redis应用
数据操作
| 操作类型 | 命令示例 | 描述 |
|---|---|---|
| 显示所有的 key | KEYS * | 显示所有的 key。支持通配符 *、前缀 prefix*、后缀 *suffix。 |
| 删除指定的 key | DEL key1 key2 key3 ... | 删除一个或多个指定的 key。 |
| 判断 key 是否存在 | EXISTS key | 判断指定的 key 是否存在。 |
| 设置 key 的有效期 | EXPIRE key 10 | 设置指定 key 的过期时间(单位:秒)。 |
| 显示 key 的有效期 | TTL key | 查看指定 key 的剩余过期时间。 |
| 清空当前数据库 | FLUSHDB | 清空当前选择的数据库。 |
| 清空所有数据库 | FLUSHALL | 清空所有 Redis 数据库。 |
| 切换数据库 | SELECT dbNum | 切换到指定的数据库。 |
| 字符串操作 | ||
| 添加值 | SET key value | 设置指定 key 的值。 |
| 获取值 | GET key | 获取指定 key 的值。 |
| 批量操作 | MSET key1 value1 [key2 value2, key3 value3] | 批量设置多个 key 的值。 |
| 自增 | INCR key | 将 key 的值自增 1。 |
| 自减 | DECR key | 将 key 的值自减 1。 |
| 设置自增/自减增量 | INCRBY key increment | 设置 key 的增量为指定值。 |
| 设置带有效期的值 | SETEX key second value | 设置 key 的同时设置过期时间(单位:秒)。 |
| 仅当 key 不存在时设置 | SETNX key value | 如果 key 不存在则设置,否则不做任何操作。 |
| 追加值到现有值末尾 | APPEND key value | 将指定值追加到 key 原有值的末尾。 |
| 查看值的长度 | STRLEN key | 返回 key 所储存的字符串值的长度。 |
| 哈希操作 | ||
| 存储数据到哈希表 | HSET key field value | 设置 key 指定的哈希集中指定字段的值。 |
| 获取哈希表中的值 | HGET key field | 获取 key 指定的哈希集中指定字段的值。 |
| 批量操作 | HMSET key field value [field value......] | 批量设置 key 的哈希字段及对应的值。 |
| 批量获取 | HMGET key field [field......] | 批量获取 key 的哈希字段对应的值。 |
| 自增 | HINCRBY key field increment | 为 key 的哈希字段自增指定值。 |
| 仅当不存在时设置 | HSETNX key field value | 当 key 的哈希字段不存在时设置值。 |
| 检测字段是否存在 | HEXISTS key field | 检测 key 的哈希字段是否存在。 |
| 删除指定字段 | HDEL key field1, field2...... | 删除 key 的哈希字段。 |
| 获取所有字段及值 | HGETALL key | 获取 key 的所有哈希字段及对应的值。 |
| 获取所有字段 | HKEYS key | 获取 key 的所有哈希字段。 |
| 获取所有值 | HVALS key | 获取 key 的所有哈希字段对应的值。 |
| 获取字段个数 | HLEN key | 获取 key 的哈希字段数量。 |
| 列表操作 | ||
| 头部添加数据 | LPUSH key value [value.......] | 将一个或多个值插入到列表头部。 |
| 尾部添加数据 | RPUSH key value [value.......] | 将一个或多个值插入到列表尾部。 |
| 判断列表是否存在 | LPUSHX key value | 当列表存在时,将值插入到列表头部。 |
| 修改列表指定位置的值 | LSET key index value | 修改列表中指定位置的值。 |
| 获取并删除列表头部值 | LPOP key | 移除并返回列表 key 的头元素。 |
| 获取并删除列表尾部值 | RPOP key | 移除并返回列表 key 的尾元素。 |
| 获取列表指定范围的值 | LRANGE key start stop | 获取列表 key 中指定范围内的所有值。 |
| 获取列表指定位置的值 | LINDEX key index | 获取列表 key 中指定位置的值。 |
| 获取列表长度 | LLEN key | 获取列表 key 的长度。 |
| 删除列表中的值 | LREM key count value | 从列表中删除与参数 value 相等的元素。 |
| 保留指定范围的值 | LTRIM key start stop | 对列表进行修剪,使其只包含指定范围的元素。 |
| 集合操作 | ||
| 存储数据到集合 | SADD key value [value ......] | 向集合添加一个或多个成员。 |
| 获取集合中所有成员 | SMEMBERS key | 返回集合中的所有成员。 |
| 随机获取一个成员 | SPOP key [count] | 移除并返回集合中的一个或多个随机成员。 |
| 计算多个集合的交集 | SINTER set1 set2 ... | 返回给定所有集合的交集。 |
| 计算多个集合的并集 | SUNION set1 set2 ... | 返回给定所有集合的并集。 |
| 计算多个集合的差集 | SDIFF set1 set2 ... | 返回给定所有集合的差集。 |
| 删除集合中的成员 | SREM key value [value.....] | 移除集合中一个或多个成员。 |
| 检查成员是否存在 | SISMEMBER key value | 判断成员是否是集合 key 的成员。 |
| 有序集合操作 | ||
| 添加数据到有序集合 | ZADD key score value [score value.....] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数。 |
| 修改分值 | ZINCRBY key increment value | 为有序集 key 的成员 value 的分数加上增量 increment 。 |
| 获取成员的分值 | ZSCORE key value | 返回有序集 key 中,成员 value 的分数值。 |
| 获取成员个数 | ZCARD key | 返回有序集 key 的基数。 |
| 获取指定范围内的成员 | ZRANGE key start stop [WITHSCORES] | 返回有序集 key 中,指定区间内的成员。 |
| 获取指定范围内的成员 | ZREVRANGE key start stop [WITHSCORES] | 返回有序集 key 中,指定区间内的成员(从大到小排序)。 |
| 计算指定分数范围内的成员数 | ZCOUNT key min max | 返回有序集 key 中,分数介于 min 和 max 之间的成员数。 |
| 删除有序集合中的成员 | ZREM key value | 删除有序 |
数据类型
| 数据结构 | 描述 |
|---|---|
| key-string | 一个 key 对应一个字符串,通常用来存储单个值。 |
| key-hash | 一个 key 对应一个哈希表(Map),通常用来存储对象数据。 |
| key-list | 一个 key 对应一个列表,通常用来实现栈和队列等数据结构。 |
| key-set | 一个 key 对应一个集合,用于实现数据的交集、并集、差集等操作。 |
| key-zset | 一个 key 对应一个有序集合,用于实现带分数的数据存储和排序。 |
| HyperLogLog | 用于基数统计和近似计数的数据结构。 |
| GEO | 用于存储地理位置信息的数据结构。 经度的范围在 (-180, 180],纬度的范围 在(-90, 90] |
| BIT | 用来存储位操作相关的数据,通常存储 byte[] 类型的字符串。 |
| HyperLogLog |
HyperLogLog
#1.统计非重复的字符串个数(占用内存小,计算速度快)
PFADD key value1 value2 value3 ...
PFCOUNT key一个 key 关联了一个数据集合,同时对这个数据集合做统计。
- 统计一个
APP的日活、月活数; - 统计一个页面的每天被多少个不同账户访问量(Unique Visitor,UV));
- 统计用户每天搜索不同词条的个数;
- 统计注册 IP 数。
通常情况下,我们面临的用户数量以及访问量都是巨大的,比如百万、千万级别的用户数量,或者千万级别、甚至亿级别的访问信息。
布隆过滤器
布隆过滤器由n个Hash函数和一个二进制数组组成,主要用于判断一个元素是否在一个集合中
1.初始状态
一开始,二进制数组里是没有值的

2.存储操作
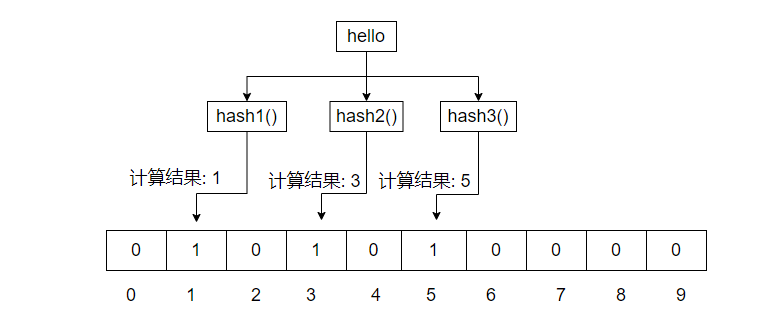
发来一个请求数据hello 对数据hello经过三次hash运算,分别得到三个值(假设1,3,5)。 在对应的二进制数组里,将下标为1,3,5的值置为1。
3.查询操作
发来一个请求数据hello 对数据hello经过三次hash运算,分别得到三个值(假设1,3,5)。 在二进制数组里,将下标为1,3,5的值取出来,如果都为1,则表示该数据已经存在。
4.删除操作
布隆过滤器很难进行删除操作。
如果hash2(hello)结果为3,hash2(world)结果也为3,那么如果删除了hello的值,就意味着world的值也会被其删除。
5.误判率
假设保存两个值,hello和world hello对应的index(也就是hash计算后的值)为1,3,5 world对应的index(也就是hash计算后的值)为2,4,6
而此时来了一个值java,对应的index为1,4,5,查询得出结果:exist(java) = true,但其实,java这个数据并不存在,这就会产生一定的误判。
Redis 官方提供的布隆过滤器到了 Redis 4.0 才正式登场。Redis 4.0 提供了插件功能,布隆过滤器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。
使用Docker进行安装
docker pull redislabs/rebloom:latest # 拉取镜像
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest #运行容器
docker exec -it redis-redisbloom bash
redis-cli使用
布隆过滤器基本指令:
- bf.add 添加元素到布隆过滤器
- bf.exists 判断元素是否在布隆过滤器
- bf.madd 添加多个元素到布隆过滤器,bf.add 只能添加一个
- bf.mexists 判断多个元素是否在布隆过滤器
慢查询日志配置
慢查询日志是存放在Redis内存列表中的, 但是Redis并没有暴露这个列表的键, 而是通过一组命令来实现对慢查询日志的访问和管理。
slowlog get [n] # 获取慢查询日志 参数n可以指定条数127.0.0.1:6379> slowlog get
1) 1) (integer) 666
2) (integer) 1456786500
3) (integer) 11615
4) 1) "BGREWRITEAOF"
2) 1) (integer) 665
2) (integer) 1456718400
3) (integer) 12006
4) 1) "SETEX"
2) "video_info_200"
3) "300"
4) "2"
...每个慢查询日志有4个属性组成, 分别是:
- 慢查询日志的标识id
- 发生时间戳
- 命令耗时
- 执行命令和参数。
# 获取慢查询日志当前长度
slowlog len
# 清理慢查询日志
slowlog reset慢查询功能可以有效地帮助我们找到Redis可能存在的瓶颈,但在实际使用过程中要注意以下几点:
slowlog-max-len配置建议
线上建议调大慢查询列表,记录慢查询时Redis会对长命令做截断操作,并不会占用大量内存。增大慢查询列表可以减小慢查询被剔除的可能,例如线上可设置为1000以上。
slowlog-log-slower-than配置建议
默认值超过10毫秒判定为慢查询,需要根据Redis并发量调整该值。由于Redis采用单线程响应命令,对于高流量的场景,如果命令执行时间在1毫秒以上,那么Redis最多可支撑OPS不到1000。因此对于高OPS场景的Redis建议设置为1毫秒。
慢查询只记录命令执行时间,并不包括命令排队和网络传输时间
此客户端执行命令的时间会大于命令实际执行时间。因为命令执行排队机制,慢查询会导致其他命令级联阻塞,因此当客户端出现请求超时,需要检查该时间点是否有对应的慢查询,从而分析出是否为慢查询导致的命令级联阻塞。
慢查询日志可能会丢失
由于慢查询日志是一个先进先出的队列,也就是说如果慢查询比较多的情况下,可能会丢失部分慢查询命令。为了防止这种情况发生,可以定期执行slowget命令将慢查询日志持久化到其他存储中(例如MySQL),然后可以制作可视化界面进行查询,第13章介绍的Redis私有云CacheCloud提供了这样的功能,好的工具可以让问题排查事半功倍。
redis全局配置
#基本配置
daemonize no 是否以后台进程启动
databases 16 创建database的数量(默认选中的是database 0)
save 900 1 #刷新快照到硬盘中,必须满足两者要求才会触发,即900秒之后至少1个关键字发生变化。
save 300 10 #必须是300秒之后至少10个关键字发生变化。
save 60 10000 #必须是60秒之后至少10000个关键字发生变化。
stop-writes-on-bgsave-error yes #后台存储错误停止写。
rdbcompression yes #使用LZF压缩rdb文件。
rdbchecksum yes #存储和加载rdb文件时校验。
dbfilename dump.rdb #设置rdb文件名。
dir ./ #设置工作目录,rdb文件会写入该目录。
#主从配置
slaveof <masterip> <masterport> 设为某台机器的从服务器
masterauth <master-password> 连接主服务器的密码
slave-serve-stale-data yes # 当主从断开或正在复制中,从服务器是否应答
slave-read-only yes #从服务器只读
repl-ping-slave-period 10 #从ping主的时间间隔,秒为单位
repl-timeout 60 #主从超时时间(超时认为断线了),要比period大
slave-priority 100 #如果master不能再正常工作,那么会在多个slave中,选择优先值最小的一个slave提升为master,优先值为0表示不能提升为master。
repl-disable-tcp-nodelay no #主端是否合并数据,大块发送给slave
slave-priority 100 从服务器的优先级,当主服挂了,会自动挑slave priority最小的为主服
#安全配置
requirepass foobared # 需要密码
rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52 #如果公共环境,可以重命名部分敏感命令 如config
#限制参数
maxclients 10000 #最大连接数
maxmemory <bytes> #最大使用内存
maxmemory-policy volatile-lru #内存到极限后的处理
volatile-lru -> LRU算法删除过期key
allkeys-lru -> LRU算法删除key(不区分过不过期)
volatile-random -> 随机删除过期key
allkeys-random -> 随机删除key(不区分过不过期)
volatile-ttl -> 删除快过期的key
noeviction -> 不删除,返回错误信息
#解释 LRU ttl都是近似算法,可以选N个,再比较最适宜T踢出的数据
maxmemory-samples 3
#日志模式
appendonly no #是否仅要日志
appendfsync no # 系统缓冲,统一写,速度快
appendfsync always # 系统不缓冲,直接写,慢,丢失数据少
appendfsync everysec #折衷,每秒写1次
no-appendfsync-on-rewrite no #为yes,则其他线程的数据放内存里,合并写入(速度快,容易丢失的多)
auto-AOF-rewrite-percentage 100 当前aof文件是上次重写是大N%时重写
auto-AOF-rewrite-min-size 64mb aof重写至少要达到的大小
#慢查询
slowlog-log-slower-than 10000 #记录响应时间大于10000微秒的慢查询
slowlog-max-len 128 # 最多记录128条
#服务端命令
time 返回时间戳+微秒
dbsize 返回key的数量
bgrewriteaof 重写aof
bgsave 后台开启子进程dump数据
save 阻塞进程dump数据
lastsave
slaveof host port 做host port的从服务器(数据清空,复制新主内容)
slaveof no one 变成主服务器(原数据不丢失,一般用于主服失败后)
flushdb 清空当前数据库的所有数据
flushall 清空所有数据库的所有数据(误用了怎么办?)
shutdown [save/nosave] 关闭服务器,保存数据,修改AOF(如果设置)
slowlog get 获取慢查询日志
slowlog len 获取慢查询日志条数
slowlog reset 清空慢查询
info []
config get 选项(支持*通配)
config set 选项 值
config rewrite 把值写到配置文件
config restart 更新info命令的信息
debug object key #调试选项,看一个key的情况
debug segfault #模拟段错误,让服务器崩溃
object key (refcount|encoding|idletime)
monitor #打开控制台,观察命令(调试用)
client list #列出所有连接
client kill #杀死某个连接 CLIENT KILL 127.0.0.1:43501
client getname #获取连接的名称 默认nil
client setname "名称" #设置连接名称,便于调试
#连接命令
auth 密码 #密码登陆(如果有密码)
ping #测试服务器是否可用
echo "some content" #测试服务器是否正常交互
select 0/1/2... #选择数据库
quit #退出连接