分库分表-概述
为什么要分库分表
针对公司的公司业务发展越好,用户就越多,数据量越大,请求量越大,那你单个数据库一定扛不住
当单表数据量达到千万级别,需要考虑分库分表
比如你单表都几千万数据了,你确定你能扛住么?绝对不行,单表数据量太大,会极大影响你的 sql 执行的性能,到了后面你的 sql 可能就跑的很慢了。一般来说,就以我的经验来看,单表到几百万的时候,性能就会相对差一些了,你就得分表了。
分表是啥意思?就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在 200 万以内。
分库是啥意思?就是你一个库一般我们经验而言,最多支撑到并发 2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
| # | 分库分表前 | 分库分表后 |
|---|---|---|
| 并发支撑情况 | MySQL 单机部署,扛不住高并发 | MySQL 从单机到多机,能承受的并发增加了多倍 |
| 磁盘使用情况 | MySQL 单机磁盘容量几乎撑满 | 拆分为多个库,数据库服务器磁盘使用率大大降低 |
| SQL 执行性能 | 单表数据量太大,SQL 越跑越慢 | 单表数据量减少,SQL 执行效率明显提升 |
中间件选型
比较常见的分库分表中间件包括:
- Cobar
- TDDL
- Atlas
- Sharding-jdbc
- Mycat
| 描述 | 优点 | 缺点 | |
|---|---|---|---|
| Cobar | 阿里 b2b 团队开发和开源的,属于 proxy 层方案,就是介于应用服务器和数据库服务器之间。应用程序通过 JDBC 驱动访问 Cobar 集群,Cobar 根据 SQL 和分库规则对 SQL 做分解,然后分发到 MySQL 集群不同的数据库实例上执行 | 不支持读写分离、存储过程、跨库 join 和分页等操作 | |
| TDDL | 淘宝团队开发的,属于 client 层方案 | 支持基本的 crud 语法和读写分离 | 不支持 join、多表查询等语法,还依赖淘宝的 diamond 配置管理系统 |
| Atlas | 360 开源,属于 proxy 层方案 | 维护都在 5 年前 | |
| Sharding-jdbc | client 层方案,是ShardingSphere的 client 层方案,ShardingSphere还提供 proxy 层的方案 Sharding-Proxy | 支持分库分表、读写分离、分布式 id 生成、柔性事务(最大努力送达型事务、TCC 事务) | |
| Mycat | 基于 Cobar 改造的,属于 proxy 层方案 | 相比于 Sharding jdbc 来说,年轻一些,经历的锤炼少一些 |
总结
综上,现在其实建议考量的,就是 Sharding-jdbc 和 Mycat,这两个都可以去考虑使用。
Sharding-jdbc 这种 client 层方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合 Sharding-jdbc 的依赖;
Mycat 这种 proxy 层方案的缺点在于需要部署,自己运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了。
通常来说,这两个方案其实都可以选用,但是我个人建议中小型公司选用 Sharding-jdbc,client 层方案轻便,而且维护成本低,不需要额外增派人手,而且中小型公司系统复杂度会低一些,项目也没那么多;但是中大型公司最好还是选用 Mycat 这类 proxy 层方案,因为可能大公司系统和项目非常多,团队很大,人员充足,那么最好是专门弄个人来研究和维护 Mycat,然后大量项目直接透明使用即可。
垂直拆分与水平拆分
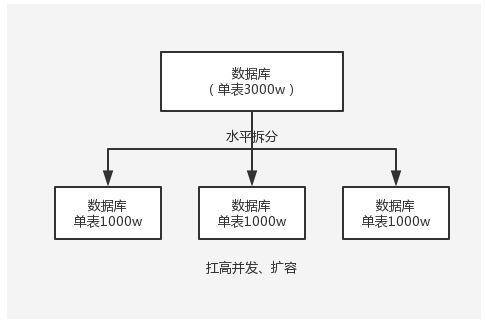
水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来扛更高的并发,还有就是用多个库的存储容量来进行扩容。
垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。

分库分表一般采用的方式:
- 一种是按照 range 来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了。
- 或者是按照某个字段 hash 一下均匀分散(较为常用)
range 来分,好处在于说,扩容的时候很简单,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了;缺点,但是大部分的请求,都是访问最新的数据。实际生产用 range,要看场景。
hash 分发,好处在于说,可以平均分配每个库的数据量和请求压力;坏处在于说扩容起来比较麻烦,会有一个数据迁移的过程,之前的数据需要重新计算 hash 值重新分配到不同的库或表。
分库分表平滑过渡
现有一个未分库分表的系统,未来要分库分表,如何设计才可以让系统从未分库分表动态切换到分库分表?
停机迁移方案
凌晨 12 点开始运维,网站或者 app 挂个公告,说 0 点到早上 6 点进行运维,无法访问。
接着到 0 点停机,系统停掉,没有流量写入了,此时老的单库单表数据库静止了。然后你之前得写好一个导数的一次性工具,此时直接跑起来,然后将单库单表的数据哗哗哗读出来,写到分库分表里面去。
导数完了之后,就 ok 了,修改系统的数据库连接配置啥的,包括可能代码和 SQL 也许有修改,那你就用最新的代码,然后直接启动连到新的分库分表上去。
最后验证一下。

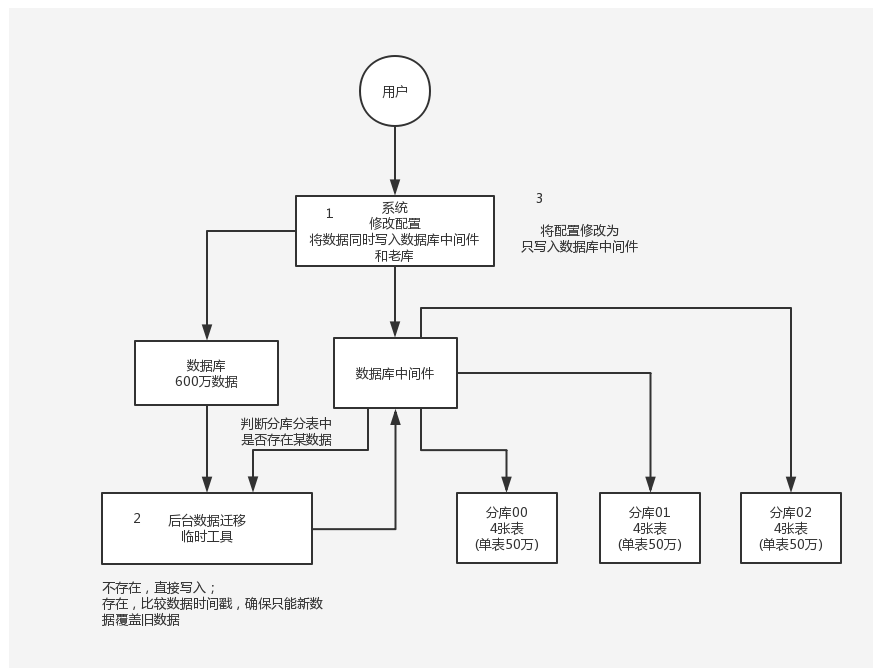
双写迁移方案
在线上系统里面,之前所有写库的地方,增删改操作,除了对老库增删改,都加上对新库的增删改,这就是所谓的双写,同时写俩库,老库和新库。
系统部署之后,新库数据差太远,用之前说的导数工具,跑起来读老库数据写新库,写的时候要根据 gmt_modified 这类字段判断这条数据最后修改的时间,除非是读出来的数据在新库里没有,或者是比新库的数据新才会写。简单来说,就是不允许用老数据覆盖新数据。
导完一轮之后,有可能数据还是存在不一致,那么就程序自动做一轮校验,比对新老库每个表的每条数据,接着如果有不一样的,就针对那些不一样的,从老库读数据再次写。反复循环,直到两个库每个表的数据都完全一致为止。
当数据完全一致了,就 ok 了,基于仅仅使用分库分表的最新代码,重新部署一次,不就仅仅基于分库分表在操作了么,还没有停机时间,是常用的一种迁移方案。
分库分表动态扩容缩容
停机扩容
跟停机迁移一样,步骤几乎一致,唯一的一点就是那个导数的工具,是把现有库表的数据抽出来慢慢倒入到新的库和表里去。但是数据量特别大这种停机扩容的方案是不行的,不推荐使用
优化扩容
- 设定好几台数据库服务器,每台服务器上几个库,每个库多少个表,推荐是 32 库 * 32 表,对于大部分公司来说,可能几年都够了。
- 路由的规则,orderId 模 32 = 库,orderId / 32 模 32 = 表
- 扩容的时候,申请增加更多的数据库服务器,装好 MySQL,呈倍数扩容,4 台服务器,扩到 8 台服务器,再到 16 台服务器。
- 由 DBA 负责将原先数据库服务器的库,迁移到新的数据库服务器上去,库迁移是有一些便捷的工具的。
- 我们这边就是修改一下配置,调整迁移的库所在数据库服务器的地址。
- 重新发布系统,上线,原先的路由规则变都不用变,直接可以基于 n 倍的数据库服务器的资源,继续进行线上系统的提供服务。