jvm学习笔记
jvm启动流程
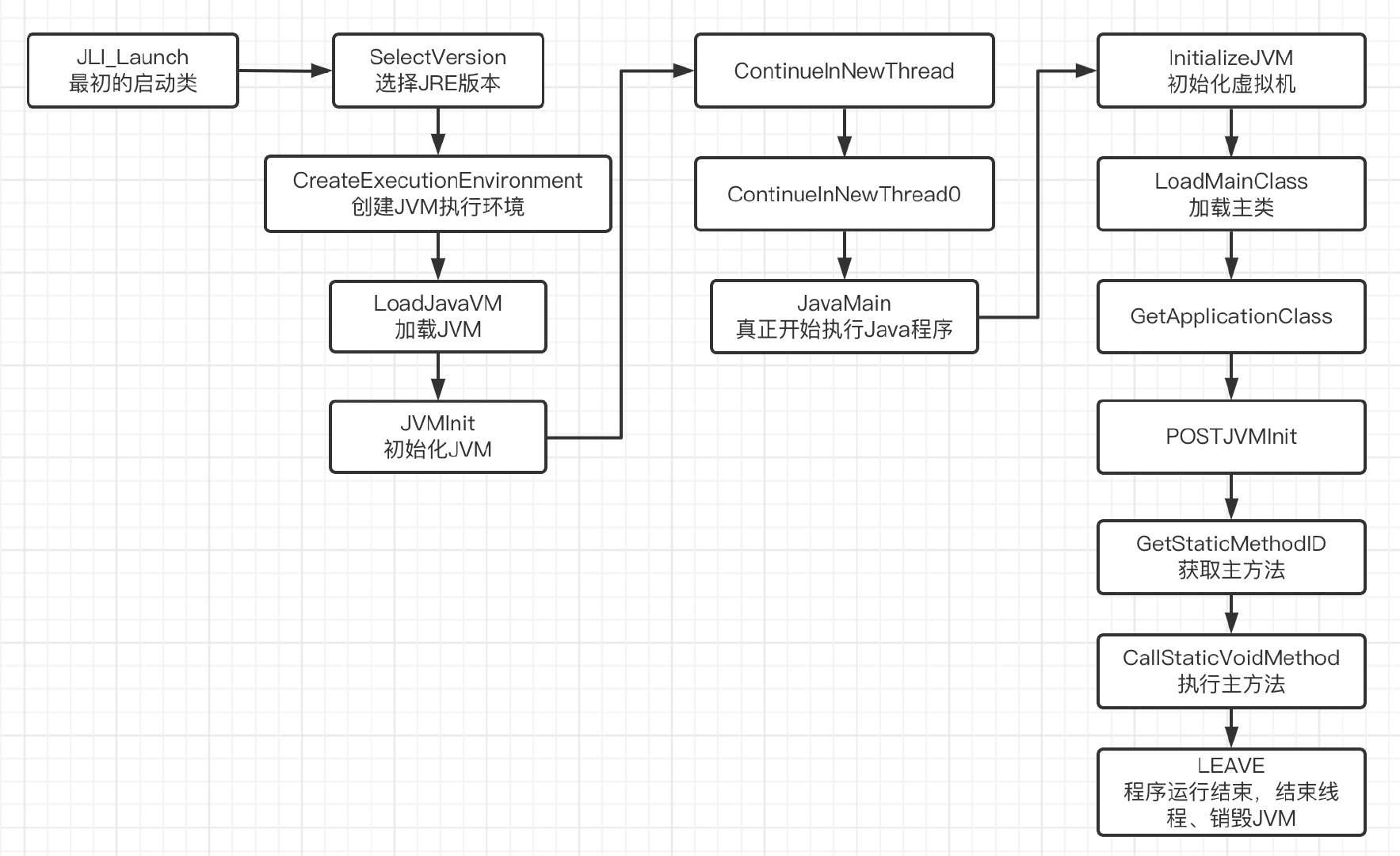
虚拟机的启动入口位于jdk/src/share/bin/java.c的JLI_Launch函数,整个流程分为如下几个步骤:
- 配置JVM装载环境
- 解析虚拟机参数
- 设置线程栈大小
- 执行JavaMain方法
JLI_Launch函数
入口点的参数有很多个,其中包括当前的完整版本名称、简短版本名称、运行参数、程序名称、启动器名称等
int
JLI_Launch(int argc, char ** argv, /* main argc, argc */
int jargc, const char** jargv, /* java args */
int appclassc, const char** appclassv, /* app classpath */
const char* fullversion, /* full version defined */
const char* dotversion, /* dot version defined */
const char* pname, /* program name */
const char* lname, /* launcher name */
jboolean javaargs, /* JAVA_ARGS */
jboolean cpwildcard, /* classpath wildcard */
jboolean javaw, /* windows-only javaw */
jint ergo_class /* ergnomics policy */
);首先进行一些初始化操作以及Debug信息打印配置等:
InitLauncher(javaw);
DumpState();
if (JLI_IsTraceLauncher()) {
int i;
printf("Command line args:\n");
for (i = 0; i < argc ; i++) {
printf("argv[%d] = %s\n", i, argv[i]);
}
AddOption("-Dsun.java.launcher.diag=true", NULL);
}接着就是选择一个合适的JRE版本
/*
* Make sure the specified version of the JRE is running.
*
* There are three things to note about the SelectVersion() routine:
* 1) If the version running isn't correct, this routine doesn't
* return (either the correct version has been exec'd or an error
* was issued).
* 2) Argc and Argv in this scope are *not* altered by this routine.
* It is the responsibility of subsequent code to ignore the
* arguments handled by this routine.
* 3) As a side-effect, the variable "main_class" is guaranteed to
* be set (if it should ever be set). This isn't exactly the
* poster child for structured programming, but it is a small
* price to pay for not processing a jar file operand twice.
* (Note: This side effect has been disabled. See comment on
* bugid 5030265 below.)
*/
SelectVersion(argc, argv, &main_class);接着是创建JVM执行环境,例如需要确定数据模型,是32位还是64位,以及jvm本身的一些配置在jvm.cfg文件中读取和解析
CreateExecutionEnvironment(&argc, &argv,
jrepath, sizeof(jrepath),
jvmpath, sizeof(jvmpath),
jvmcfg, sizeof(jvmcfg));此函数只在头文件中定义,具体的实现是根据不同平台而定的。接着会动态加载jvm.so这个共享库,并把jvm.so中的相关函数导出并且初始化,而启动JVM的函数也在其中
if (!LoadJavaVM(jvmpath, &ifn)) {
return(6);
}最后就是对JVM进行初始化
return JVMInit(&ifn, threadStackSize, argc, argv, mode, what, ret);
//mac实现
int
JVMInit(InvocationFunctions* ifn, jlong threadStackSize,
int argc, char **argv,
int mode, char *what, int ret) {
if (sameThread) {
//无需关心....
} else {
//正常情况下走这个
return ContinueInNewThread(ifn, threadStackSize, argc, argv, mode, what, ret);
}
}最后进入了一个
ContinueInNewThread函数,这个函数会创建一个新的线程来执行
int
ContinueInNewThread(InvocationFunctions* ifn, jlong threadStackSize,
int argc, char **argv,
int mode, char *what, int ret)
{
...
rslt = ContinueInNewThread0(JavaMain, threadStackSize, (void*)&args);
/* If the caller has deemed there is an error we
* simply return that, otherwise we return the value of
* the callee
*/
return (ret != 0) ? ret : rslt;
}
}接着进入了一个名为
ContinueInNewThread0的函数,可以看到它将JavaMain函数传入作为参数,而此函数定义的第一个参数类型是一个函数指针:
int
ContinueInNewThread0(int (JNICALL *continuation)(void *), jlong stack_size, void * args) {
int rslt;
pthread_t tid;
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
if (stack_size > 0) {
pthread_attr_setstacksize(&attr, stack_size);
}
if (pthread_create(&tid, &attr, (void *(*)(void*))continuation, (void*)args) == 0) {
void * tmp;
pthread_join(tid, &tmp);
rslt = (int)tmp;
} else {
/*
* Continue execution in current thread if for some reason (e.g. out of
* memory/LWP) a new thread can't be created. This will likely fail
* later in continuation as JNI_CreateJavaVM needs to create quite a
* few new threads, anyway, just give it a try..
*/
rslt = continuation(args);
}
pthread_attr_destroy(&attr);
return rslt;
}最后实际上是在新的线程中执行
JavaMain函数,最后我们再来看看此函数里面做了什么事情:
/* Initialize the virtual machine */
start = CounterGet();
if (!InitializeJVM(&vm, &env, &ifn)) {
JLI_ReportErrorMessage(JVM_ERROR1);
exit(1);
}第一步初始化虚拟机,如果报错直接退出。接着就是加载主类(至于具体如何加载一个类,我们会放在后面进行讲解),因为主类是我们Java程序的入口点:
/*
* Get the application's main class.
*
* See bugid 5030265. The Main-Class name has already been parsed
* from the manifest, but not parsed properly for UTF-8 support.
* Hence the code here ignores the value previously extracted and
* uses the pre-existing code to reextract the value. This is
* possibly an end of release cycle expedient. However, it has
* also been discovered that passing some character sets through
* the environment has "strange" behavior on some variants of
* Windows. Hence, maybe the manifest parsing code local to the
* launcher should never be enhanced.
*
* Hence, future work should either:
* 1) Correct the local parsing code and verify that the
* Main-Class attribute gets properly passed through
* all environments,
* 2) Remove the vestages of maintaining main_class through
* the environment (and remove these comments).
*
* This method also correctly handles launching existing JavaFX
* applications that may or may not have a Main-Class manifest entry.
*/
mainClass = LoadMainClass(env, mode, what);某些没有主方法的Java程序比如JavaFX应用,会获取ApplicationMainClass:
/*
* In some cases when launching an application that needs a helper, e.g., a
* JavaFX application with no main method, the mainClass will not be the
* applications own main class but rather a helper class. To keep things
* consistent in the UI we need to track and report the application main class.
*/
appClass = GetApplicationClass(env);初始化完成:
/*
* PostJVMInit uses the class name as the application name for GUI purposes,
* for example, on OSX this sets the application name in the menu bar for
* both SWT and JavaFX. So we'll pass the actual application class here
* instead of mainClass as that may be a launcher or helper class instead
* of the application class.
*/
PostJVMInit(env, appClass, vm);接着就是获取主类中的主方法:
/*
* The LoadMainClass not only loads the main class, it will also ensure
* that the main method's signature is correct, therefore further checking
* is not required. The main method is invoked here so that extraneous java
* stacks are not in the application stack trace.
*/
mainID = (*env)->GetStaticMethodID(env, mainClass, "main",
"([Ljava/lang/String;)V");在字节码中
void main(String[] args)表示为([Ljava/lang/String;)V我们之后会详细介绍。接着就是调用主方法了:
/* Invoke main method. */
(*env)->CallStaticVoidMethod(env, mainClass, mainID, mainArgs);调用后,我们的Java程序就开飞速运行起来,直到走到主方法的最后一行返回:
/*
* The launcher's exit code (in the absence of calls to
* System.exit) will be non-zero if main threw an exception.
*/
ret = (*env)->ExceptionOccurred(env) == NULL ? 0 : 1;
LEAVE();至此,一个Java程序的运行流程结束,在最后LEAVE函数中会销毁JVM。
jvm内存模型
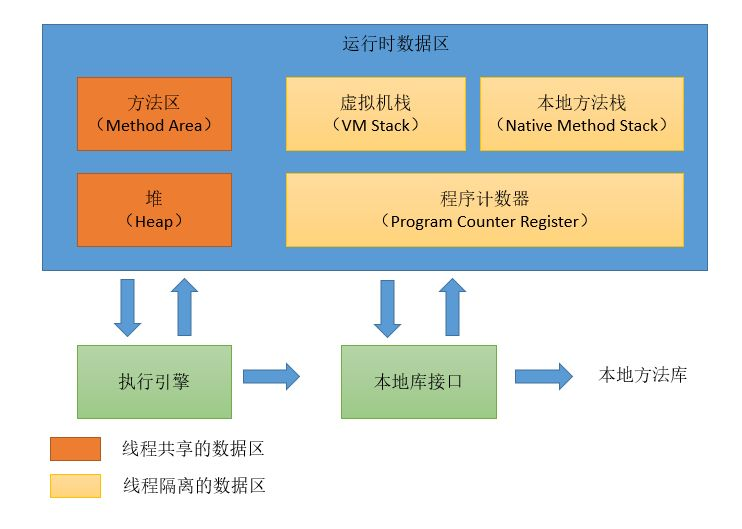
内存区域一共分为5个区域,其中方法区和堆是所有线程共享的区域,随着虚拟机的创建而创建,虚拟机的结束而销毁,而虚拟机栈、本地方法栈、程序计数器都是线程之间相互隔离的,每个线程都有一个自己的区域,并且线程启动时会自动创建,结束之后会自动销毁。内存划分完成之后,我们的JVM执行引擎和本地库接口,也就是Java程序开始运行之后就会根据分区合理地使用对应区域的内存了。
总结各个内存区域的用途:
- (线程独有)程序计数器:保存当前程序的执行位置。
- (线程独有)虚拟机栈:通过栈帧来维持方法调用顺序,帮助控制程序有序运行。
- (线程独有)本地方法栈:同上,作用与本地方法。
- 堆:所有的对象和数组都在这里保存。(JDK7后字符串常量池从方法区移动到了堆中)
- 方法区:类信息、即时编译器的代码缓存、运行时常量池。
程序计数器
JVM中的程序计数器可以看做是当前线程所执行字节码的行号指示器,而行号正好就指的是某一条指令,字节码解释器在工作时也会改变这个值,来指定下一条即将执行的指令。
Java的多线程也是依靠时间片轮转算法进行的,因此一个CPU同一时间也只会处理一个线程,当某个线程的时间片消耗完成后,会自动切换到下一个线程继续执行,而当前线程的执行位置会被保存到当前线程的程序计数器中,当下次轮转到此线程时,又继续根据之前的执行位置继续向下执行。
程序计数器因为只需要记录很少的信息,所以只占用很少一部分内存。
虚拟机栈
栈结构,每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧(其实就是栈里面的一个元素),栈帧中包括了当前方法的一些信息,比如局部变量表、操作数栈、动态链接、方法出口等。

局部变量表就是我们方法中的局部变量,实际上局部变量表在class文件中就已经定义好了
操作数栈就是字节码执行时使用到的栈结构
每个栈帧还保存了一个可以指向当前方法所在类的运行时常量池,目的是:当前方法中如果需要调用其他方法的时候,能够从运行时常量池中找到对应的符号引用,然后将符号引用转换为直接引用,然后就能直接调用对应方法,这就是动态链接
方法出口,也就是方法该如何结束,是抛出异常还是正常返回
虚拟机栈运作流程
javapublic class Main { public static void main(String[] args) { int res = a(); System.out.println(res); } public static int a(){ return b(); } public static int b(){ return c(); } public static int c(){ int a = 10; int b = 20; return a + b; } }当我们的主方法执行后,会依次执行三个方法
a() -> b() -> c() -> 返回,反编译之后的结果:c{ public com.test.Main(); #这个是构造方法 descriptor: ()V flags: ACC_PUBLIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return LineNumberTable: line 3: 0 LocalVariableTable: Start Length Slot Name Signature 0 5 0 this Lcom/test/Main; public static void main(java.lang.String[]); #主方法 descriptor: ([Ljava/lang/String;)V flags: ACC_PUBLIC, ACC_STATIC Code: stack=2, locals=2, args_size=1 0: invokestatic #2 // Method a:()I 3: istore_1 4: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream; 7: iload_1 8: invokevirtual #4 // Method java/io/PrintStream.println:(I)V 11: return LineNumberTable: line 5: 0 line 6: 4 line 7: 11 LocalVariableTable: Start Length Slot Name Signature 0 12 0 args [Ljava/lang/String; 4 8 1 res I public static int a(); descriptor: ()I flags: ACC_PUBLIC, ACC_STATIC Code: stack=1, locals=0, args_size=0 0: invokestatic #5 // Method b:()I 3: ireturn LineNumberTable: line 10: 0 public static int b(); descriptor: ()I flags: ACC_PUBLIC, ACC_STATIC Code: stack=1, locals=0, args_size=0 0: invokestatic #6 // Method c:()I 3: ireturn LineNumberTable: line 14: 0 public static int c(); descriptor: ()I flags: ACC_PUBLIC, ACC_STATIC Code: stack=2, locals=2, args_size=0 0: bipush 10 2: istore_0 3: bipush 20 5: istore_1 6: iload_0 7: iload_1 8: iadd 9: ireturn LineNumberTable: line 18: 0 line 19: 3 line 20: 6 LocalVariableTable: Start Length Slot Name Signature 3 7 0 a I 6 4 1 b I }编译之后,我们整个方法的最大操作数栈深度、局部变量表都是已经确定好的,当我们程序开始执行时,会根据这些信息封装为对应的栈帧,我们从
main方法开始看起:
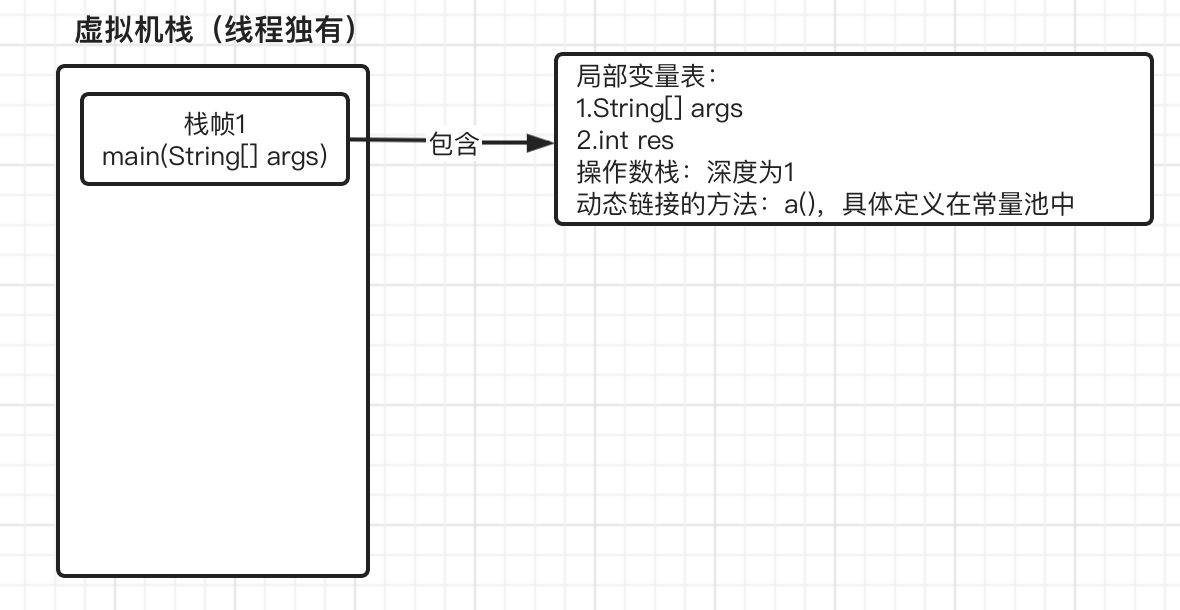
接着我们继续往下,到了
0: invokestatic #2 // Method a:()I时,需要调用方法a(),这时当前方法就不会继续向下运行了,而是去执行方法a(),那么同样的,将此方法也入栈,注意是放入到栈顶位置,main方法的栈帧会被压下去:

这时,进入方法a之后,又继而进入到方法b,最后在进入c,因此,到达方法c的时候,我们的虚拟机栈变成了:
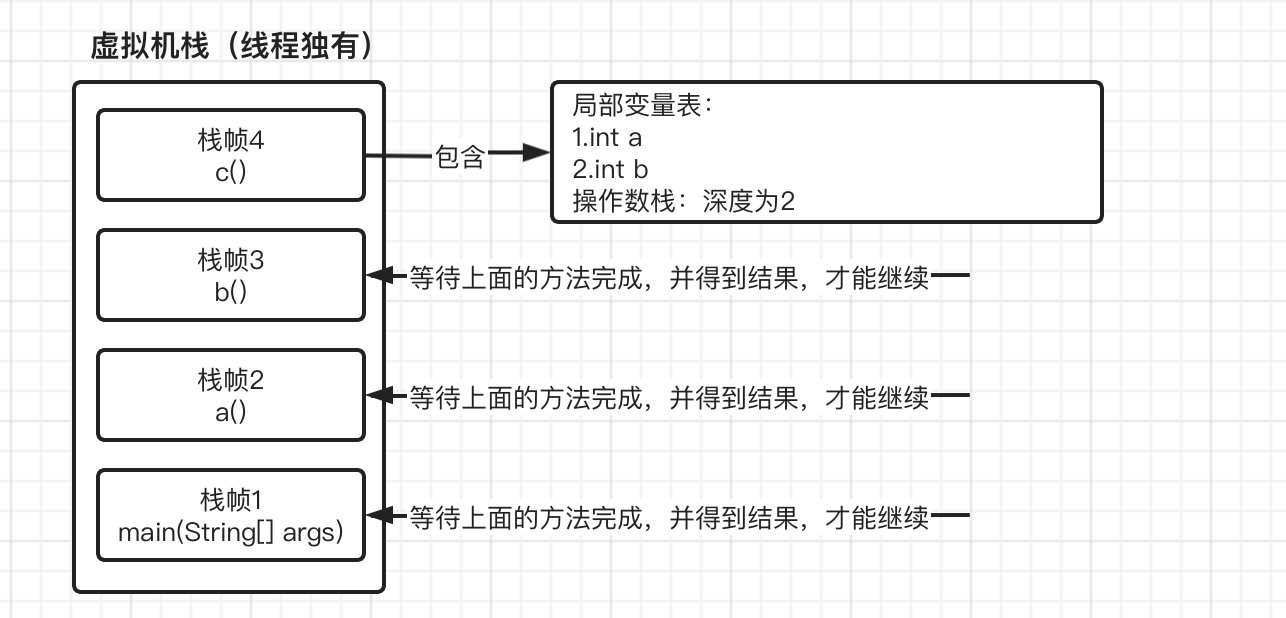
现在我们依次执行方法c中的指令,最后返回a+b的结果,在方法c返回之后,也就代表方法c已经执行结束了,栈帧4会自动出栈,这时栈帧3就得到了上一栈帧返回的结果,并继续执行,但是由于紧接着马上就返回,所以继续重复栈帧4的操作,此时栈帧3也出栈并继续将结果交给下一个栈帧2,最后栈帧2再将结果返回给栈帧1,然后栈帧1就可以继续向下运行了,最后输出结果。

本地方法栈
本地方法栈与虚拟机栈作用差不多,作用于本地方法
堆
堆是整个Java应用程序共享的区域,也是整个虚拟机最大的一块内存空间,而此区域的职责就是存放和管理对象和数组,垃圾回收机制也是主要作用于这一部分内存区域
方法区
方法区也是整个Java应用程序共享的区域,它用于存储所有的类信息、常量、静态变量、动态编译缓存等数据,可以大致分为两个部分
一个是类信息表,一个是运行时常量池。

类信息表中存放的是当前应用程序加载的所有类信息,包括类的版本、字段、方法、接口等信息,同时会将编译时生成的常量池数据全部存放到运行时常量池中。当然,常量也并不是只能从类信息中获取,在程序运行时,也有可能会有新的常量进入到常量池。
垃圾回收机制
对象存活判定算法
引用计数法
要经常操作一个对象,那么首先一定会创建一个引用变量:
//str就是一个引用类型的变量,它持有对后面字符串对象的引用,可以代表后面这个字符串对象本身
String str = "lbwnb";
//str.xxxxx...实际上,我们会发现,只要一个对象还有使用价值,我们就会通过它的引用变量来进行操作,那么可否这样判断一个对象是否还需要被使用:
- 每个对象都包含一个 引用计数器,用于存放引用计数(其实就是存放被引用的次数)
- 每当有一个地方引用此对象时,引用计数
+1 - 当引用失效( 比如离开了局部变量的作用域或是引用被设定为
null)时,引用计数-1 - 当引用计数为
0时,表示此对象不可能再被使用,因为这时我们已经没有任何方法可以得到此对象的引用了
但是这样存在一个问题,如果两个对象相互引用呢?
public class Main {
public static void main(String[] args) {
Test a = new Test();
Test b = new Test();
a.another = b;
b.another = a;
//这里直接把a和b赋值为null,这样前面的两个对象我们不可能再得到了
a = b = null;
}
private static class Test{
Test another;
}
}按照引用计数算法,那么当出现以上情况时,虽然我们无法在得到此对象的引用了,并且此对象我们也无需再使用,但是由于这两个对象直接存在相互引用的情况,那么引用计数器的值将会永远是1,但是实际上此对象已经没有任何用途了。所以引用计数法并不是最好的解决方案。
可达性分析算法
如果某个对象无法到达任何GC Roots,则证明此对象是不可能再被使用的。
目前比较主流的编程语言(包括Java),一般都会使用可达性分析算法来判断对象是否存活,它采用了类似于树结构的搜索机制。
首先每个对象的引用都有机会成为树的根节点(GC Roots),可以被选定作为根节点条件如下:
- 位于虚拟机栈的栈帧中的本地变量表中所引用到的对象(其实就是我们方法中的局部变量)同样也包括本地方法栈中JNI引用的对象。
- 类的静态成员变量引用的对象。
- 方法区中,常量池里面引用的对象,比如我们之前提到的
String类型对象。 - 被添加了锁的对象(比如synchronized关键字)
- 虚拟机内部需要用到的对象。

一旦已经存在的根节点不满足存在的条件时,那么根节点与对象之间的连接将被断开。此时虽然对象1仍存在对其他对象的引用,但是由于其没有任何根节点引用,所以此对象即可被判定为不再使用。比如某个方法中的局部变量引用,在方法执行完成返回之后:

这样就能很好地解决我们刚刚提到的循环引用问题,我们再来重现一下出现循环引用的情况:

可以看到,对象1和对象2依然是存在循环引用的,但是只有他们各自的GC Roots断开,那么就会变成下面这样:

最终判定机制
虽然在经历了可达性分析算法之后基本可能判定哪些对象能够被回收,但是并不代表此对象一定会被回收,我们依然可以在最终判定阶段对其进行挽留。
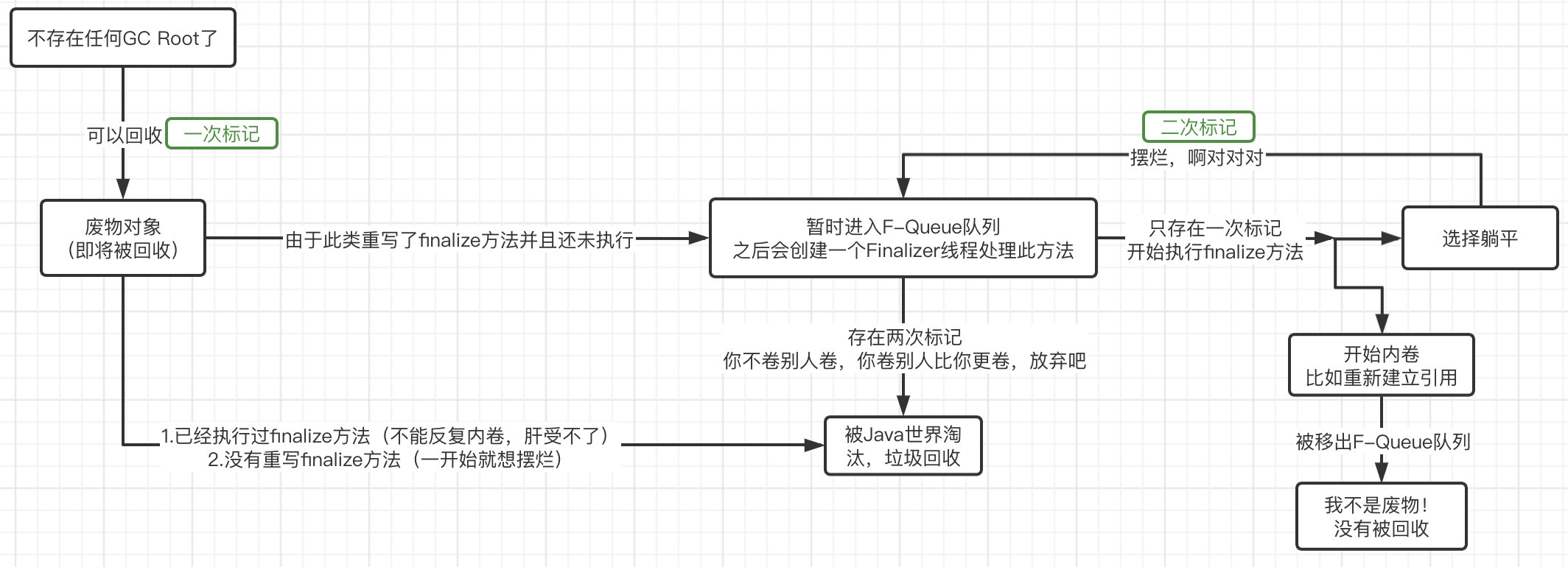
java/** * Called by the garbage collector on an object when garbage collection * determines that there are no more references to the object. * A subclass overrides the {@code finalize} method to dispose of * system resources or to perform other cleanup. * ... */ protected void finalize() throws Throwable { }
此方法正是最终判定方法,如果子类重写了此方法,那么子类对象在被判定为可回收时,会进行二次确认,也就是执行
finalize()方法,而在此方法中,当前对象是完全有可能重新建立GC Roots的!所以,如果在二次确认后对象不满足可回收的条件,那么此对象不会被回收,巧妙地逃过了垃圾回收的命运。比如下面这个例子:javapublic class Main { private static Test a; public static void main(String[] args) throws InterruptedException { a = new Test(); //这里直接把a赋值为null,这样前面的对象我们不可能再得到了 a = null; //手动申请执行垃圾回收操作(注意只是申请,并不一定会执行,但是一般情况下都会执行) System.gc(); //等垃圾回收一下() Thread.sleep(1000); //我们来看看a有没有被回收 System.out.println(a); } private static class Test{ @Override protected void finalize() throws Throwable { System.out.println(this+" 开始了它的救赎之路!"); a = this; } } }注意
finalize()方法并不是在主线程调用的,而是虚拟机自动建立的一个低优先级的Finalizer线程(正是因为优先级比较低,所以前面才需要等待1秒钟)进行处理,我们可以稍微修改一下看看:javaprivate static class Test{ @Override protected void finalize() throws Throwable { System.out.println(Thread.currentThread()); a = this; } }Thread[Finalizer,8,system] com.test.Main$Test@232204a1同时,同一个对象的
finalize()方法只会有一次调用机会,也就是说,如果我们连续两次这样操作,那么第二次,对象必定被回收:javapublic static void main(String[] args) throws InterruptedException { a = new Test(); //这里直接把a赋值为null,这样前面的对象我们不可能再得到了 a = null; //手动申请执行垃圾回收操作(注意只是申请,并不一定会执行,但是一般情况下都会执行) System.gc(); //等垃圾回收一下 Thread.sleep(1000); System.out.println(a); //这里直接把a赋值为null,这样前面的对象我们不可能再得到了 a = null; //手动申请执行垃圾回收操作(注意只是申请,并不一定会执行,但是一般情况下都会执行) System.gc(); //等垃圾回收一下 Thread.sleep(1000); System.out.println(a); }当然,
finalize()方法也并不是专门防止对象被回收的,我们可以使用它来释放一些程序使用中的资源等。
分代收集机制
Java虚拟机将堆内存划分为新生代、老年代和永久代(其中永久代是HotSpot虚拟机特有的概念,在JDK8之前方法区实际上就是采用的永久代作为实现,而在JDK8之后,方法区由元空间实现,并且使用的是本地内存,容量大小取决于物理机实际大小,之后会详细介绍)这里我们主要讨论的是新生代和老年代。
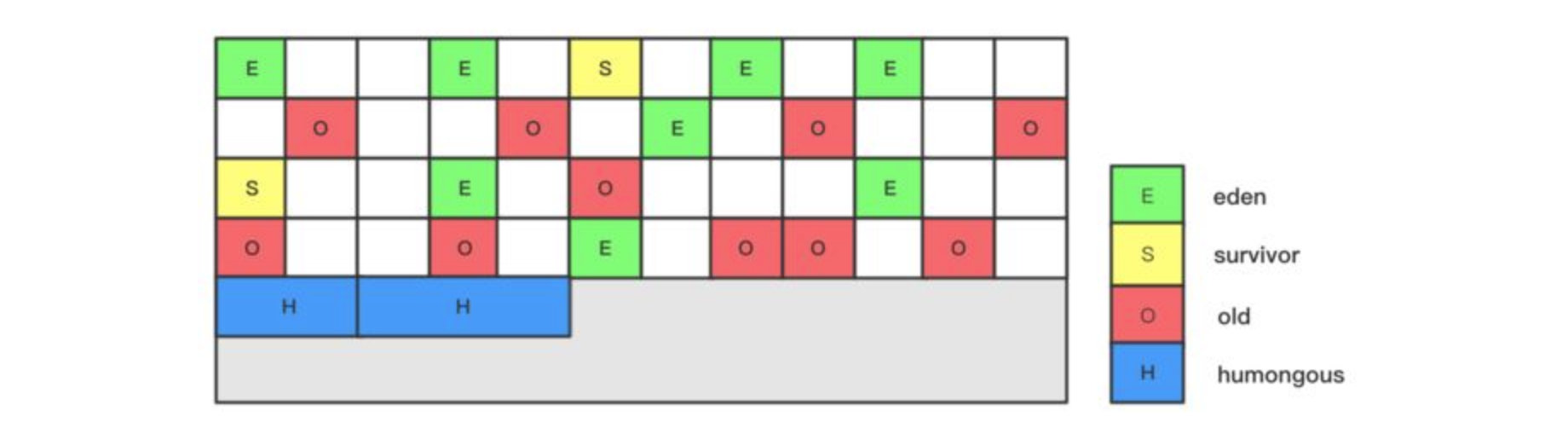
不同的分代内存回收机制也存在一些不同之处,在HotSpot虚拟机中,新生代被划分为三块,一块较大的Eden空间和两块较小的Survivor空间,默认比例为8:1:1,老年代的GC评率相对较低,永久代一般存放类信息等(其实就是方法区的实现)如图所示:

那么它是如何运作的呢?
首先,所有新创建的对象,在一开始都会进入到新生代的Eden区(如果是大对象会被直接丢进老年代),在进行新生代区域的垃圾回收时,首先会对所有新生代区域的对象进行扫描,并回收那些不再使用对象:

接着,在一次垃圾回收之后,Eden区域没有被回收的对象,会进入到Survivor区。在一开始From和To都是空的,而GC之后,所有Eden区域存活的对象都会直接被放入到From区,最后From和To会发生一次交换,也就是说目前存放我们对象的From区,变为To区,而To区变为From区:
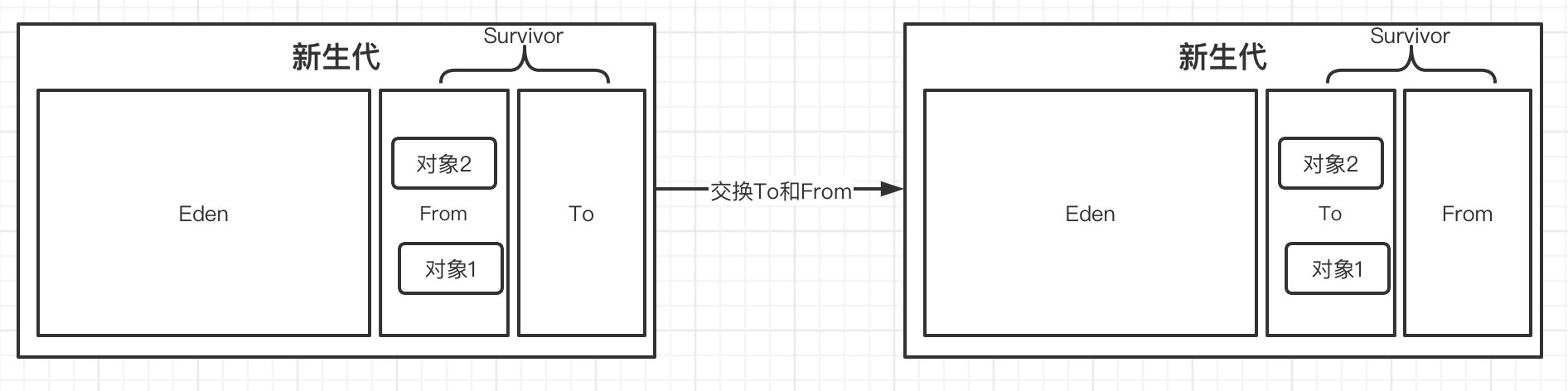
接着就是下一次垃圾回收了,操作与上面是一样的,不过这时由于我们From区域中已经存在对象了,所以,在Eden区的存活对象复制到From区之后,所有To区域中的对象会进行年龄判定(每经历一轮GC年龄
+1,如果对象的年龄大于默认值为15,那么会直接进入到老年代,否则移动到From区)
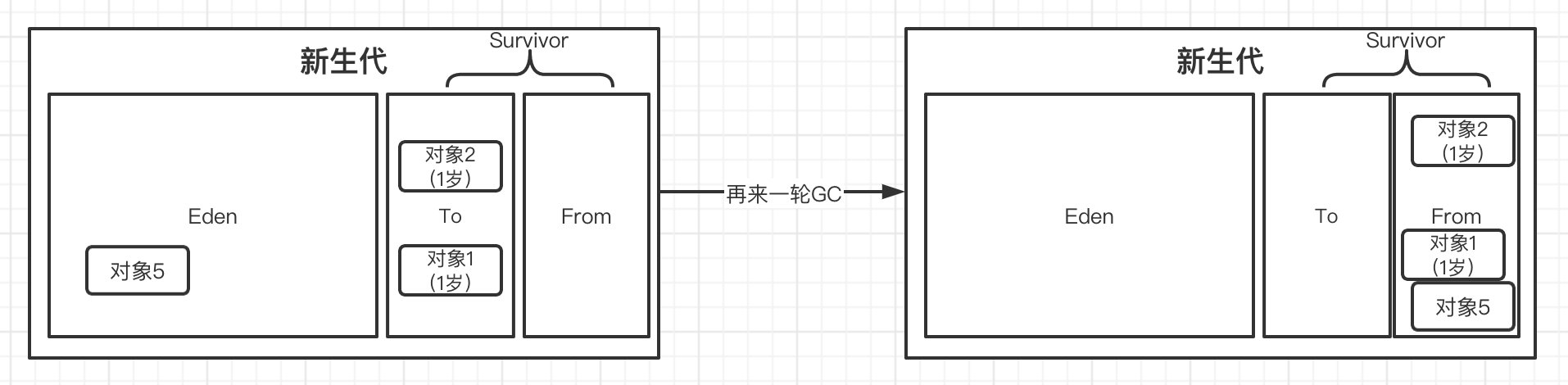
最后像上面一样交换To区和From区,之后不断重复以上步骤。
而垃圾收集也分为:
- Minor GC - 次要垃圾回收,主要进行新生代区域的垃圾收集。
- 触发条件:新生代的Eden区容量已满时。
- Major GC - 主要垃圾回收,主要进行老年代的垃圾收集。
- Full GC - 完全垃圾回收,对整个Java堆内存和方法区进行垃圾回收。
- 触发条件1:每次晋升到老年代的对象平均大小大于老年代剩余空间
- 触发条件2:Minor GC后存活的对象超过了老年代剩余空间
- 触发条件3:永久代内存不足(JDK8之前)
- 触发条件4:手动调用
System.gc()方法
我们可以添加启动参数来查看JVM的GC日志:

javapublic class Main { public static void main(String[] args) { Object o = new Object(); o = null; System.gc(); } } ```[GC (System.gc()) [PSYoungGen: 2621K->528K(76288K)] 2621K->528K(251392K), 0.0006874 secs] [Times: user=0.01 sys=0.01, real=0.00 secs] [Full GC (System.gc()) [PSYoungGen: 528K->0K(76288K)] [ParOldGen: 0K->332K(175104K)] 528K->332K(251392K), [Metaspace: 3073K->3073K(1056768K)], 0.0022693 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] Heap PSYoungGen total 76288K, used 3277K [0x000000076ab00000, 0x0000000770000000, 0x00000007c0000000) eden space 65536K, 5% used [0x000000076ab00000,0x000000076ae334d8,0x000000076eb00000) from space 10752K, 0% used [0x000000076eb00000,0x000000076eb00000,0x000000076f580000) to space 10752K, 0% used [0x000000076f580000,0x000000076f580000,0x0000000770000000) ParOldGen total 175104K, used 332K [0x00000006c0000000, 0x00000006cab00000, 0x000000076ab00000) object space 175104K, 0% used [0x00000006c0000000,0x00000006c00532d8,0x00000006cab00000) Metaspace used 3096K, capacity 4496K, committed 4864K, reserved 1056768K class space used 333K, capacity 388K, committed 512K, reserved 1048576K
空间分配担保机制
在一次GC后,新生代Eden区仍然存在大量的对象(因为GC之后存活对象会进入到一个Survivor区,但是很明显这时已经超出Survivor区的容量了,肯定是装不下的)那么现在该怎么办?
这时就需要用到空间分配担保机制了,可以把Survivor区无法容纳的对象直接送到老年代,让老年代进行分配担保(当然老年代也得装得下才行)在现实生活中,贷款会指定担保人,就是当借款人还不起钱的时候由担保人来还钱。
当新生代无法容纳更多的的对象时,可以把新生代中的对象移动到老年代中,这样新生代就腾出了空间来容纳更多的对象。
好,那既然新生代装不下就丢给老年代,那么要是老年代也装不下新生代的数据呢?这时,老年代肯定担保人是当不成了,那么这样的话,首先会判断一下之前的每次垃圾回收进入老年代的平均大小是否小于当前老年代的剩余空间,如果小于,那么说明也许可以放得下(不过也仅仅是也许,依然有可能放不下,因为判断的实际上只是平均值,万一这一次突然非常大呢),否则,会先来一次Full GC,进行一次大规模垃圾回收,来尝试腾出空间,再次判断老年代是否有空间存放,要是还是装不下,直接抛出OOM错误。
总结一下一次Minor GC的整个过程:

垃圾回收算法
标记-清除算法
首先标记出所有需要回收的对象,然后再依次回收掉被标记的对象,或是标记出所有不需要回收的对象,只回收未标记的对象。
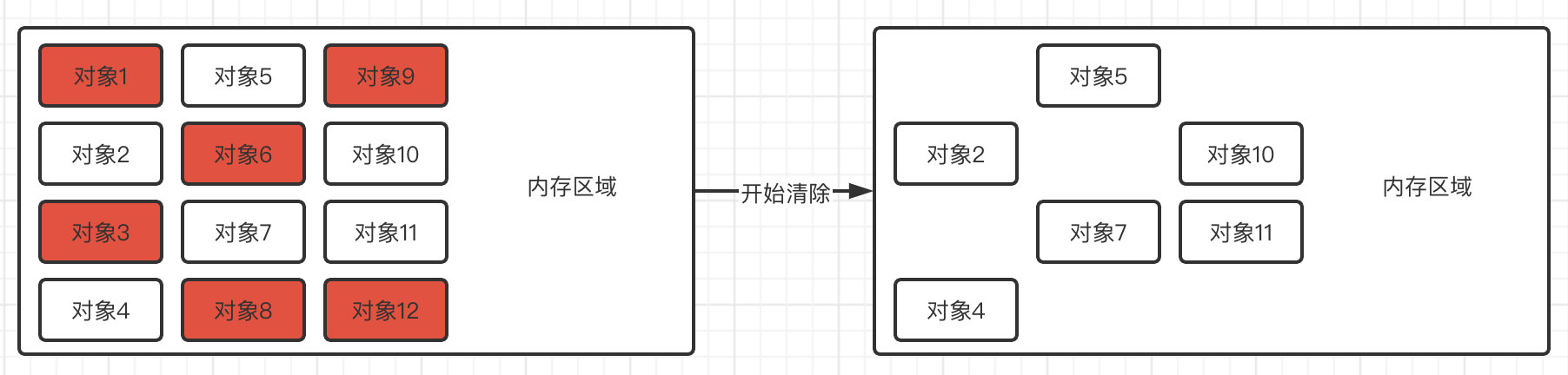
此方法非常简单,但是缺点也是非常明显的 ,首先如果内存中存在大量的对象,那么可能就会存在大量的标记,并且大规模进行清除。并且一次标记清除之后,连续的内存空间可能会出现许许多多的空隙,碎片化会导致连续内存空间利用率降低。
标记-复制算法
标记复制算法,实际上就是将内存区域划分为大小相同的两块区域,每次只使用其中的一块区域,每次垃圾回收结束后,将所有存活的对象全部复制到另一块区域中,并一次性清空当前区域。虽然浪费了一些时间进行复制操作,但是这样能够很好地解决对象大面积回收后空间碎片化严重的问题。

这种算法就非常适用于新生代(因为新生代的回收效率极高,一般不会留下太多的对象)的垃圾回收,而我们之前所说的新生代Survivor区其实就是这个思路,包括8:1:1的比例也正是为了对标记复制算法进行优化而采取的。
标记-整理算法
虽然标记-复制算法能够很好地应对新生代高回收率的场景,但是放到老年代,它就显得很鸡肋了。我们知道,一般长期都回收不到的对象,才有机会进入到老年代,所以老年代一般都是些钉子户,可能一次GC后,仍然存留很多对象。而标记复制算法会在GC后完整复制整个区域内容,并且会折损50%的区域,显然这并不适用于老年代。
那么我们能否这样,在标记所有待回收对象之后,不急着去进行回收操作,而是将所有待回收的对象整齐排列在一段内存空间中,而需要回收的对象全部往后丢,这样,前半部分的所有对象都是无需进行回收的,而后半部分直接一次性清除即可。

虽然这样能保证内存空间充分使用,并且也没有标记复制算法那么繁杂,但是缺点也是显而易见的,它的效率比前两者都低。甚至,由于需要修改对象在内存中的位置,此时程序必须要暂停才可以,在极端情况下,可能会导致整个程序发生停顿(被称为“Stop The World”)。
所以,我们可以将标记清除算法和标记整理算法混合使用,在内存空间还不是很凌乱的时候,采用标记清除算法其实是没有多大问题的,当内存空间凌乱到一定程度后,我们可以进行一次标记整理算法。
垃圾收集器
Serial收集器
在JDK1.3.1之前,是虚拟机新生代区域收集器的唯一选择。这是一款单线程的垃圾收集器,也就是说,当开始进行垃圾回收时,需要暂停所有的线程,直到垃圾收集工作结束。它的新生代收集算法采用的是标记复制算法,老年代采用的是标记整理算法。

可以看到,当进入到垃圾回收阶段时,所有的用户线程必须等待GC线程完成工作,就相当于你打一把LOL 40分钟,中途每隔1分钟网络就卡5秒钟,可能这时你正在打团,结果你被物理控制直接在那里站了5秒钟,这确实让人难以接受。
虽然缺点很明显,但是优势也是显而易见的:
- 设计简单而高效。
- 在用户的桌面应用场景中,内存一般不大,可以在较短时间内完成垃圾收集,只要不频繁发生,使用串行回收器是可以接受的。
所以,在客户端模式(一般用于一些桌面级图形化界面应用程序)下的新生代中,默认垃圾收集器至今依然是Serial收集器。我们可以在
java -version中查看默认的客户端模式:openjdk version "1.8.0_322" OpenJDK Runtime Environment (Zulu 8.60.0.21-CA-macos-aarch64) (build 1.8.0_322-b06) OpenJDK 64-Bit Server VM (Zulu 8.60.0.21-CA-macos-aarch64) (build 25.322-b06, mixed mode)我们可以在jvm.cfg文件中切换JRE为Server VM或是Client VM,默认路径为:
JDK安装目录/jre/lib/jvm.cfg比如我们需要将当前模式切换为客户端模式,那么我们可以这样编辑:
-client KNOWN -server IGNORE
ParNew收集器
这款垃圾收集器相当于是Serial收集器的多线程版本,它能够支持多线程垃圾收集:

除了多线程支持以外,其他内容基本与Serial收集器一致,并且目前某些JVM默认的服务端模式新生代收集器就是使用的ParNew收集器。
Parallel Scavenge/Parallel Old收集器
Parallel Scavenge同样是一款面向新生代的垃圾收集器,同样采用标记复制算法实现,在JDK6时也推出了其老年代收集器Parallel Old,采用标记整理算法实现:

与ParNew收集器不同的是,它会自动衡量一个吞吐量,并根据吞吐量来决定每次垃圾回收的时间,这种自适应机制,能够很好地权衡当前机器的性能,根据性能选择最优方案。
目前JDK8采用的就是这种 Parallel Scavenge + Parallel Old 的垃圾回收方案
CMS收集器
在JDK1.5,HotSpot推出了一款在强交互应用中几乎可认为有划时代意义的垃圾收集器:CMS(Concurrent-Mark-Sweep)收集器,这款收集器是HotSpot虚拟机中第一款真正意义上的并发(注意这里的并发和之前的并行是有区别的,并发可以理解为同时运行用户线程和GC线程,而并行可以理解为多条GC线程同时工作)收集器,它第一次实现了让垃圾收集线程与用户线程同时工作。
它主要采用标记清除算法:

它的垃圾回收分为4个阶段:
- 初始标记(需要暂停用户线程):这个阶段的主要任务仅仅只是标记出GC Roots能直接关联到的对象,速度比较快,不用担心会停顿太长时间。
- 并发标记:从GC Roots的直接关联对象开始遍历整个对象图的过程,这个过程耗时较长但是不需要停顿用户线程,可以与垃圾收集线程一起并发运行。
- 重新标记(需要暂停用户线程):由于并发标记阶段可能某些用户线程会导致标记产生变得,因此这里需要再次暂停所有线程进行并行标记,这个时间会比初始标记时间长一丢丢。
- 并发清除:最后就可以直接将所有标记好的无用对象进行删除,因为这些对象程序中也用不到了,所以可以与用户线程并发运行。
虽然它的优点非常之大,但是缺点也是显而易见的,我们之前说过,标记清除算法会产生大量的内存碎片,导致可用连续空间逐渐变少,长期这样下来,会有更高的概率触发Full GC,并且在与用户线程并发执行的情况下,也会占用一部分的系统资源,导致用户线程的运行速度一定程度上减慢。
不过,如果你希望的是最低的GC停顿时间,这款垃圾收集器无疑是最佳选择,不过自从G1收集器问世之后,CMS收集器不再推荐使用了。
G1收集器
此垃圾收集器也是一款划时代的垃圾收集器,在JDK7的时候正式走上历史舞台,它是一款主要面向于服务端的垃圾收集器,并且在JDK9时,取代了JDK8默认的 Parallel Scavenge + Parallel Old 的回收方案。
垃圾回收分为
Minor GC、Major GC和Full GC,它们分别对应的是新生代,老年代和整个堆内存的垃圾回收,而G1收集器巧妙地绕过了这些约定,它将整个Java堆划分成2048个大小相同的独立Region块,每个Region块的大小根据堆空间的实际大小而定,整体被控制在1MB到32MB之间,且都为2的N次幂。所有的Region大小相同,且在JVM的整个生命周期内不会发生改变。每一个
Region都可以根据需要,自由决定扮演哪个角色(Eden、Survivor和老年代),收集器会根据对应的角色采用不同的回收策略。此外,G1收集器还存在一个Humongous区域,它专门用于存放大对象(一般认为大小超过了Region容量一半的对象为大对象)这样,新生代、老年代在物理上,不再是一个连续的内存区域,而是到处分布的。
它的回收过程与CMS大体类似:
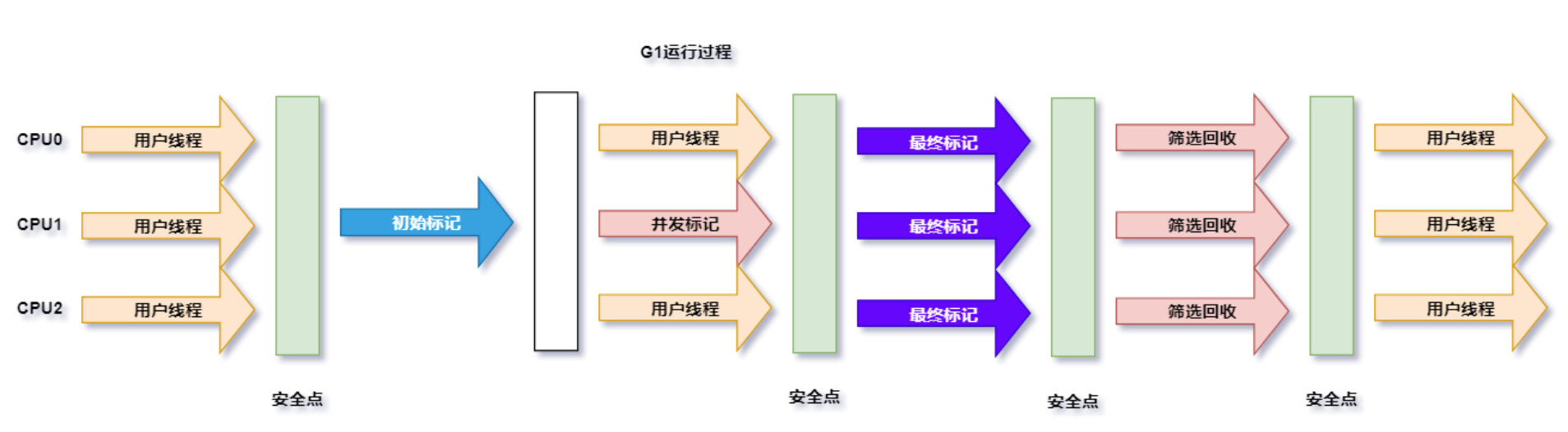
分为以下四个步骤:
- 初始标记(暂停用户线程):仅仅只是标记一下GC Roots能直接关联到的对象,并且修改TAMS指针的值,让下一阶段用户线程并发运行时,能正确地在可用的Region中分配新对象。这个阶段需要停顿线程,但耗时很短,而且是借用进行Minor GC的时候同步完成的,所以G1收集器在这个阶段实际并没有额外的停顿。
- 并发标记:从GC Root开始对堆中对象进行可达性分析,递归扫描整个堆里的对象图,找出要回收的对象,这阶段耗时较长,但可与用户程序并发执行。
- 最终标记(暂停用户线程):对用户线程做一个短暂的暂停,用于处理并发标记阶段漏标的那部分对象。
- 筛选回收:负责更新Region的统计数据,对各个Region的回收价值和成本进行排序,根据用户所期望的停顿时间来制定回收计划,可以自由选择任意多个Region构成回收集,然后把决定回收的那一部分Region的存活对象复制到空的Region中,再清理掉整个旧Region的全部空间。这里的操作涉及存活对象的移动,是必须暂停用户线程,由多个收集器线程并行完成的。
类加载机制
类加载流程
一般在这些情况下,如果类没有被加载,那么会被自动加载:
- 使用new关键字创建对象时
- 使用某个类的静态成员(包括方法和字段)的时候(当然,final类型的静态字段有可能在编译的时候被放到了当前类的常量池中,这种情况下是不会触发自动加载的)
- 使用反射对类信息进行获取的时候(之前的数据库驱动就是这样的)
- 加载一个类的子类时
- 加载接口的实现类,且接口带有
default的方法默认实现时
首先类的生命周期一共有7个阶段,而首当其冲的就是加载,加载阶段需要获取此类的二进制数据流,比如我们要从硬盘中读取一个class文件,那么就可以通过文件输入流来获取类文件的byte[],也可以是其他各种途径获取类文件的输入流,甚至网络传输并加载一个类也不是不可以。然后交给类加载器进行加载(类加载器可以是JDK内置的,也可以是开发者自己撸的,后面会详细介绍)类的所有信息会被加载到方法区中,并且在堆内存中会生成一个代表当前类的Class类对象(那么思考一下,同一个Class文件加载的类,是唯一存在的吗?),我们可以通过此对象以及反射机制来访问这个类的各种信息。数组类要稍微特殊一点,通过前面的检验,我没发现数组在创建后是不会导致类加载的,数组类型本身不会通过类加载器进行加载的,不过你既然要往里面丢对象进去,那最终依然是要加载类的。
验证阶段相当于是对加载的类进行一次规范校验(因为一个类并不一定是由我们使用IDEA编译出来的,有可能是像我们之前那样直接用ASM框架写的一个),如果说类的任何地方不符合虚拟机规范,那么这个类是不会验证通过的,如果没有验证机制,那么一旦出现危害虚拟机的操作,整个程序会出现无法预料的后果。
验证阶段,首先是文件格式的验证:
- 是否魔数为CAFEBABE开头。
- 主、次版本号是否可以由当前Java虚拟机运行
- Class文件各个部分的完整性如何。
有关类验证的详细过程,可以参考《深入理解Java虚拟机 第三版》268页。
准备阶段,这个阶段会为类变量分配内存,并为一些字段设定初始值,注意是系统规定的初始值,不是我们手动指定的初始值。
解析阶段,此阶段是将常量池内的符号引用替换为直接引用的过程,也就是说,到这个时候,所有引用变量的指向都是已经切切实实地指向了内存中的对象了。
到这里,链接过程就结束了,也就是说这个时候类基本上已经完成大部分内容的初始化了。
最后就是真正的初始化阶段了,从这里开始,类中的Java代码部分,才会开始执行全部完成之后,类就算是加载完成了。
类加载器
双亲委派模型

jvm对象结构
Java对象在JVM内存中由三块区域组成:对象头、实例数据和对齐填充。
对象头又分为:Mark Word(标记字段)、Class Pointer(类型指针)、数组长度(如果是数组)。
实例数据是对象实际有效信息,包括本类信息和父类信息等。
对齐填充没有特殊含义,由于虚拟机要求 对象起始地址必须是8字节的整数倍,作用仅是字节对齐。
Class Pointer是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
重点关注一下对象头中Mark Word,里面存储了对象的hashcode、锁状态标识、持有锁的线程id、GC分代年龄等。
在32位的虚拟机中,Mark Word的组成如下:
