public void ensureCapacity(int minCapacity) {
//如果是true,minExpand的值为0,如果是false,minExpand的值为10
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
//如果最小容量大于已有的最大容量
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 获取“默认的容量”和“传入参数”两者之间的最大值
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureCapacityInternal(int minCapacity) {
//1.得到最小扩容量
//2.通过最小容量扩容
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
/**
* 要分配的最大数组大小
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* ArrayList扩容的核心方法
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量,位运算的速度远远快于整除运算
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2
//整句运算式的结果就是将新容量更新为旧容量的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//再检查新容量是否超出了ArrayList所定义的最大容量
if (newCapacity - MAX_ARRAY_SIZE > 0)
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE
//否则,新容量大小则为 MAX_ARRAY_SIZE。
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
//比较minCapacity和 MAX_ARRAY_SIZE
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
/**
* 返回此列表中的元素数。
*/
public int size() {
return size;
}
/**
* 如果此列表不包含元素,则返回 true 。
*/
public boolean isEmpty() {
return size == 0;
}
/**
* 如果此列表包含指定的元素,则返回true
*/
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
/**
* 返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
*/
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。.
*/
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* 返回此ArrayList实例的浅拷贝。 (元素本身不被复制。)
*/
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
//Arrays.copyOf功能是实现数组的复制,返回复制后的数组。参数是被复制的数组和复制的长度
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
/**
* 以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
* 返回的数组将是“安全的”,因为该列表不保留对它的引用。 (换句话说,这个方法必须分配一个新的数组)。
* 因此,调用者可以自由地修改返回的数组。 此方法充当基于阵列和基于集合的API之间的桥梁。
*/
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
// Positional Access Operations
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
/**
* 返回此列表中指定位置的元素
*/
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
/**
* 用指定的元素替换此列表中指定位置的元素
*/
public E set(int index, E element) {
//对index进行界限检查
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
/**
* 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
//ArrayList添加元素的实质就相当于为数组赋值
elementData[size++] = e;
return true;
}
/**
* 在此列表中的指定位置插入指定的元素
*/
public void add(int index, E element) {
//调用 rangeCheckForAdd 对index进行界限检查
rangeCheckForAdd(index);
//调用 ensureCapacityInternal 方法保证capacity足够大
ensureCapacityInternal(size + 1); // Increments modCount!!
//将从index开始之后的所有成员后移一个位置
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
//将element插入index位置
elementData[index] = element;
//最后size加1
size++;
}
/**
* 删除该列表中指定位置的元素。 将任何后续元素移动到左侧(从其索引中减去一个元素)。
*/
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
//从列表中删除的元素
return oldValue;
}
/**
* 从列表中删除指定元素的第一个出现(如果存在)。 如果列表不包含该元素,则它不会更改。
* @return <tt>true</tt> if this list contained the specified element
*/
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/*
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
/**
* 从列表中删除所有元素
*/
public void clear() {
modCount++;
// 把数组中所有的元素的值设为null
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
/**
* 按指定集合的Iterator返回的顺序将指定集合中的所有元素追加到此列表的末尾。
*/
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
/**
* 将指定集合中的所有元素插入到此列表中,从指定的位置开始
*/
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
/**
* 从此列表中删除所有索引为fromIndex (含)和toIndex之间的元素。
* 将任何后续元素移动到左侧(减少其索引)。
*/
protected void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = size - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// clear to let GC do its work
int newSize = size - (toIndex-fromIndex);
for (int i = newSize; i < size; i++) {
elementData[i] = null;
}
size = newSize;
}
/**
* 检查给定的索引是否在范围内
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* add和addAll使用的rangeCheck的一个版本
*/
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 返回IndexOutOfBoundsException细节信息
*/
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
/**
* 从此列表中删除指定集合中包含的所有元素。
*/
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
//如果此列表被修改则返回true
return batchRemove(c, false);
}
/**
* 仅保留此列表中包含在指定集合中的元素。
*/
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}
/**
* 序列化
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
/**
* 反序列化
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
/**
* 从列表中的指定位置开始,返回列表中的元素(按正确顺序)的列表迭代器。
* 指定的索引表示初始调用将返回的第一个元素为next 。 初始调用previous将返回指定索引减1的元素。
* 返回的列表迭代器是fail-fast 。
*/
public ListIterator<E> listIterator(int index) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index);
return new ListItr(index);
}
/**
* 返回列表中的列表迭代器(按适当的顺序)。
* 返回的列表迭代器是fail-fast 。
*/
public ListIterator<E> listIterator() {
return new ListItr(0);
}
public Iterator<E> iterator() {
return new Itr();
}
/**
* 截取列表
*/
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, 0, fromIndex, toIndex);
}
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
elementData[i] = operator.apply((E) elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
@Override
@SuppressWarnings("unchecked")
public void sort(Comparator<? super E> c) {
final int expectedModCount = modCount;
Arrays.sort((E[]) elementData, 0, size, c);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
}
ArrayList 的 elementData 为什么加上 transient 修饰?
ArrayList 中的数组定义如下:
private transient Object[] elementData;再看一下 ArrayList 的定义:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable可以看到 ArrayList 实现了 Serializable 接口,这意味着 ArrayList 支持序列化。transient 的作用是不希望 elementData 数组被序列化
8.1.2、LinkedList
LinkedList,其实本质就是一个链表,内部使用的是一个双向链表
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}当然,我们发现它还实现了Queue接口,所以LinkedList也能被当做一个队列或是栈来使用。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
// LinkedList#add
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
// 获取尾节点
final Node<E> l = last;
// 新元素维护在尾节点之后
final Node<E> newNode = new Node<>(l, e, null);
// 将尾节点指向新元素
last = newNode;
// l 为空表示 是 新new 出来的连表
if (l == null)
// 新链表维护头结点
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
// 获取node
public E get(int index) {
// 检查索引index
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
// 取linkedList的中位数 小于就从前往后找 大于就从后往前找
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
}8.2、Set
HashSet(无序,唯一): 基于HashMap实现的,底层采用HashMap来保存元素LinkedHashSet:LinkedHashSet是HashSet的子类,并且其内部是通过LinkedHashMap来实现的TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树)
Set集合特点:
- 不允许出现重复元素
- 不支持随机访问(不允许通过下标访问)
HashSet,它的底层就是采用哈希表实现的
public class SetMain {
public static void main(String[] args) {
HashSet<Integer> hashSet = new HashSet<>();
hashSet.add(1);
hashSet.add(1);
hashSet.add(2);
hashSet.forEach(System.out::println);
}
}LinkedHashSet,底层维护的不再是一个HashMap,而是LinkedHashMap,它能够在插入数据时利用链表自动维护顺序,因此这样就能够保证我们插入顺序和最后的迭代顺序一致了。
TreeSet,它会在元素插入时进行排序:
public class SetMain {
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>();
set.add(1);
set.add(3);
set.add(2);
System.out.println(set);
}
}可以看到最后得到的结果并不是我们插入顺序,而是按照数字的大小进行排列。当然,我们也可以自定义排序规则:
public class SetMain {
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>((a, b) -> b - a); //在创建对象时指定规则即可
set.add(1);
set.add(3);
set.add(2);
System.out.println(set);
}
}现在的结果就是我们自定义的排序规则了。
通过观察HashSet的源码发现,HashSet几乎都在操作内部维护的一个HashMap,也就是说,HashSet只是一个表壳,而内部维护的HashMap才是灵魂!
public class HashSet{
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
}我们发现,在添加元素时,其实添加的是一个键为我们插入的元素,而值就是PRESENT常量:
public class HashSet {
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element <tt>e</tt> to this set if
* this set contains no element <tt>e2</tt> such that
* <tt>(e==null ? e2==null : e.equals(e2))</tt>.
* If this set already contains the element, the call leaves the set
* unchanged and returns <tt>false</tt>.
*
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
}再来看TreeSet,实际上用的就是我们的TreeMap:
public class HashSet {
/**
* The backing map.
*/
private transient NavigableMap<E,Object> m;
}8.3、Queue
PriorityQueue:Object[]数组来实现二叉堆ArrayQueue:Object[]数组 + 双指针
TODO
8.4、Map
HashMap: JDK1.8 之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间LinkedHashMap:LinkedHashMap继承自HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。Hashtable: 数组+链表组成的,数组是Hashtable的主体,链表则是主要为了解决哈希冲突而存在的TreeMap: 红黑树(自平衡的排序二叉树)
8.4.1、HashMap
HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个
HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。并且, HashMap 总是使用 2 的幂作为哈希表的大小
底层数据结构分析
JDK1.8 之前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。
HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK1.7 的 HashMap 的 hash 方法源码:
static int hash(int h) {
// 扰动了 4 次
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
JDK1.8 之后
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}当链表长度大于阈值(默认为 8)时,会首先调用 treeifyBin()方法。这个方法会根据 HashMap 数组来决定是否转换为红黑树。只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是执行 resize() 方法对数组扩容。
HashMap类属性
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小容量
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组,总是2的幂次倍
transient Node<k,v>[] table;
// 存放具体元素的集
transient Set<map.entry<k,v>> entrySet;
// 存放元素的个数,注意这个不等于数组的长度。
transient int size;
// 每次扩容和更改map结构的计数器
transient int modCount;
// 临界值(容量*填充因子) 当实际大小超过临界值时,会进行扩容
int threshold;
// 加载因子
final float loadFactor;
}HashMap 源码分析
构造方法
// 默认构造函数
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
// 包含另一个“Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 指定“容量大小”和“加载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}putMapEntries方法:
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// 判断table是否已经初始化
if (table == null) { // pre-size
// 未初始化,s为m的实际元素个数
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// 计算得到的t大于阈值,则初始化阈值
if (t > threshold)
threshold = tableSizeFor(t);
}
// 已初始化,并且m元素个数大于阈值,进行扩容处理
else if (s > threshold)
resize();
// 将m中的所有元素添加至HashMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}put 方法
HashMap 只提供了 put 用于添加元素,putVal 方法只是给 put 方法调用的一个方法,并没有提供给用户使用。
当我们put的时候,首先计算
key的hash值,这里调用了hash方法,hash方法实际是让key.hashCode()与key.hashCode()>>>16进行异或操作,高16bit补0,一个数和0异或不变,所以 hash 函数大概的作用就是:高16bit不变,低16bit和高16bit做了一个异或,目的是减少碰撞。按照函数注释,因为bucket数组大小是2的幂,计算下标index = (table.length - 1) & hash
对 putVal 方法添加元素的分析如下:
- 如果定位到的数组位置没有元素 就直接插入。
- 如果定位到的数组位置有元素就和要插入的 key 比较,如果 key 相同就直接覆盖,如果 key 不相同,就判断 p 是否是一个树节点,如果是就调用
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)
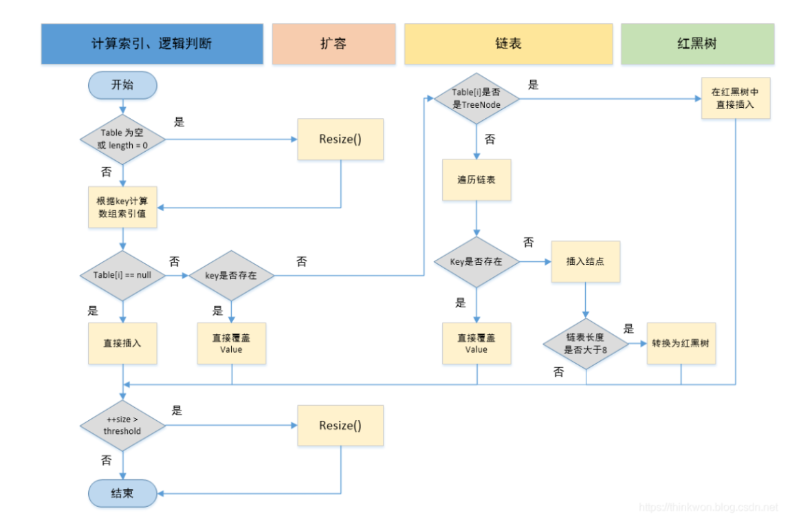
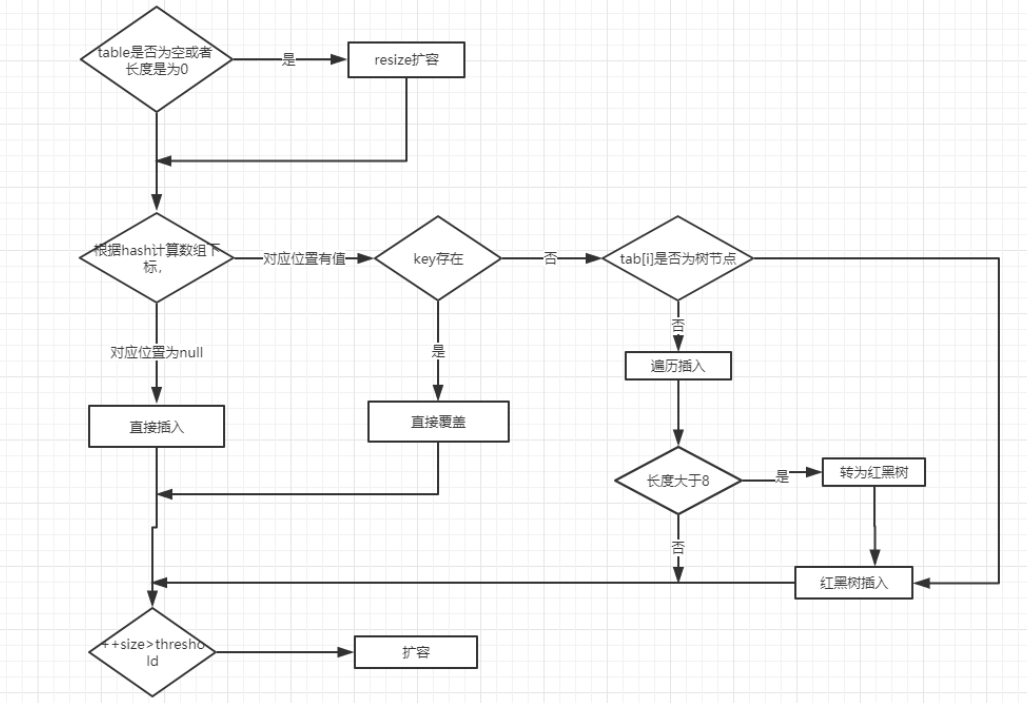
说明:上图有两个小问题:
- 直接覆盖之后应该就会 return,不会有后续操作。参考 JDK8 HashMap.java 658 行(issue#608open in new window)。
- 当链表长度大于阈值(默认为 8)并且 HashMap 数组长度超过 64 的时候才会执行链表转红黑树的操作,否则就只是对数组扩容。参考 HashMap 的
treeifyBin()方法(issue#1087open in new window)。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// table未初始化或者长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素(处理hash冲突)
else {
Node<K,V> e; K k;
// 判断table[i]中的元素是否与插入的key一样,若相同那就直接使用插入的值p替换掉旧的值e。
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 判断插入的是否是红黑树节点
else if (p instanceof TreeNode)
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 不是红黑树节点则说明为链表结点
else {
// 在链表最末插入结点
for (int binCount = 0; ; ++binCount) {
// 到达链表的尾部
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 结点数量达到阈值(默认为 8 ),执行 treeifyBin 方法
// 这个方法会根据 HashMap 数组来决定是否转换为红黑树。
// 只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是对数组扩容。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出循环
break;
}
// 判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
// 表示在桶中找到key值、hash值与插入元素相等的结点
if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 结构性修改
++modCount;
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}我们再来对比一下 JDK1.7 put 方法的代码
对于 put 方法的分析如下:
- ① 如果定位到的数组位置没有元素 就直接插入。
- ② 如果定位到的数组位置有元素,遍历以这个元素为头结点的链表,依次和插入的 key 比较,如果 key 相同就直接覆盖,不同就采用头插法插入元素。
public V put(K key, V value)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) { // 先遍历
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i); // 再插入
return null;
}get 方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 数组元素相等
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 桶中不止一个节点
if ((e = first.next) != null) {
// 在树中get
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 在链表中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}resize 方法
扩容会伴随着一次重新 hash 分配,并且会遍历 hash 表中所有的元素,非常耗时。要尽量避免 resize。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}8.4.2、LinkedHashMap
LinkedHashMap是直接继承自HashMap,具有HashMap的全部性质,同时得益于每一个节点都是一个双向链表,保存了插入顺序,这样我们在遍历LinkedHashMap时,顺序就同我们的插入顺序一致。当然,也可以使用访问顺序,也就是说对于刚访问过的元素,会被排到最后一位。
public class MapMain {
public static void main(String[] args) {
//以访问顺序
LinkedHashMap<Integer, String> map = new LinkedHashMap<>(16, 0.75f, true);
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
map.get(2);
System.out.println(map);
}
}观察结果,我们发现,刚访问的结果被排到了最后一位。
8.5、Iterator
public interface Iterator<E> {
//...
}每个集合类都有自己的迭代器,通过iterator()方法来获取:
public class ItMain {
public static void main(String[] args) {
//生成一个新的迭代器
Iterator<String> iterator = linkedList.iterator();
//判断是否还有下一个元素
while (iterator.hasNext()) {
//获取下一个元素(获取一个少一个)
String i = iterator.next();
System.out.println(i);
}
}
}迭代器生成后,默认指向第一个元素,每次调用next()方法,都会将指针后移,当指针移动到最后一个元素之后,调用hasNext()将会返回false,迭代器是一次性的,用完即止,如果需要再次使用,需要调用iterator()方法。
如何一边遍历一边删除Collection中的元素
//唯一正确方式是使用 Iterator.remove() 方法(迭代器允许调用者在迭代过程中增删元素)
Iterator<Integer> it = list.iterator();
while(it.hasNext()){
// do something
it.remove();
}快速失败机制 fail-fast
假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生fail-fast机制。
迭代器在遍历时,ArrayList的父类AbstarctList中有一个
modCount变量,每次对集合进行修改时都会modCount++,而foreach的实现原理其实就是Iterator,ArrayList的Iterator中有一个expectedModCount变量,该变量会初始化和modCount相等,每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount的值和expectedmodCount的值是否相等,如果集合进行增删操作,modCount变量就会改变,就会造成expectedModCount!=modCount,此时就会抛出ConcurrentModificationException异常TIP:
1.在遍历过程中,所有涉及到改变modCount值的地方全部加上synchronized。
2.使用CopyOnWriteArrayList来替换ArrayList
ListIterator是List中独有的迭代器,在原有迭代器基础上新增了一些额外的操作。(是否有上一个)
9、Java SPI
9.1、SPI简述
Java SPI 是基于接口的编程+策略模式+约定配置文件组合实现的动态加载机制,能够很方便的为某个接口寻找服务实现的机制。
SPI 全称:Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的接口,它可以用来启用框架扩展和替换组件。
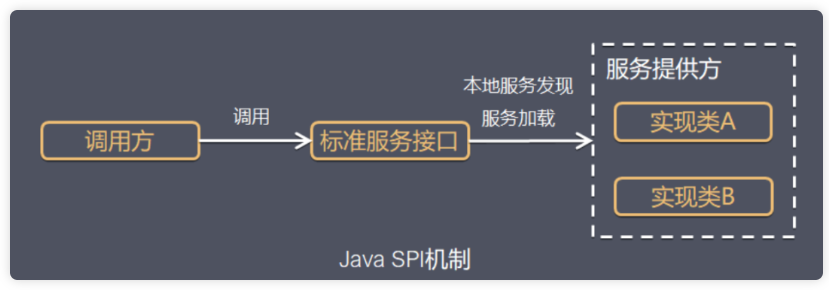
当服务的提供者提供了一种接口的实现之后,需要在classpath下的 META-INF/services/ 目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体的实现类。
当其他的程序需要这个服务的时候,就可以通过查找这个jar包(一般都是以jar包做依赖)的META-INF/services/中的配置文件,配置文件中有接口的具体实现类名,可以根据这个类名进行加载实例化,就可以使用该服务了。JDK中查找服务的实现的工具类是:java.util.ServiceLoader。
9.2、源码分析
9.2.1、ServiceLoader
public interface AnimalSay {
void say();
}@Data
public class AnimalManagerLoader {
private static final AnimalManagerLoader INSTANCE = new AnimalManagerLoader();
private final List<AnimalSay> animalSays;
public AnimalManagerLoader() {
animalSays = load();
}
/**
* 通过SPI加载实现类
*/
private List<AnimalSay> load() {
ArrayList<AnimalSay> animalSays = new ArrayList<>();
Iterator<AnimalSay> iterator = ServiceLoader.load(AnimalSay.class).iterator();
while (iterator.hasNext()) {
animalSays.add(iterator.next());
}
return animalSays;
}
public static AnimalManagerLoader getInstance() {
return INSTANCE;
}
}public class CatSay implements AnimalSay {
@Override
public void say() {
System.out.println("猫叫");
}
}public class DogSay implements AnimalSay{
@Override
public void say() {
System.out.println("狗叫");
}
}public class ServiceLoaderTest {
public static void main(String[] args) {
AnimalManagerLoader animalManagerLoader = AnimalManagerLoader.getInstance();
List<AnimalSay> animalSays = animalManagerLoader.getAnimalSays();
for (AnimalSay animalSay : animalSays) {
animalSay.say();
}
}
}输出结果:
Connected to the target VM, address: '127.0.0.1:50169', transport: 'socket' 狗叫 猫叫 Disconnected from the target VM, address: '127.0.0.1:50169', transport: 'socket'
/**
* 通过SPI加载实现类
*/
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
// 调用以下 load 方法
return ServiceLoader.load(service, cl);
}
public static <S> ServiceLoader<S> load(Class<S> service,ClassLoader loader){
return new ServiceLoader<>(service, loader);
}
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}9.3、SPI 的不足
- 不能按需加载,需要遍历所有的实现,并实例化,然后在循环中才能找到我们需要的实现。如果不想用某些实现类,或者某些类实例化很耗时,它也被载入并实例化了,这就造成了浪费。
- 获取某个实现类的方式不够灵活,只能通过 Iterator 形式获取,不能根据某个参数来获取对应的实现类。(Spring 的BeanFactory,ApplicationContext 就要高级一些了。)
- 多个并发多线程使用 ServiceLoader 类的实例是不安全的。
9.4、SPI 应用场景
SPI扩展机制应用场景有很多,比如Common-Logging,JDBC,Dubbo、ShardingSphere等等。
9.4.1、JDBC场景
java中定义的java.sql.Driver接口,并没有具体的实现,实现方式而是交给不同的服务厂商:
在MySQL的jar包mysql-connector-java-6.0.6.jar中,可以找到META-INF/services目录,该目录下会有一个名字为java.sql.Driver的文件,文件内容是com.mysql.cj.jdbc.Driver,这里面的内容就是针对Java中定义的接口的实现。
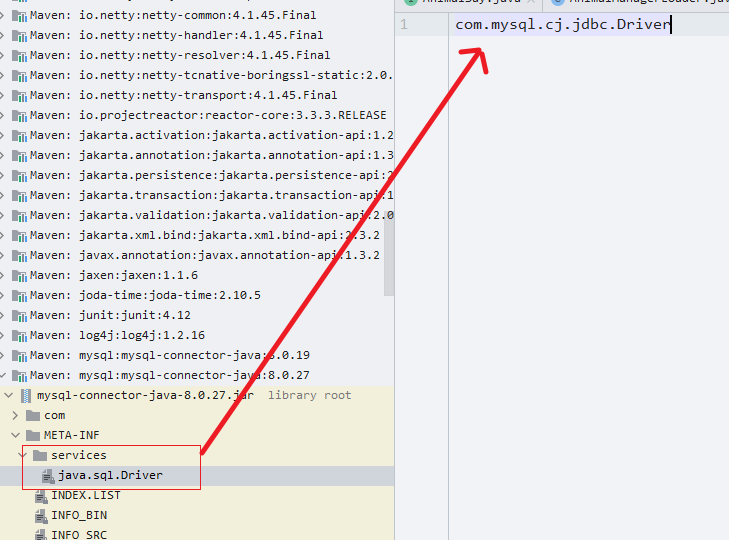 java
javapublic class Driver extends NonRegisteringDriver implements java.sql.Driver { // Register ourselves with the DriverManager static { try { java.sql.DriverManager.registerDriver(new Driver()); } catch (SQLException E) { throw new RuntimeException("Can't register driver!"); } } /** * Construct a new driver and register it with DriverManager * @throws SQLException if a database error occurs. */ public Driver() throws SQLException { // Required for Class.forName().newInstance() } }PostgreSQL的jar包PostgreSQL-42.0.0.jar中,也可以找到同样的配置文件,文件内容是org.postgresql.Driver,这是PostgreSQL对Java的java.sql.Driver的实现。
9.4.2、ShardingSphere场景
在ShardingSphere中为了实现分布式事务提供了一个接口ShardingTransactionManager,但是在其架构中并未对其做出具体的实现,而是交给不同的厂商去实现,比如JTA强一致性事务的XAShardingTransactionManager,在其中META-INF/services就有一个org.apache.shardingsphere.transaction.spi.ShardingTransactionManager文件
9.4.3、Spring 场景
Spring中大量使用了SPI;比如:对servlet3.0规范对ServletContainerInitializer的实现、自动类型转换Type Conversion SPI(Converter SPI、Formatter SPI)等
9.4.4、 SLF4J 日志门面场景
SLF4J加载不同提供商的日志实现类,比如log4j、log4j2、logback.....