ShardingJDBC
Sharding-JDBC 官方文档:https://github.com/apache/shardingsphere
ShardingSphere 提供。
SQL解析
当Sharding-JDBC接受到一条SQL语句时,会陆续执行 SQL解析 => 查询优化 => SQL路由 => SQL改写 => SQL执行=> 结果归并 ,最终返回执行结果。
SQL解析过程分为词法解析和语法解析。 词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将SQL转换为抽象语法树。
供分片使用的解析上下文包含查询选择项(Select Items)、表信息(Table)、分片条件(Sharding Condition)、 自增主键信息(Auto increment Primary Key)、排序信息(Order By)、分组信息(Group By)以及分页信息(Limit、Rownum、Top)。
SQL路由
SQL改写
SQL执行
结果归并
分布式事务
Sharding-JDBC 提供了两种 柔性事务:
- 最大努力送达型 BED :已经实现
- 事务补偿型 TCC :计划中
最大努力送达型
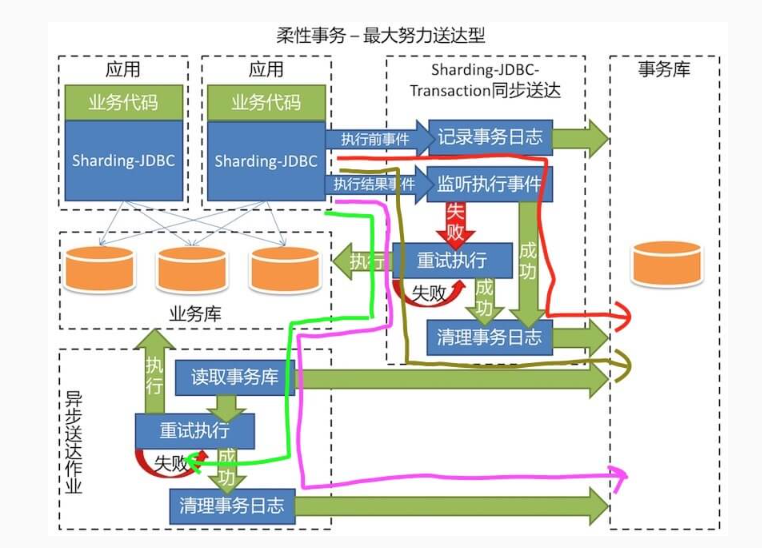
执行过程有 四种 情况:
- 【红线】执行成功
- 【棕线】执行失败,同步重试成功
- 【粉线】执行失败,同步重试失败,异步重试成功
- 【绿线】执行失败,同步重试失败,异步重试失败,事务日志保留
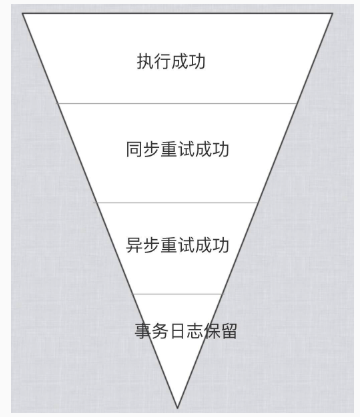
整体成漏斗倒三角,上一个阶段失败,交给下一个阶段重试:
整个过程通过如下 组件 完成:
- 柔性事务管理器
- 最大努力送达型柔性事务
- 最大努力送达型事务监听器
- 事务日志存储器
- 最大努力送达型异步作业