ShardingJDBC-示例
需求说明
将 orders 订单表,拆分到 2 个库,每个库 4 个订单表,一共 8 个表。库表的情况如下:
orders_0 库
├── orders_0
└── orders_2
└── orders_4
└── orders_6
orders_1 库
├── orders_1
└── orders_3
└── orders_5
└── orders_7orders_0 库
├── orders_0
└── orders_2
└── orders_4
└── orders_6
orders_1 库
├── orders_1
└── orders_3
└── orders_5
└── orders_7- 偶数后缀的表,在
orders_0库下。 - 奇数后缀的表,在
orders_1库下。
使用订单表上的 user_id 用户编号,进行分库分表的规则:
- 首先,按照
index = user_id % 2计算,将记录路由到orders_${index}库。 - 然后,按照
index = user_id % 8计算,将记录路由到orders_${index}表。
部分表不需要分库分表,例如说 order_config 订单配置表,所以我们会配置路由到 orders_0 库下。
数据准备
在 orders_0 数据库下,创建 orders_0、orders_2、orders_4、orders_6 数据表。SQL 如下:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP TABLE IF EXISTS `orders_0`;
CREATE TABLE `orders_0` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
DROP TABLE IF EXISTS `orders_2`;
CREATE TABLE `orders_2` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
DROP TABLE IF EXISTS `orders_4`;
CREATE TABLE `orders_4` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
DROP TABLE IF EXISTS `orders_6`;
CREATE TABLE `orders_6` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
SET FOREIGN_KEY_CHECKS = 1;SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP TABLE IF EXISTS `orders_0`;
CREATE TABLE `orders_0` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
DROP TABLE IF EXISTS `orders_2`;
CREATE TABLE `orders_2` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
DROP TABLE IF EXISTS `orders_4`;
CREATE TABLE `orders_4` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
DROP TABLE IF EXISTS `orders_6`;
CREATE TABLE `orders_6` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
SET FOREIGN_KEY_CHECKS = 1;在 orders_1 数据库下,创建 orders_1、orders_3、orders_5、orders_7 数据表。SQL 如下:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP TABLE IF EXISTS `orders_1`;
CREATE TABLE `orders_1` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=400675304294580226 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
DROP TABLE IF EXISTS `orders_3`;
CREATE TABLE `orders_3` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
DROP TABLE IF EXISTS `orders_5`;
CREATE TABLE `orders_5` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
DROP TABLE IF EXISTS `orders_7`;
CREATE TABLE `orders_7` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
SET FOREIGN_KEY_CHECKS = 1;SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP TABLE IF EXISTS `orders_1`;
CREATE TABLE `orders_1` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=400675304294580226 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
DROP TABLE IF EXISTS `orders_3`;
CREATE TABLE `orders_3` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
DROP TABLE IF EXISTS `orders_5`;
CREATE TABLE `orders_5` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
DROP TABLE IF EXISTS `orders_7`;
CREATE TABLE `orders_7` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
SET FOREIGN_KEY_CHECKS = 1;在 orders_0 数据库下,创建 order_config 数据表。SQL 如下:
DROP TABLE IF EXISTS `order_config`;
CREATE TABLE `order_config` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '编号',
`pay_timeout` int(11) DEFAULT NULL COMMENT '支付超时时间;单位:分钟',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单配置表';DROP TABLE IF EXISTS `order_config`;
CREATE TABLE `order_config` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '编号',
`pay_timeout` int(11) DEFAULT NULL COMMENT '支付超时时间;单位:分钟',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单配置表';Pom依赖
<!-- 实现对 Sharding-JDBC 的自动化配置 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC2</version>
</dependency><!-- 实现对 Sharding-JDBC 的自动化配置 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC2</version>
</dependency>实体类
/**
* 订单 DO
*/
@Data
public class OrderDO {
/**
* 订单编号
*/
private Long id;
/**
* 用户编号
*/
private Integer userId;
}/**
* 订单 DO
*/
@Data
public class OrderDO {
/**
* 订单编号
*/
private Long id;
/**
* 用户编号
*/
private Integer userId;
}/**
* 订单配置 DO
*/
@Data
public class OrderConfigDO {
/**
* 编号
*/
private Integer id;
/**
* 支付超时时间
*
* 单位:分钟
*/
private Integer payTimeout;
}/**
* 订单配置 DO
*/
@Data
public class OrderConfigDO {
/**
* 编号
*/
private Integer id;
/**
* 支付超时时间
*
* 单位:分钟
*/
private Integer payTimeout;
}Mapper类
@Mapper
public interface OrderMapper {
OrderDO selectById(@Param("id") Integer id);
List<OrderDO> selectListByUserId(@Param("userId") Integer userId);
void insert(OrderDO order);
}@Mapper
public interface OrderMapper {
OrderDO selectById(@Param("id") Integer id);
List<OrderDO> selectListByUserId(@Param("userId") Integer userId);
void insert(OrderDO order);
}@Mapper
public interface OrderConfigMapper {
OrderConfigDO selectById(@Param("id") Integer id);
}@Mapper
public interface OrderConfigMapper {
OrderConfigDO selectById(@Param("id") Integer id);
}在 resources/mapper 路径下,创建 OrderMapper.xml OrderConfigMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.open.sharding.mapper.OrderMapper">
<sql id="FIELDS">
id, user_id
</sql>
<select id="selectById" parameterType="Integer" resultType="OrderDO">
SELECT
<include refid="FIELDS" />
FROM orders
WHERE id = #{id}
</select>
<select id="selectListByUserId" parameterType="Integer" resultType="OrderDO">
SELECT
<include refid="FIELDS" />
FROM orders
WHERE user_id = #{userId}
</select>
<insert id="insert" parameterType="OrderDO" useGeneratedKeys="true" keyProperty="id">
INSERT INTO orders (
user_id
) VALUES (
#{userId}
)
</insert>
</mapper><?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.open.sharding.mapper.OrderMapper">
<sql id="FIELDS">
id, user_id
</sql>
<select id="selectById" parameterType="Integer" resultType="OrderDO">
SELECT
<include refid="FIELDS" />
FROM orders
WHERE id = #{id}
</select>
<select id="selectListByUserId" parameterType="Integer" resultType="OrderDO">
SELECT
<include refid="FIELDS" />
FROM orders
WHERE user_id = #{userId}
</select>
<insert id="insert" parameterType="OrderDO" useGeneratedKeys="true" keyProperty="id">
INSERT INTO orders (
user_id
) VALUES (
#{userId}
)
</insert>
</mapper><?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.open.sharding.mapper.OrderConfigMapper">
<sql id="FIELDS">
id, pay_timeout
</sql>
<select id="selectById" parameterType="Integer" resultType="OrderConfigDO">
SELECT
<include refid="FIELDS" />
FROM order_config
WHERE id = #{id}
</select>
</mapper><?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.open.sharding.mapper.OrderConfigMapper">
<sql id="FIELDS">
id, pay_timeout
</sql>
<select id="selectById" parameterType="Integer" resultType="OrderConfigDO">
SELECT
<include refid="FIELDS" />
FROM order_config
WHERE id = #{id}
</select>
</mapper>全局配置文件
spring:
# ShardingSphere 配置项
shardingsphere:
datasource:
# 所有数据源的名字
names: ds-orders-0, ds-orders-1
# 订单 orders 数据源配置 00
ds-orders-0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/orders_0?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: xxxxxx
# 订单 orders 数据源配置 01
ds-orders-1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/orders_1?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: xxxxxx
# 分片规则
sharding:
tables:
# orders 表配置
orders:
# 映射到 ds-orders-0 和 ds-orders-1 数据源的 orders 表们
actualDataNodes: ds-orders-0.orders_$->{[0,2,4,6]}, ds-orders-1.orders_$->{[1,3,5,7]}
key-generator: # 主键生成策略
column: id
type: SNOWFLAKE
database-strategy:
inline:
algorithm-expression: ds-orders-$->{user_id % 2}
sharding-column: user_id
table-strategy:
inline:
algorithm-expression: orders_$->{user_id % 8}
sharding-column: user_id
# order_config 表配置
order_config:
# 仅映射到 ds-orders-0 数据源的 order_config 表
actualDataNodes: ds-orders-0.order_config
# 拓展属性配置
props:
sql:
show: true # 打印 SQL
# mybatis-plus 配置内容
mybatis-plus:
configuration:
map-underscore-to-camel-case: true # 默认为 true
global-config:
db-config:
id-type: none # 虽然 MyBatis Plus 也提供 ID 生成策略,但是还是使用 Sharding-JDBC 的
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
mapper-locations: classpath*:mapper/*.xml
type-aliases-package: com.open.sharding.pojo
logging:
level:
root: infospring:
# ShardingSphere 配置项
shardingsphere:
datasource:
# 所有数据源的名字
names: ds-orders-0, ds-orders-1
# 订单 orders 数据源配置 00
ds-orders-0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/orders_0?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: xxxxxx
# 订单 orders 数据源配置 01
ds-orders-1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/orders_1?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: xxxxxx
# 分片规则
sharding:
tables:
# orders 表配置
orders:
# 映射到 ds-orders-0 和 ds-orders-1 数据源的 orders 表们
actualDataNodes: ds-orders-0.orders_$->{[0,2,4,6]}, ds-orders-1.orders_$->{[1,3,5,7]}
key-generator: # 主键生成策略
column: id
type: SNOWFLAKE
database-strategy:
inline:
algorithm-expression: ds-orders-$->{user_id % 2}
sharding-column: user_id
table-strategy:
inline:
algorithm-expression: orders_$->{user_id % 8}
sharding-column: user_id
# order_config 表配置
order_config:
# 仅映射到 ds-orders-0 数据源的 order_config 表
actualDataNodes: ds-orders-0.order_config
# 拓展属性配置
props:
sql:
show: true # 打印 SQL
# mybatis-plus 配置内容
mybatis-plus:
configuration:
map-underscore-to-camel-case: true # 默认为 true
global-config:
db-config:
id-type: none # 虽然 MyBatis Plus 也提供 ID 生成策略,但是还是使用 Sharding-JDBC 的
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
mapper-locations: classpath*:mapper/*.xml
type-aliases-package: com.open.sharding.pojo
logging:
level:
root: info在
spring.shardingsphere配置项下,设置sharding-jdbc-spring-boot-starter自动化配置 Sharding-JDBC 需要的参数。spring.shardingsphere.datasource配置项,我们配置了ds-orders-0和ds-orders-1两个数据源,分别对应orders_0和orders_1两个数据库。spring.shardingsphere.sharding配置项,我们配置了orders和order_config逻辑表 。逻辑表 :水平拆分的数据库(表)的相同逻辑和数据结构表的总称。逻辑表名为
orders。真实表 :在分片的数据库中真实存在的物理表。即示例中的
orders_0到orders_7。数据节点 :数据分片的最小单元。由数据源名称和数据表组成,例:
ds-orders-0.orders_0。orders配置项,设置orders逻辑表,使用分库分表的规则。actualDataNodes:对应的数据节点,使用的是行表达式 。ds-orders-0.orders_0,ds-orders-0.orders_2,ds-orders-0.orders_4,ds-orders-0.orders_6;ds-orders-1.orders_1,ds-orders-1.orders_3,ds-orders-1.orders_5,ds-orders-1.orders_7key-generator:主键生成策略。这里采用分布式主键 SNOWFLAKE 方案。参考 《 ShardingSphere > 概念 & 功能 > 数据分片 > 其他功能 > 分布式主键》 文档。database-strategy:按照index = user_id % 2分库,路由到ds-orders-${index}数据源(库)。table-strategy:index = user_id % 8分表,路由到orders_${index}数据表。
order_config配置项,设置order_config逻辑表,不使用分库分表。actualDataNodes:对应的数据节点,只对应数据源(库)为ds-orders-0的order_config表。
spring.shardingsphere.props配置项,设置拓展属性配置。sql.show:设置打印 SQL
单元测试
OrderConfigMapperTest#testSelectById()
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class OrderConfigMapperTest {
@Autowired
private OrderConfigMapper orderConfigMapper;
@Test
public void testSelectById() {
OrderConfigDO orderConfig = orderConfigMapper.selectById(1);
System.out.println(orderConfig);
}
}@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class OrderConfigMapperTest {
@Autowired
private OrderConfigMapper orderConfigMapper;
@Test
public void testSelectById() {
OrderConfigDO orderConfig = orderConfigMapper.selectById(1);
System.out.println(orderConfig);
}
}执行日志:
2023-02-12 14:02:54.561 INFO 13348 --- [ main] ShardingSphere-SQL : Rule Type: sharding
2023-02-12 14:02:54.561 INFO 13348 --- [ main] ShardingSphere-SQL : `Logic SQL`: SELECT
id, pay_timeout
FROM order_config
WHERE id = ?
2023-02-12 14:02:54.561 INFO 13348 --- [ main] ShardingSphere-SQL : `Actual SQL`: ds-orders-0 ::: SELECT
id, pay_timeout
FROM order_config
WHERE id = ? ::: [1]
OrderConfigDO(id=1, payTimeout=30)2023-02-12 14:02:54.561 INFO 13348 --- [ main] ShardingSphere-SQL : Rule Type: sharding
2023-02-12 14:02:54.561 INFO 13348 --- [ main] ShardingSphere-SQL : `Logic SQL`: SELECT
id, pay_timeout
FROM order_config
WHERE id = ?
2023-02-12 14:02:54.561 INFO 13348 --- [ main] ShardingSphere-SQL : `Actual SQL`: ds-orders-0 ::: SELECT
id, pay_timeout
FROM order_config
WHERE id = ? ::: [1]
OrderConfigDO(id=1, payTimeout=30)- Logic SQL :逻辑 SQL 日志,就是我们编写的。
- Actual SQL :物理 SQL 日志,实际 Sharding-JDBC 向数据库真正发起的日志。
- 在这里,我们可以看到
ds-orders-0,表名该物理 SQL ,是路由到ds-orders-0数据源执行。 - 同时,查询的是
order_config表。 - 符合我们配置的
order_config逻辑表,不使用分库分表,对应的数据节点仅有ds-orders-0.order_config。
- 在这里,我们可以看到
@RunWith(SpringRunner.class)
@SpringBootTest(classes = HelloShardingJdbcApplication.class)
public class OrderMapperTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void testSelectById() {
// 根据订单id查询结果集
OrderDO order = orderMapper.selectById(1);
System.out.println(order);
}
@Test
public void testSelectListByUserId() {
// 根据用户id查询结果集
List<OrderDO> orders = orderMapper.selectListByUserId(1);
System.out.println(orders.size());
}
@Test
public void testInsert() {
OrderDO order = new OrderDO();
order.setUserId(1);
orderMapper.insert(order);
}
}@RunWith(SpringRunner.class)
@SpringBootTest(classes = HelloShardingJdbcApplication.class)
public class OrderMapperTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void testSelectById() {
// 根据订单id查询结果集
OrderDO order = orderMapper.selectById(1);
System.out.println(order);
}
@Test
public void testSelectListByUserId() {
// 根据用户id查询结果集
List<OrderDO> orders = orderMapper.selectListByUserId(1);
System.out.println(orders.size());
}
@Test
public void testInsert() {
OrderDO order = new OrderDO();
order.setUserId(1);
orderMapper.insert(order);
}
}OrderMapperTest#testSelectById()
2023-02-12 14:06:59.063 INFO 12768 --- [ main] ShardingSphere-SQL : Rule Type: sharding
2023-02-12 14:06:59.063 INFO 12768 --- [ main] ShardingSphere-SQL : `Logic SQL`: SELECT
id, user_id
FROM orders
WHERE id = ?
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-0 ::: SELECT
id, user_id
FROM orders_0
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-0 ::: SELECT
id, user_id
FROM orders_2
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-0 ::: SELECT
id, user_id
FROM orders_4
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-0 ::: SELECT
id, user_id
FROM orders_6
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-1 ::: SELECT
id, user_id
FROM orders_1
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-1 ::: SELECT
id, user_id
FROM orders_3
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-1 ::: SELECT
id, user_id
FROM orders_5
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-1 ::: SELECT
id, user_id
FROM orders_7
WHERE id = ? ::: [1]
null2023-02-12 14:06:59.063 INFO 12768 --- [ main] ShardingSphere-SQL : Rule Type: sharding
2023-02-12 14:06:59.063 INFO 12768 --- [ main] ShardingSphere-SQL : `Logic SQL`: SELECT
id, user_id
FROM orders
WHERE id = ?
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-0 ::: SELECT
id, user_id
FROM orders_0
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-0 ::: SELECT
id, user_id
FROM orders_2
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-0 ::: SELECT
id, user_id
FROM orders_4
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-0 ::: SELECT
id, user_id
FROM orders_6
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-1 ::: SELECT
id, user_id
FROM orders_1
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-1 ::: SELECT
id, user_id
FROM orders_3
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-1 ::: SELECT
id, user_id
FROM orders_5
WHERE id = ? ::: [1]
2023-02-12 14:06:59.064 INFO 12768 --- [ main] ShardingSphere-SQL : Actual SQL: ds-orders-1 ::: SELECT
id, user_id
FROM orders_7
WHERE id = ? ::: [1]
null明明只有一条 Logic SQL 操作,却发起了 8 条 Actual SQL 操作。这是为什么呢?
我们使用
id = ?作为查询条件,因为 Sharding-JDBC 解析不到我们配置的user_id片键(分库分表字段),作为查询字段,所以只好 全库表路由 ,查询所有对应的数据节点,也就是配置的所有数据库的数据表。这样,在获得所有查询结果后,通过 归并引擎 合并返回最终结果。通过将 Actual SQL 在每个数据库的数据表执行,返回的结果都是符合条件的。
这样,和使用 Logic SQL 在逻辑表中执行的结果,实际是一致的。
胖友可以试着想一想噢。如果还是有疑惑,可以给艿艿留言。
那么,一次性发起这么多条 Actual SQL 是不是会顺序执行,导致很慢呢?实际上,Sharding-JDBC 有 执行引擎 ,会并行执行这多条 Actual SQL 操作。所以呢,最终操作时长,由最慢的 Actual SQL 所决定。
虽然说,执行引擎 提供了并行执行 Actual SQL 操作的能力,我们还是推荐尽可能查询的时候,带有片键(分库分表字段)。对 Sharding-JDBC 性能感兴趣的胖友,可以看看 《Sharding-JDBC 性能测试报告》 。
OrderMapperTest#testSelectListByUserId()
2023-02-12 14:10:54.621 INFO 13152 --- [ main] ShardingSphere-SQL : Rule Type: sharding
2023-02-12 14:10:54.621 INFO 13152 --- [ main] ShardingSphere-SQL : `Logic SQL`: SELECT
id, user_id
FROM orders
WHERE user_id = ?
2023-02-12 14:10:54.621 INFO 13152 --- [ main] ShardingSphere-SQL : `Actual SQL`: ds-orders-1 ::: SELECT
id, user_id
FROM orders_1
WHERE user_id = ? ::: [1]
22023-02-12 14:10:54.621 INFO 13152 --- [ main] ShardingSphere-SQL : Rule Type: sharding
2023-02-12 14:10:54.621 INFO 13152 --- [ main] ShardingSphere-SQL : `Logic SQL`: SELECT
id, user_id
FROM orders
WHERE user_id = ?
2023-02-12 14:10:54.621 INFO 13152 --- [ main] ShardingSphere-SQL : `Actual SQL`: ds-orders-1 ::: SELECT
id, user_id
FROM orders_1
WHERE user_id = ? ::: [1]
2- 一条 Logic SQL 操作,发起了 1 条 Actual SQL 操作。这是为什么呢?
- 我们使用
user_id = ?作为查询条件,因为 Sharding-JDBC 解析到我们配置的user_id片键(分库分表字段),作为查询字段,所以可以标准路由,仅查询一个数据节点。这种,是 Sharding-JDBC 最为推荐使用的分片方式。- 分库:
user_id % 2 = 1 % 2 = 1,所以路由到ds-orders-1数据源。 - 分表:
user_id % 8 = 1 % 8 = 1,所以路由到orders_1数据表。 - 两者一结合,只查询
ds-orders-1.orders_1数据节点。
- 分库:
OrderMapperTest#testInsert()
2023-02-12 14:13:21.115 INFO 14180 --- [ main] ShardingSphere-SQL : Rule Type: sharding
2023-02-12 14:13:21.115 INFO 14180 --- [ main] ShardingSphere-SQL : `Logic SQL`: INSERT INTO orders (
user_id
) VALUES (
?
)
2023-02-12 14:13:21.116 INFO 14180 --- [ main] ShardingSphere-SQL : `Actual SQL`: ds-orders-1 ::: INSERT INTO orders_1 (
user_id
, id) VALUES (?, ?) ::: [1, 831532516513939457]2023-02-12 14:13:21.115 INFO 14180 --- [ main] ShardingSphere-SQL : Rule Type: sharding
2023-02-12 14:13:21.115 INFO 14180 --- [ main] ShardingSphere-SQL : `Logic SQL`: INSERT INTO orders (
user_id
) VALUES (
?
)
2023-02-12 14:13:21.116 INFO 14180 --- [ main] ShardingSphere-SQL : `Actual SQL`: ds-orders-1 ::: INSERT INTO orders_1 (
user_id
, id) VALUES (?, ?) ::: [1, 831532516513939457]- 不考虑 广播表 的情况下,插入语句必须带有片键(分库分表字段),否则 执行引擎 不知道插入到哪个数据库的哪个数据表中。毕竟,插入操作必然是单库单表。
- 我们会发现,Actual SQL 相比 Logic SQL 来说,增加了主键
id为400772257330233345。这是为什么呢?我们配置orders逻辑表,使用 SNOWFLAKE 算法生成分布式主键,而 改写引擎 在发现我们的 Logic SQL 并未设置插入的id主键编号,它会自动生成主键,改写 Logic SQL ,附加id成 Logic SQL 。
读写分离示例
数据准备
创建表的 SQL 如下:
DROP TABLE IF EXISTS `orders`;
CREATE TABLE `orders` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';DROP TABLE IF EXISTS `orders`;
CREATE TABLE `orders` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';全局配置文件
spring:
# ShardingSphere 配置项
shardingsphere:
# 数据源配置
datasource:
# 所有数据源的名字
names: ds-master, ds-slave-1, ds-slave-2
# 订单 orders 主库的数据源配置
ds-master:
type: com.zaxxer.hikari.HikariDataSource # 使用 Hikari 数据库连接池
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/test_orders?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: xxxxxx
# 订单 orders 从库数据源配置
ds-slave-1:
type: com.zaxxer.hikari.HikariDataSource # 使用 Hikari 数据库连接池
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/test_orders_01?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: xxxxxx
# 订单 orders 从库数据源配置
ds-slave-2:
type: com.zaxxer.hikari.HikariDataSource # 使用 Hikari 数据库连接池
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/test_orders_02?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: xxxxxx
# 读写分离配置,对应 YamlMasterSlaveRuleConfiguration 配置类
masterslave:
name: ms # 名字,任意,需要保证唯一
master-data-source-name: ds-master # 主库数据源
slave-data-source-names: ds-slave-1, ds-slave-2 # 从库数据源
# 拓展属性配置
props:
sql:
show: true # 打印 SQL
# mybatis-plus 配置内容
mybatis-plus:
configuration:
map-underscore-to-camel-case: true # 默认为 true
global-config:
db-config:
id-type: none # 虽然 MyBatis Plus 也提供 ID 生成策略,但是还是使用 Sharding-JDBC 的
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
mapper-locations: classpath*:mapper/*.xml
type-aliases-package: com.open.sharding.pojo
logging:
level:
root: infospring:
# ShardingSphere 配置项
shardingsphere:
# 数据源配置
datasource:
# 所有数据源的名字
names: ds-master, ds-slave-1, ds-slave-2
# 订单 orders 主库的数据源配置
ds-master:
type: com.zaxxer.hikari.HikariDataSource # 使用 Hikari 数据库连接池
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/test_orders?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: xxxxxx
# 订单 orders 从库数据源配置
ds-slave-1:
type: com.zaxxer.hikari.HikariDataSource # 使用 Hikari 数据库连接池
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/test_orders_01?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: xxxxxx
# 订单 orders 从库数据源配置
ds-slave-2:
type: com.zaxxer.hikari.HikariDataSource # 使用 Hikari 数据库连接池
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/test_orders_02?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: xxxxxx
# 读写分离配置,对应 YamlMasterSlaveRuleConfiguration 配置类
masterslave:
name: ms # 名字,任意,需要保证唯一
master-data-source-name: ds-master # 主库数据源
slave-data-source-names: ds-slave-1, ds-slave-2 # 从库数据源
# 拓展属性配置
props:
sql:
show: true # 打印 SQL
# mybatis-plus 配置内容
mybatis-plus:
configuration:
map-underscore-to-camel-case: true # 默认为 true
global-config:
db-config:
id-type: none # 虽然 MyBatis Plus 也提供 ID 生成策略,但是还是使用 Sharding-JDBC 的
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
mapper-locations: classpath*:mapper/*.xml
type-aliases-package: com.open.sharding.pojo
logging:
level:
root: infospring.shardingsphere.datasource配置项下,我们配置了 一个主数据源ds-master、两个从数据源ds-slave-1、ds-slave-2。spring.shardingsphere.masterslave配置项下,配置了读写分离。对于从库来说,Sharding-JDBC 提供了多种负载均衡策略,默认为轮询。- 因为艿艿本地并未搭建 MySQL 一主多从的环境,所以是通过创建了
test_orders_01、test_orders_02库,手动模拟作为test_orders的从库。
单元测试
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class OrderMapperTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void testSelectById() { // 测试从库的负载均衡
for (int i = 0; i < 2; i++) {
OrderDO order = orderMapper.selectById(1);
System.out.println(order);
}
}
@Test
public void testSelectById02() { // 测试强制访问主库
try (HintManager hintManager = HintManager.getInstance()) {
// 设置强制访问主库
hintManager.setMasterRouteOnly();
// 执行查询
OrderDO order = orderMapper.selectById(1);
System.out.println(order);
}
}
@Test
public void testInsert() {
OrderDO order = new OrderDO();
order.setUserId(10);
// 插入
orderMapper.insert(order);
}
}@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class OrderMapperTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void testSelectById() { // 测试从库的负载均衡
for (int i = 0; i < 2; i++) {
OrderDO order = orderMapper.selectById(1);
System.out.println(order);
}
}
@Test
public void testSelectById02() { // 测试强制访问主库
try (HintManager hintManager = HintManager.getInstance()) {
// 设置强制访问主库
hintManager.setMasterRouteOnly();
// 执行查询
OrderDO order = orderMapper.selectById(1);
System.out.println(order);
}
}
@Test
public void testInsert() {
OrderDO order = new OrderDO();
order.setUserId(10);
// 插入
orderMapper.insert(order);
}
}① #testSelectById() 测试方法
// 第 1 次查询
2022-11-11 23:49:27.414 INFO 35306 --- [ main] ShardingSphere-SQL : Rule Type: master-slave
2022-11-11 23:49:27.414 INFO 35306 --- [ main] ShardingSphere-SQL : SQL: SELECT id,user_id FROM orders WHERE id=? ::: DataSources: ds-slave-1
// 第 2 次查询
2022-11-11 23:49:27.454 INFO 35306 --- [ main] ShardingSphere-SQL : Rule Type: master-slave
2022-11-11 23:49:27.454 INFO 35306 --- [ main] ShardingSphere-SQL : SQL: SELECT id,user_id FROM orders WHERE id=? ::: DataSources: ds-slave-2// 第 1 次查询
2022-11-11 23:49:27.414 INFO 35306 --- [ main] ShardingSphere-SQL : Rule Type: master-slave
2022-11-11 23:49:27.414 INFO 35306 --- [ main] ShardingSphere-SQL : SQL: SELECT id,user_id FROM orders WHERE id=? ::: DataSources: ds-slave-1
// 第 2 次查询
2022-11-11 23:49:27.454 INFO 35306 --- [ main] ShardingSphere-SQL : Rule Type: master-slave
2022-11-11 23:49:27.454 INFO 35306 --- [ main] ShardingSphere-SQL : SQL: SELECT id,user_id FROM orders WHERE id=? ::: DataSources: ds-slave-2- 默认情况下,Sharding-JDBC 使用 读写分离 功能时,读取从库。
- 并且,支持从库的负载均衡,默认采用轮询的算法。所以,我们可以看到第 1 次查询
ds-slave-1数据源,第 2 次查询ds-slave-2数据源。
② #testSelectById02() 测试方法
2022-11-11 23:56:09.669 INFO 35430 --- [ main] ShardingSphere-SQL : Rule Type: master-slave
2022-11-11 23:56:09.669 INFO 35430 --- [ main] ShardingSphere-SQL : SQL: SELECT id,user_id FROM orders WHERE id=? ::: DataSources: ds-master2022-11-11 23:56:09.669 INFO 35430 --- [ main] ShardingSphere-SQL : Rule Type: master-slave
2022-11-11 23:56:09.669 INFO 35430 --- [ main] ShardingSphere-SQL : SQL: SELECT id,user_id FROM orders WHERE id=? ::: DataSources: ds-master测试强制访问主库。在一些业务场景下,对数据延迟敏感,所以只能强制读取主库。此时,可以使用
HintManager强制访问主库。- 不过要注意,在使用完后,需要去清理下 HintManager (HintManager 是基于线程变量,透传给 Sharding-JDBC 的内部实现),避免污染下次请求,一直强制访问主库。
- Sharding-JDBC 比较贴心,HintManager 实现了 AutoCloseable 接口,可以通过 Try-with-resources 机制,自动关闭。
③ #testInsert() 测试方法
2022-11-11 23:57:27.046 INFO 35469 --- [ main] ShardingSphere-SQL : Rule Type: master-slave
2022-11-11 23:57:27.047 INFO 35469 --- [ main] ShardingSphere-SQL : SQL: INSERT INTO orders ( id,
user_id ) VALUES ( ?, ? ) ::: DataSources: ds-master2022-11-11 23:57:27.046 INFO 35469 --- [ main] ShardingSphere-SQL : Rule Type: master-slave
2022-11-11 23:57:27.047 INFO 35469 --- [ main] ShardingSphere-SQL : SQL: INSERT INTO orders ( id,
user_id ) VALUES ( ?, ? ) ::: DataSources: ds-master- 写入操作时,直接访问主库
ds-master数据源。
业务测试
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Transactional
public void add(OrderDO order) {
// <1.1> 这里会读取从库
OrderDO exists = orderMapper.selectById(1);
System.out.println(exists);
// <1.2> 插入订单
orderMapper.insert(order);
// <1.3> 这里会读取主库
exists = orderMapper.selectById(1);
System.out.println(exists);
}
public OrderDO findById(Integer id) {
return orderMapper.selectById(id);
}
}@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Transactional
public void add(OrderDO order) {
// <1.1> 这里会读取从库
OrderDO exists = orderMapper.selectById(1);
System.out.println(exists);
// <1.2> 插入订单
orderMapper.insert(order);
// <1.3> 这里会读取主库
exists = orderMapper.selectById(1);
System.out.println(exists);
}
public OrderDO findById(Integer id) {
return orderMapper.selectById(id);
}
}- 在
#add(OrderDO order)方法中,开启事务,插入一条订单记录。<1.1>处,往从库发起一次订单查询。在 Sharding-JDBC 的读写分离策略里,默认读取从库。<1.2>处,往主库发起一次订单写入。写入,肯定是操作主库的。<1.3>处,往主库发起一次订单查询。在 Sharding-JDBC 中,读写分离约定:同一线程且同一数据库连接内,如有写入操作,以后的读操作均从主库读取,用于保证数据一致性。
- 在
#findById(Integer id)方法,往从库发起一次订单查询。
时间分片按照消息ID查询
问题
消息服务中有一张发送记录表,存储了所有消息类型的发送记录。随着时间的推移和业务的迭代,单表数据量将变得越来越大。
当 MySQL 单表数据量越大越大时,会出现以下几个危害:
- 查询效率:随着数据量的增加,查询所需的时间也会逐渐增加,严重影响用户体验。
- 索引效率:对于大表而言,索引的更新、重建以及查询都会变得非常慢。
- 安全隐患:大表容易成为攻击者的攻击目标,例如通过 SQL 注入或者暴力破解的方式。
- 数据备份和恢复的难度增加:单表数据量大,备份和恢复的时间会变得很长,且对于大表进行数据恢复的难度也会增加。
消息服务 mall-message 中消息发送记录表使用时间进行分表操作,一年分为 12 张表,一个月数据在一张表中。
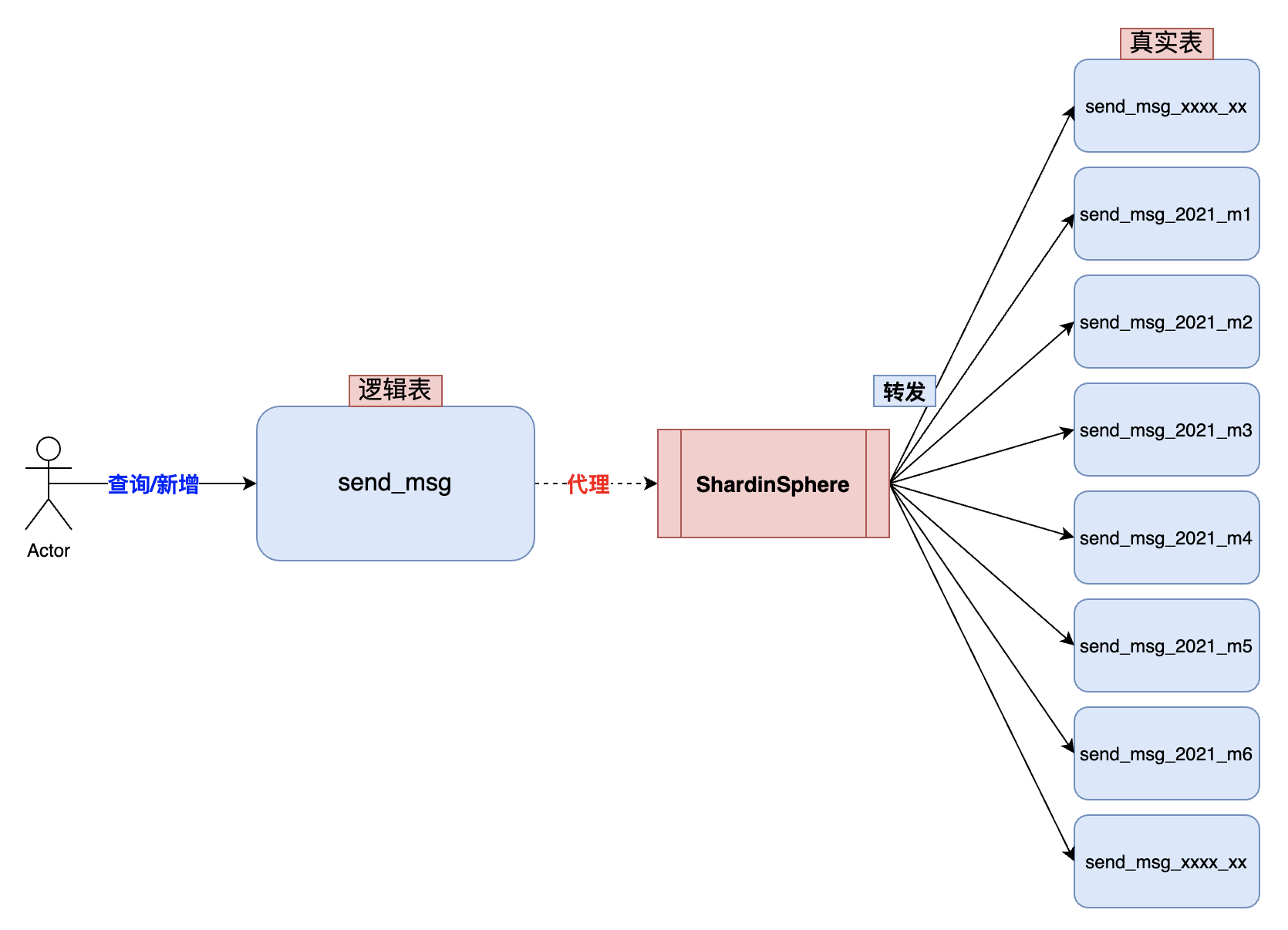
为什么不使用 Hash 分片?
在实际应用中,消息发送记录表不适合采用 Hash 分库分表,主要原因如下:
- 无法支持时间范围查询:采用 Hash 分表后,相同的 Key 值(即哈希值)会被分配到同一个分片中,导致无法通过时间范围查询跨多个分片的数据,因为时间字段并没有参与 Hash 计算。
- 分布不均匀:如果采用消息 ID 作为 Hash 分表的 Key 值,由于消息 ID 一般是雪花算法生成,可能会导致数据分布不均匀,某个分片的数据量过大,而其它分片数据量很少,从而造成负载不均衡,影响系统性能。
因此,对于消息发送记录表这种按照时间字段频繁查询的场景,采用按照时间字段分库分表更为合适。
通过按照时间字段进行范围查询,可以保证数据均匀分布在多个分片中,同时也可以避免 Hash 分表可能导致的数据分布不均的问题。此外,按照时间字段进行分片还能够提高查询性能,使查询更加高效。
难题
消息发送表照时间分库分表,每个库中的表都是按照时间字段分成多个表,后续所有查询中条件必须带上时间字段,否则会走所有真实表扫描。
如果你想查询 2023 年 1 月份的消息发送记录,那么你的条件查询参数就要带上这个日期,语句如下:
SELECT * from send_msg WHERE create_time BETWEEN '2023-01-01 00:00:00' and '2023-01-31 23:59:59'SELECT * from send_msg WHERE create_time BETWEEN '2023-01-01 00:00:00' and '2023-01-31 23:59:59'经过 ShardingSphere 对语句进行分片重组,将逻辑表改写成具体的物理表,语句如下:
SELECT * from send_msg_2023_m1 WHERE create_time BETWEEN '2023-01-01 00:00:00' and '2023-01-31 23:59:59'SELECT * from send_msg_2023_m1 WHERE create_time BETWEEN '2023-01-01 00:00:00' and '2023-01-31 23:59:59'上面说的是正常的场景,但是会存在一种很真实的问题,那就是在消息发送表未进行分表前,曾经提供出去过按照消息 ID 查询的条件。
咱们模拟下如果查询分片表不带分片键会发生什么事情?
用户期望的执行语句是:
SELECT * from send_msg WHERE msg_id = 'xxx'SELECT * from send_msg WHERE msg_id = 'xxx'但是实际执行会变成查询所有物理分表:
SELECT * from send_msg_2022_m1 WHERE msg_id = 'xxx' UNION ALL
SELECT * from send_msg_2022_m2 WHERE msg_id = 'xxx' UNION ALL
SELECT * from send_msg_2022_m3 WHERE msg_id = 'xxx' UNION ALL
SELECT * from send_msg_2022_m4 WHERE msg_id = 'xxx' UNION ALL
SELECT * from send_msg_xxxx_mx WHERE msg_id = 'xxx'SELECT * from send_msg_2022_m1 WHERE msg_id = 'xxx' UNION ALL
SELECT * from send_msg_2022_m2 WHERE msg_id = 'xxx' UNION ALL
SELECT * from send_msg_2022_m3 WHERE msg_id = 'xxx' UNION ALL
SELECT * from send_msg_2022_m4 WHERE msg_id = 'xxx' UNION ALL
SELECT * from send_msg_xxxx_mx WHERE msg_id = 'xxx'这种执行是一种性能深渊,基本上结果查询出来,接口也超时了。如果遇到大批量调用,极有可能把数据库查崩了。
那如何解决这种问题呢?
映射表
将消息 ID 根据时间戳映射到对应的时间表中进行查询,按照月分表,消息 ID 为 t,则可以通过 t%12 得到对应的表名,然后在该表中进行查询。
CREATE TABLE `send_msg_relation` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`send_msg_id` bigint(20) DEFAULT NULL COMMENT '消息ID',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `send_msg_relation` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`send_msg_id` bigint(20) DEFAULT NULL COMMENT '消息ID',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;这样的查询效率比较高,但是需要维护消息 ID 和时间表的映射关系,同时需要处理跨表查询的问题。
而且,时间映射表还存在两个比较明显的缺点:
- 维护映射表,增加了额外的存储和维护成本。
- 数据库查询由之前的一次变成两次,增加了时间查询成本。
有没有一种既能高效查询,又不需要创建映射表的解决方案?
雪花算法
Snowflake 中文的意思是雪花,所以常被称为雪花算法,是 Twitter 开源的分布式 ID 生成算法。
Twitter 雪花算法生成后是一个 64bit 的 long 型的数值,组成部分引入了时间戳,基本保持了自增。

从雪花算法组成部分可以看出,其中包含完整的时间戳。因此,我们可以通过反解析消息 ID 来获取时间戳,并以此作为查询条件来查询对应的创建时间。
大胆设想,细心求证,接下来我们进行反解析试试。
核心原理就是通过位移将对应位数拿到,并取出我们想要的参数。
@Override
public SnowflakeIdInfo parseSnowflakeId(long snowflakeId) {
SnowflakeIdInfo snowflakeIdInfo = SnowflakeIdInfo.builder()
.workerId((int) ((snowflakeId >> WORKER_ID_SHIFT) & ~(-1L << WORKER_ID_BITS)))
.dataCenterId((int) ((snowflakeId >> DATA_CENTER_ID_SHIFT) & ~(-1L << DATA_CENTER_ID_BITS)))
.timestamp((snowflakeId >> TIMESTAMP_LEFT_SHIFT) + DEFAULT_TWEPOCH)
.sequence((int) ((snowflakeId >> SEQUENCE_BIZ_BITS) & ~(-1L << SEQUENCE_ACTUAL_BITS)))
.gene((int) (snowflakeId & ~(-1L << SEQUENCE_BIZ_BITS)))
.build();
return snowflakeIdInfo;
}@Override
public SnowflakeIdInfo parseSnowflakeId(long snowflakeId) {
SnowflakeIdInfo snowflakeIdInfo = SnowflakeIdInfo.builder()
.workerId((int) ((snowflakeId >> WORKER_ID_SHIFT) & ~(-1L << WORKER_ID_BITS)))
.dataCenterId((int) ((snowflakeId >> DATA_CENTER_ID_SHIFT) & ~(-1L << DATA_CENTER_ID_BITS)))
.timestamp((snowflakeId >> TIMESTAMP_LEFT_SHIFT) + DEFAULT_TWEPOCH)
.sequence((int) ((snowflakeId >> SEQUENCE_BIZ_BITS) & ~(-1L << SEQUENCE_ACTUAL_BITS)))
.gene((int) (snowflakeId & ~(-1L << SEQUENCE_BIZ_BITS)))
.build();
return snowflakeIdInfo;
}代码位置:
org.opengoofy.congomall.springboot.starter.distributedid.core.serviceid.DefaultServiceIdGenerator#parseSnowflakeId
可以尝试编写一个单元测试,以确保从消息 ID 中获取的时间戳参数是正确的,并且能够将其转换为对应的创建时间。这个测试可以包含以下步骤:
- 创建一个测试用例,生成一个随机的消息 ID。
- 使用雪花算法从消息 ID 中解析出时间戳参数。
- 将时间戳参数转换为对应的创建时间,并查询数据库获取该消息的创建时间。
- 验证转换后的创建时间与查询到的创建时间是否一致。
如果测试通过,就可以确保按照时间分库分表,并利用消息 ID 进行查询时,能够正确获取对应的创建时间,避免了查询扩散问题。
@Test
public void parseSnowflakeId() {
Snowflake snowflake = new Snowflake(0, 0);
SnowflakeIdUtil.initSnowflake(snowflake);
DefaultServiceIdGenerator defaultServiceIdGenerator = new DefaultServiceIdGenerator();
long nextId = defaultServiceIdGenerator.nextId();
SnowflakeIdInfo snowflakeIdInfo = defaultServiceIdGenerator.parseSnowflakeId(nextId);
System.out.println(snowflakeIdInfo);
}
/**
* SnowflakeIdInfo(timestamp=1288834974657, workerId=0, dataCenterId=0, sequence=0, gene=0)
*/@Test
public void parseSnowflakeId() {
Snowflake snowflake = new Snowflake(0, 0);
SnowflakeIdUtil.initSnowflake(snowflake);
DefaultServiceIdGenerator defaultServiceIdGenerator = new DefaultServiceIdGenerator();
long nextId = defaultServiceIdGenerator.nextId();
SnowflakeIdInfo snowflakeIdInfo = defaultServiceIdGenerator.parseSnowflakeId(nextId);
System.out.println(snowflakeIdInfo);
}
/**
* SnowflakeIdInfo(timestamp=1288834974657, workerId=0, dataCenterId=0, sequence=0, gene=0)
*/测试成功,成功获取了时间戳参数,接下来我们可以利用该时间戳参数获取具体的时间信息,并通过创建时间字段进行查询。
自定义分片算法
可以考虑以下步骤实现该逻辑:
- ShardingSphere 自定义复合分片算法,将
msg_id和create_time作为分片键。 - 通过查询参数消息 ID 拿到雪花算法中的时间戳参数。
- 将时间戳参数转换为具体的时间,可以使用类似
new Date(timestamp)的方式。 - 将时间参数作为条件,查询分库分表后的目标表中的创建时间字段,可以使用类似
SELECT * FROM table WHERE create_time = '2022-01-01 00:00:00'的方式。 - 如果存在多个分表,需要根据消息 ID 和时间戳参数计算出目标表所在的分表,然后在该分表中进行查询操作。
通过上述步骤,就可以实现按照消息 ID 查询分库分表后的目标表了。
分片算法实现
ShardingSphere 分片算法包括单分片算法和复合分片算法,前者适用于单个字段分片,后者适用于多个字段分片。
对于需要使用 msg_id 和 create_time 作为分片键的情况,需要采用复合分片算法。
由于内置的分片算法无法满足特殊场景,因此需要自定义复合分片算法。
ShardingSphere 对 SQL 进行分片的执行流程可以简单概括为以下几个步骤:
- 解析 SQL:将 SQL 解析成逻辑 SQL 对象,包括 SQL 的类型、表名、字段等信息。
- 路由 SQL:根据逻辑 SQL 对象中的表名和分片键等信息,决定将 SQL 发送给哪些数据库进行执行。这个过程就是分片路由,分片路由的结果是一组具体的数据节点列表。
- 合并结果:将分片路由得到的 SQL 分发给各个数据节点执行,然后将结果合并起来,得到最终的结果。
- 返回结果:将最终结果返回给应用程序。
需要注意的是,在分片路由的过程中,ShardingSphere 还会对 SQL 进行一些额外的处理,比如计算分片键的值、将分片键的值转化成数据节点的名称等。这些额外的处理都是为了准确地将 SQL 发送到目标数据节点,确保 SQL 能够被正确地执行。
package org.opengoofy.congomall.biz.message.infrastructure.algorithm;
import cn.hutool.core.collection.CollUtil;
import com.google.common.collect.Range;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingValue;
import org.opengoofy.congomall.springboot.starter.distributedid.SnowflakeIdUtil;
import java.util.Collection;
import java.util.Date;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.Map;
import java.util.Properties;
/**
* 自定义分片算法
*/
public final class SnowflakeDateShardingAlgorithm implements ComplexKeysShardingAlgorithm<Date> {
@Override
public Collection<String> doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
final String messageSendId = "msg_id";
final String sendTime = "create_time";
String logicTableName = shardingValue.getLogicTableName();
Map<String, Collection<Comparable<?>>> columnNameAndShardingValuesMap = shardingValue.getColumnNameAndShardingValuesMap();
Map<String, Range<Comparable<?>>> columnNameAndRangeValuesMap = shardingValue.getColumnNameAndRangeValuesMap();
Collection<String> result = new LinkedHashSet<>(availableTargetNames.size());
if (CollUtil.isNotEmpty(columnNameAndShardingValuesMap)) {
Collection<Comparable<?>> sendTimeCollection = columnNameAndShardingValuesMap.get(sendTime);
if (CollUtil.isNotEmpty(sendTimeCollection)) {
Comparable<?> comparable = sendTimeCollection.stream().findFirst().get();
String actualTable = ShardModel.quarterlyModel(logicTableName, (Date) comparable);
result.add(actualTable);
} else {
Collection<Comparable<?>> messageSendIdCollection = columnNameAndShardingValuesMap.get(messageSendId);
Comparable<?> comparable = messageSendIdCollection.stream().findFirst().get();
String actualTable = ShardModel.quarterlyModel(logicTableName, new Date(SnowflakeIdUtil.parseSnowflakeId(((Long) comparable)).getTimestamp()));
result.add(actualTable);
}
} else {
Range<Comparable<?>> sendTimeRange = columnNameAndRangeValuesMap.get(sendTime);
if (sendTimeRange != null) {
List<String> actualTables = ShardModel.calculateRange(logicTableName, (Date) sendTimeRange.lowerEndpoint(), (Date) sendTimeRange.upperEndpoint());
result.addAll(actualTables);
} else {
result.addAll(availableTargetNames);
}
}
return result;
}
@Override
public Properties getProps() {
return null;
}
@Override
public void init(Properties properties) {
}
@Override
public String getType() {
return "CLASS_BASED";
}
}package org.opengoofy.congomall.biz.message.infrastructure.algorithm;
import cn.hutool.core.collection.CollUtil;
import com.google.common.collect.Range;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingValue;
import org.opengoofy.congomall.springboot.starter.distributedid.SnowflakeIdUtil;
import java.util.Collection;
import java.util.Date;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.Map;
import java.util.Properties;
/**
* 自定义分片算法
*/
public final class SnowflakeDateShardingAlgorithm implements ComplexKeysShardingAlgorithm<Date> {
@Override
public Collection<String> doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
final String messageSendId = "msg_id";
final String sendTime = "create_time";
String logicTableName = shardingValue.getLogicTableName();
Map<String, Collection<Comparable<?>>> columnNameAndShardingValuesMap = shardingValue.getColumnNameAndShardingValuesMap();
Map<String, Range<Comparable<?>>> columnNameAndRangeValuesMap = shardingValue.getColumnNameAndRangeValuesMap();
Collection<String> result = new LinkedHashSet<>(availableTargetNames.size());
if (CollUtil.isNotEmpty(columnNameAndShardingValuesMap)) {
Collection<Comparable<?>> sendTimeCollection = columnNameAndShardingValuesMap.get(sendTime);
if (CollUtil.isNotEmpty(sendTimeCollection)) {
Comparable<?> comparable = sendTimeCollection.stream().findFirst().get();
String actualTable = ShardModel.quarterlyModel(logicTableName, (Date) comparable);
result.add(actualTable);
} else {
Collection<Comparable<?>> messageSendIdCollection = columnNameAndShardingValuesMap.get(messageSendId);
Comparable<?> comparable = messageSendIdCollection.stream().findFirst().get();
String actualTable = ShardModel.quarterlyModel(logicTableName, new Date(SnowflakeIdUtil.parseSnowflakeId(((Long) comparable)).getTimestamp()));
result.add(actualTable);
}
} else {
Range<Comparable<?>> sendTimeRange = columnNameAndRangeValuesMap.get(sendTime);
if (sendTimeRange != null) {
List<String> actualTables = ShardModel.calculateRange(logicTableName, (Date) sendTimeRange.lowerEndpoint(), (Date) sendTimeRange.upperEndpoint());
result.addAll(actualTables);
} else {
result.addAll(availableTargetNames);
}
}
return result;
}
@Override
public Properties getProps() {
return null;
}
@Override
public void init(Properties properties) {
}
@Override
public String getType() {
return "CLASS_BASED";
}
}分片配置
完成自定义分片算法后,需要将其与 ShardingSphere 进行集成,并在 ShardingSphere 的配置文件中设置相应的分片规则。
接下来,可以编写一个简单的测试程序,通过向分片表中插入数据和根据消息 ID 查询数据的方式,来验证分片算法的正确性和可用性。如果测试成功,就可以使用该分片算法来对大表进行分库分表,并实现更高效的数据查询和管理。
spring:
shardingsphere:
datasource:
ds-0:
driver-class-name: com.mysql.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
names: ds-0
props:
sql-show: true
rules:
sharding:
sharding-algorithms:
snowflake_date_algorithm:
props:
algorithmClassName: org.opengoofy.congomall.biz.message.infrastructure.algorithm.SnowflakeDateShardingAlgorithm
strategy: complex
type: CLASS_BASED
tables:
send_record:
actual-data-nodes: ds-0.send_msg_$->{2023..2026}_m$->{1..12}
table-strategy:
complex:
sharding-algorithm-name: snowflake_date_algorithm
sharding-columns: create_time,msg_idspring:
shardingsphere:
datasource:
ds-0:
driver-class-name: com.mysql.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
names: ds-0
props:
sql-show: true
rules:
sharding:
sharding-algorithms:
snowflake_date_algorithm:
props:
algorithmClassName: org.opengoofy.congomall.biz.message.infrastructure.algorithm.SnowflakeDateShardingAlgorithm
strategy: complex
type: CLASS_BASED
tables:
send_record:
actual-data-nodes: ds-0.send_msg_$->{2023..2026}_m$->{1..12}
table-strategy:
complex:
sharding-algorithm-name: snowflake_date_algorithm
sharding-columns: create_time,msg_id验证分库分表
按照时间查询
调用 Apifox 在线接口消息中心目录下-根据条件查询发送结果,在数据库中找到一条记录,假设你找的是 send_record_2023_m4,那么接口入参传递以下:
{
"startTime": "2023-04-01 00:00:00",
"endTime": "2023-04-30 00:00:00",
"receiverList": [
"这个替换成数据库记录 {receiver}"
]
}{
"startTime": "2023-04-01 00:00:00",
"endTime": "2023-04-30 00:00:00",
"receiverList": [
"这个替换成数据库记录 {receiver}"
]
}ShardingSphere 生成的真实 SQL 如下:
SELECT id,msg_id AS messageSendId,template_id,msg_type,sender,receiver,cc,status,send_time,create_time,update_time,del_flag FROM send_record_2023_m4
WHERE del_flag=0
AND (create_time BETWEEN ? AND ? AND receiver IN (?)) ::: [2023-04-01 00:00:00.0, 2023-04-30 00:00:00.0, m7798432@163.com]SELECT id,msg_id AS messageSendId,template_id,msg_type,sender,receiver,cc,status,send_time,create_time,update_time,del_flag FROM send_record_2023_m4
WHERE del_flag=0
AND (create_time BETWEEN ? AND ? AND receiver IN (?)) ::: [2023-04-01 00:00:00.0, 2023-04-30 00:00:00.0, m7798432@163.com]该 Case 成功通过测试,我们可以看到 ShardingSphere 分片规则已经将创建时间字段正确地路由到了对应的真实表中。
按照消息 ID 查询
调用 Apifox 在线接口消息中心目录下-根据消息发送ID查询发送结果,在数据库中找到随意一个消息发送 ID,拼接到 result 路径后 http://localhost:8001/api/message/result/{messageSendId}。
ShardingSphere 生成的真实 SQL 如下:
Actual SQL: ds-0 ::: SELECT id,msg_id AS messageSendId,template_id,msg_type,sender,receiver,cc,status,send_time,create_time,update_time,del_flag FROM send_record_2023_m4
WHERE del_flag=0
AND (msg_id IN (?)) ::: [1643084443437445120]Actual SQL: ds-0 ::: SELECT id,msg_id AS messageSendId,template_id,msg_type,sender,receiver,cc,status,send_time,create_time,update_time,del_flag FROM send_record_2023_m4
WHERE del_flag=0
AND (msg_id IN (?)) ::: [1643084443437445120]使用消息 ID 1643084443437445120 进行时间戳解析,成功定位到数据库真实表 send_record_2023_m4 并完成期望的查询。
通过 ShardingSphere 对消息发送记录表按照时间进行分库分表操作,并通过解析消息 ID 雪花算法中时间戳组成部分,可以依据消息 ID 高效分片查询。具体流程如下:
- 首先,我们需要对消息发送记录表按照时间进行分库分表操作,并将消息 ID 和创建时间作为分片键。
- 接着,我们需要使用自定义复合分片算法,将消息 ID 和创建时间按照一定规则映射到不同的数据库和数据表中。
- 在查询时,我们可以通过解析消息 ID 雪花算法中时间戳组成部分,获得创建时间,再根据创建时间进行查询,从而避免了查询扩散问题。
综上所述,使用 ShardingSphere 对消息发送记录表进行分库分表操作,并结合消息 ID 解析雪花算法中的时间戳组成部分,可以实现高效的分片查询,从而提高数据库的性能和扩展性。