Pulsar学习笔记
Apache Pulsar™
官方文档:https://pulsar.apache.org/docs/3.3.x/concepts-overview/
组件
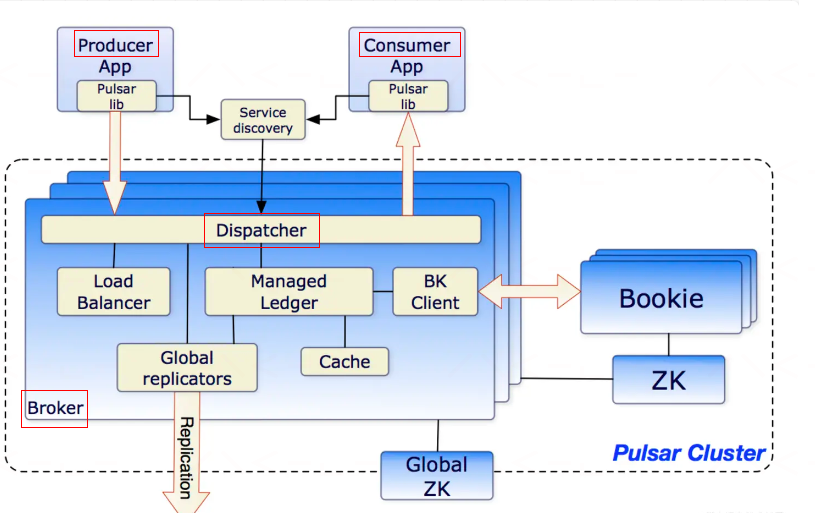
在一个Pulsar集群中:
单个Pulsar集群由以下三部分组成:
Broker:无状态服务层,负责接收和传递消息,集群负载均衡等工作,Broker 不会持久化保存元数据,因此可以快速的上、下线。BookKeeper:有状态持久层,由一组名为 Bookie 的存储节点组成,持久化地存储消息。zookeeper集群,用来处理Pulsar集群之间的协调任务,并存储broker和bookie的元数据。
与传统的消息系统相比,Apache Pulsar 在架构设计上采用了计算与存储分离的模式,Pub/Sub 相关的计算逻辑在 Broker 上完成,数据存储在 Apache BookKeeper 的 Bookie 节点上。
Brokers
Pulsar的broker是一个无状态组件, 主要由两个组件组成:
- 一个HTTP服务器
service discovery,提供REST API用于管理任务和生产者、消费者的主题查找。生产者连接到代理以发布消息,消费者连接到代理以消费消息。 - 一个调度程序
dispatcher,它是一个基于自定义二进制协议的异步TCP服务器,用于所有数据传输。
消息通常从Managed Ledger缓存中读取,除非读取的数据超过缓存大小,则从BookKeeper那里读取Entries(Entry是BookKeeper中的一条记录)
为了支持全局Topic异地复制,Broker会控制Replicators追踪本地发布的Entries,并把这些Entries用Java客户端重新发布到其他区域.
Zookeeper
Pulsar使用Apache ZooKeeper来进行元数据存储、集群配置和协调。元数据包括主题元数据、模式(schema)、代理负载数据等。Pulsar元数据存储可以部署在单独的ZooKeeper集群上,也可以部署在现有的ZooKeeper集群上。
Pulsar还支持其他元数据后端服务,包括etcd和RocksDB(仅适用于独立部署的Pulsar)。
在一个Pulsar实例中:
- 配置存储: 存储租户,命名域和其他需要全局一致的配置项
- 每个集群有自己独立的ZooKeeper保存集群内部配置和协调信息,例如归属信息、broker负载报告、BookKeeper ledger信息
Bookeeper
Pulsar使用一个名为Apache BookKeeper的系统来进行持久消息存储。BookKeeper是一个分布式的预写日志(Write-Ahead Log,WAL)系统,为Pulsar提供了一些重要的优势:
- 独立的分布式日志文件,称为账本(
ledgers)。可以随着时间的推移为主题创建多个账本。 - 非常高效的有序存储,在各种系统故障的情况下,可以处理
entry(条目)数据复制。 - 读取一致性。
- 均匀分配I/O。
- 水平可扩展性。通过向集群添加更多的书记(bookie),可以立即增加容量。
- Bookies被设计成可以承载数千的并发读写的ledgers,且读写IO分离。 使用多个磁盘设备(一个用于日志,另一个用于一般存储)),这样Bookies可以将读操作的影响和对于写操作的延迟分隔开。
- 除了消息数据,游标(Cursors)也被持久地存储在BookKeeper中。游标是消费者的订阅位置。BookKeeper使得Pulsar能够以可扩展的方式存储消费者的位置。
ledgers
账本(Ledger)是一种只追加的数据结构,单进程写入,分配给多个BookKeeper存储节点(也称为bookie)。Ledger entries被复制到多个bookie上。Ledger本身具有非常简单的语义:
- Pulsar代理可以创建Ledger,向账本追加entry,并关闭账本。
- 在Ledger关闭后(无论是显式关闭还是因写入进程崩溃),只能以只读模式打开Ledger。
- 当ledger中的Entry不再有用的时候,可以将整个账本从系统中删除(跨所有bookie)。
Managed ledgers
由于BookKeeper ledgers 提供了统一的日志抽象,因此在ledgers之上开发了一个名为managed ledger的库,它代表单个主题的存储层。一个managed ledger代表了一个消息流的抽象,其中包含一个单一的写入者在流的末尾追加消息,以及多个消费者游标,每个游标都有其关联的位置。
在内部,单个managed ledger使用多个ledgers来存储数据。有两个原因使用多个账本:
- 在发生故障后,一个ledger将无法继续写入,需要创建一个新的ledger。
- 当所有的游标都消费完ledger中的消息时,可以删除ledger。这允许定期对ledger进行切换。
Journal storage
在BookKeeper中,journal文件包含了BookKeeper的事务日志。在对ledger进行更新之前,bookie需要确保描述该更新的事务被写入持久(非易失性)存储中。一旦bookie启动或者旧的日志文件达到了日志文件大小阈值(通过journalMaxSizeMB参数进行配置),就会创建一个新的journal文件。
Pulsar Proxy
Pulsar客户端和Pulsar集群交互的一种方式就是直连Pulsar brokers。有时这种直连既不可行也不可取,因为客户端并不知道broker的地址
Pulsar proxy为所有的broker提供了一个网关, 如果选择运行了Pulsar Proxy,所有的客户都会通过这个代理而不是直接与brokers通信
架构
分片存储
除了存储、计算解耦分离的设计之外,Apache Pulsar 在存储设计上也不同于传统 MQ 的分区数据本地存储的模式,采用的是分片存储的模式,存储粒度比分区更细化、存储负载更均衡。Apache Pulsar 中的每个 Topic 分区本质上都是存储在 Apache BookKeeper 中的分布式日志。Topic 可以有多个分区,分区数据持久化时,分区是逻辑上的概念,实际存储的单位是分片(Segment)的,如图,一个分区 Topic1-Part2 的数据由多个 Segment 组成, 每个 Segment 作为 Apache BookKeeper 中的一个 Ledger,均匀分布并存储在 Apache BookKeeper 群集中的多个 Bookie 节点中, 每个 Segment 具有 3 个副本。
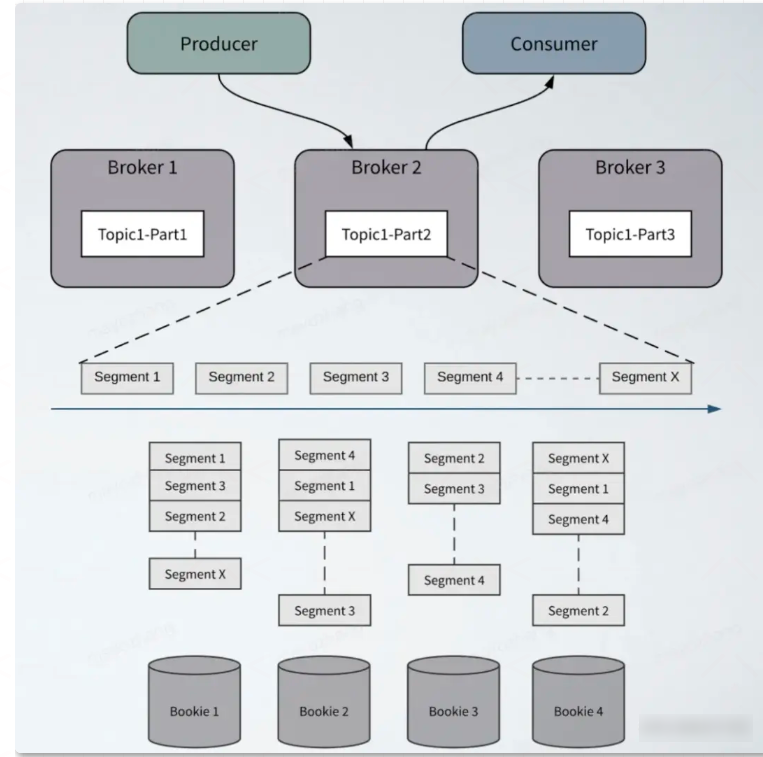
它与传统的紧耦合分区架构而言,将带来一个很大的优势就是,超高的可扩展性以及故障容错性。
高可用及横向拓展
消息服务层和持久存储层是分开的,因此 Apache Pulsar 可以独立地扩展存储层和服务层。
可扩展性
Broker 扩展
在 Pulsar 中 Broker 是无状态的,可以通过增加节点的方式实现快速扩容。当需要支持更多的消费者或生产者时,可以简单地添加更多的 Broker 节点来满足业务需求。Pulsar 支持自动的分区负载均衡,在 Broker 节点的资源使用率达到阈值时,会将负载迁移到负载较低的 Broker 节点,这个过程中分区也将在多个 Broker 节点中做平衡迁移,一些分区的所有权会转移到新的 Broker 节点。
Bookie 扩展
存储层的扩容,通过增加 Bookie 节点来实现。通过资源感知和数据放置策略,流量将自动切换到新的 Bookie 节点中,整个过程不会涉及到不必要的数据搬迁,即不需要将旧数据从现有存储节点重新复制到新存储节点。
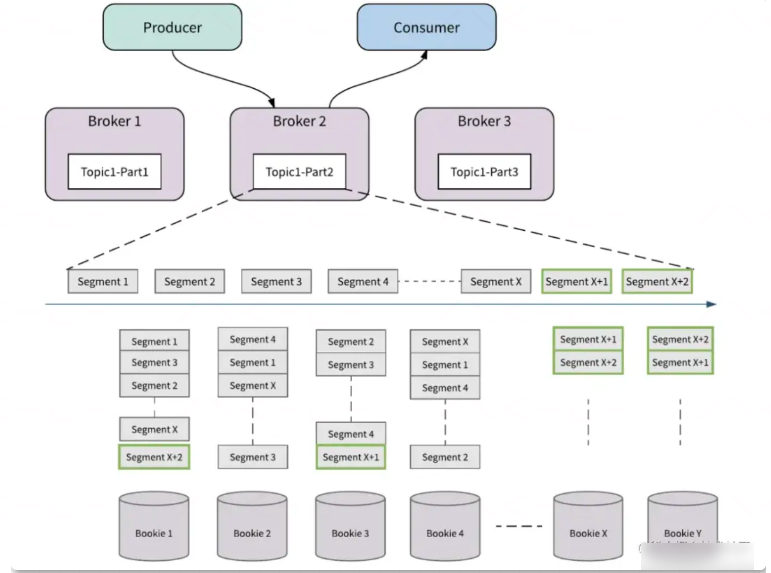
如图所示,起始状态有四个存储节点,Bookie1, Bookie2, Bookie3, Bookie4,以 Topic1-Part2 为例,当这个分区的最新的存储分片是 SegmentX 时,对存储层扩容,添加了新的 Bookie 节点,BookieX,BookieY,那么在存储分片滚动之后,新生成的存储分片, SegmentX+1,SegmentX+2,会优先选择新的 Bookie 节点(BookieX,BookieY)来保存数据。
容错性
得益于计算与存储分离以及分片存储的设计,Pulsar 可以实现独立、灵活的容错。
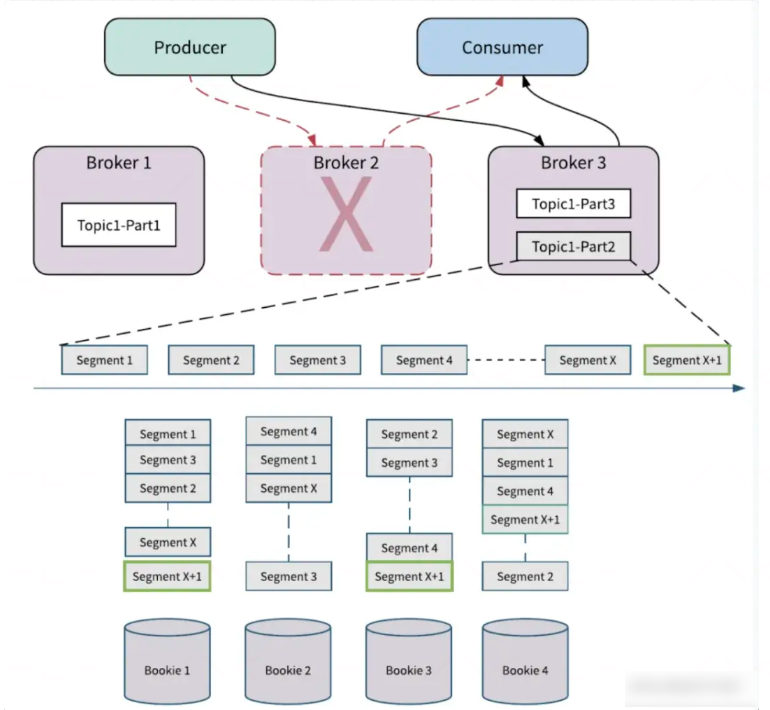
Broker 容错
当 Broker 节点失败时, 以图为例,当存储分片滚动到 SegmentX 时,Broker2 节点失败,此时生产者和消费者向其他的 Broker 发起请求,这个过程会触发分区的所有权转移,即将 Broker2 拥有的分区 Topic1-Part2 的所有权转移到其他的 Broker (Broker3)。在 Apache Pulsar 中数据存储和数据服务分离,所以新 Broker 接管分区的所有权时,它不需要复制 Partiton 的数据。新的分区 Owner(Broker3)会产生一个新的分片 SegmentX+1, 如果有新数据到来,会存储在新的分片 Segment x+1 上,不会影响分区的可用性。
Bookie 容错
当 Bookie 节点失败时,如图所示, 假设 Bookie 2 上的 Segment 4 损坏。Apache BookKeeper Auditor 会检测到这个错误并进行复制修复。Apache BookKeeper 中的副本修复是 Segment 级别的多对多快速修复,BookKeeper 可以从 Bookie 3 和 Bookie 4 读取 Segment 4 中的消息,并在 Bookie 1 处修复 Segment 4。如果是 Bookie 节点故障,这个 Bookie 节点上所有的 Segment 会按照上述方式复制到其他的 Bookie 节点。所有的副本修复都在后台进行,对 Broker 和应用透明,Broker 会产生新的 Segment 来处理写入请求,不会影响分区的可用性。
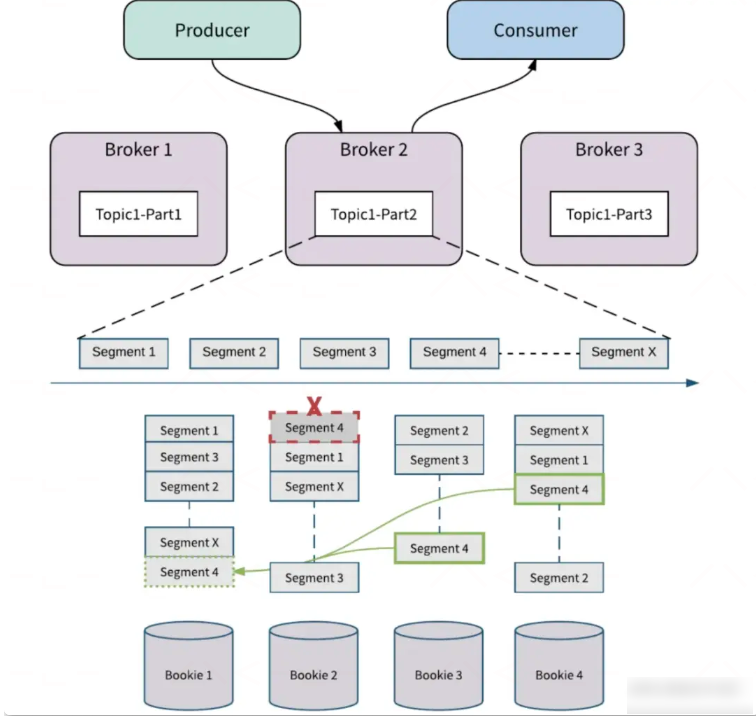
分片存储解决了分区容量受单节点存储空间限制的问题,当容量不够时,可以通过扩容 Bookie 节点的方式支撑更多的分区数据,也解决了分区数据倾斜问题,数据可以均匀的分配在 Bookie 节点上。Broker 和 Bookie 灵活的容错以及无缝的扩容能力让 Apache Pulsar 具备非常高的可用性。
读写分离
Pulsar 另外一个有吸引力的特性是提供了读写分离的能力,读写分离保证了在有大量滞后消费(磁盘 IO 会增加)时,不会影响服务的正常运行,尤其是不会影响到数据的写入。读写分离的能力由 Apache BookKeeper 提供,简单说一下 Bookie 存储涉及到的概念:
- Journals:Journal 文件包含了 BookKeeper 事务日志,在 Ledger 更新之前,Journal 保证描述更新的事务写入到 Non-volatile 的存储介质上。
- Entry logs:Entry 日志文件管理写入的 Entry,来自不同 ledger 的 entry 会被聚合然后顺序写入。
- Index files:每个 Ledger 都有一个对应的索引文件,记录数据在 Entry 日志文件中的 Offset 信息。
Entry 的读写入过程如图七所示,数据的写入流程:
- 数据首先会写入 Journal,写入 Journal 的数据会实时落到磁盘。
- 然后,数据写入到 Memtable ,Memtable 是读写缓存。
- 写入 Memtable 之后,对写入请求进行响应。
- Memtable 写满之后,会 Flush 到 Entry Logger 和 Index cache,Entry Logger 中保存了数据,Index cache 保存了数据的索引信息,然后由后台线程将 Entry Logger 和 Index cache 数据落到磁盘。
数据的读取流程:
- 如果是 Tailing read 请求,直接从 Memtable 中读取 Entry。
- 如果是 Catch-up read(滞后消费)请求,先读取 Index 信息,然后索引从 Entry Logger 文件读取 Entry。
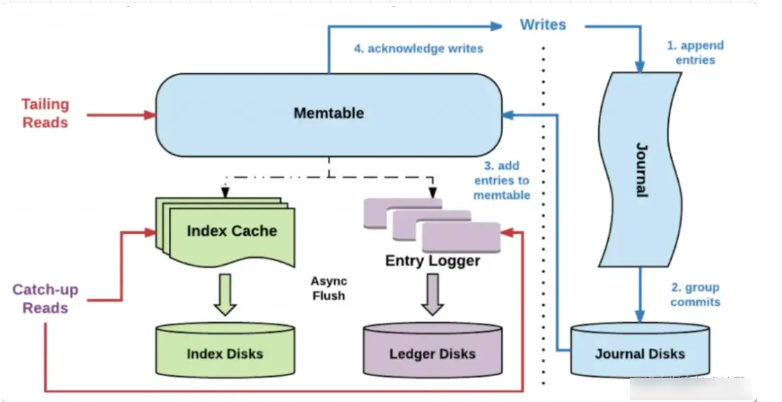
一般在进行 Bookie 的配置时,会将 Journal 和 Ledger 存储磁盘进行隔离,减少 Ledger 对于 Journal 写入的影响,并且推荐 Journal 使用性能较好的 SSD 磁盘,读写分离主要体现在:
- 写入 Entry 时,Journal 中的数据需要实时写到磁盘,Ledger 的数据不需要实时落盘,通过后台线程批量落盘,因此写入的性能主要受到 Journal 磁盘的影响。
- 读取 Entry 时,首先从 Memtable 读取,命中则返回;如果不命中,再从 Ledger 磁盘中读取,所以对于 Catch-up read 的场景,读取数据会影响 Ledger 磁盘的 IO,对 Journal 磁盘没有影响,也就不会影响到数据的写入。
所以,数据写入是主要是受 Journal 磁盘的负载影响,不会受 Ledger 磁盘的影响。另外,Segment 存储的多个副本都可以提供读取服务,相比于主从副本的设计,Apache Pulsar 可以提供更好的数据读取能力。通过以上分析,Apache Pulsar 使用 Apache BookKeeper 作为数据存储,可以带来下列的收益:
- 支持将多个 Ledger 的数据写入到同一个 Entry logger 文件,可以避免分区膨胀带来的性能下降问题。
- 支持读写分离,可以在滞后消费场景导致磁盘 IO 上升时,保证数据写入的不受影响。
- 支持全副本读取,可以充分利用存储副本的数据读取能力。
核心概念
pulsar建立在发布-订阅模式(通常缩写为发布-订阅)之上。在这种模式中,producers向topics发布消息,consumers订阅这些主题,处理传入的消息,并在处理完成时向broke发送acknowledgments。
创建订阅后,即使客户断开连接,Pulsar也会保留所有消息。只有当consumer确认所有这些消息都已成功处理时,才会丢弃保留的消息。
如果消息的消费失败,并且希望再次消费此消息,则可以启用消息重发机制,请求broker重新发送此消息。
消息 message
生产者
Send modes
| 模式 | 描述 |
|---|---|
| Sync send | 生产者在发送每条消息后等待来自broker的确认。如果没有收到确认,则生产者将发送操作视为失败。 |
| Async send | 生产者将消息放入阻塞队列并立即返回。客户端在后台将消息发送到broker。如果队列已满(您可以配置最大大小),则在调用API时,生产者将被阻塞或立即失败,这取决于传递给生产者的参数。 |
Access mode
| 访问模式 | 描述 |
|---|---|
| Shared | 多个生产者可以在一个主题上发布。这是默认设置。 |
| Exclusive | 一个主题只能由一个生产者发表。如果已经有一个生产者连接,其他生产者试图发布这个主题立即得到错误。 |
| WaitForExclusive | 如果已经连接了一个生产者,那么生产者的创建将挂起(而不是超时),直到生产者获得独占访问权限。 |
一旦应用程序成功地创建了具有Exclusive或WaitForExclusive访问模式的生产者,该应用程序的实例就保证是该主题的唯一写入者。任何试图生成关于此主题的消息的其他生产者要么立即得到错误,要么必须等到获得独占访问权。
deliverAfter & deliverAt
在 Pulsar 中使用延迟消息,可以精确指定延迟投递的时间,有 deliverAfter 和 deliverAt 两种方式。其中 deliverAt 可以指定具体的时间戳;deliverAfter 可以指定在当前多长时间后执行。两种方式的本质是一样的,Client 会计算出时间戳送到 Broker。
// deliverAfter发送
producer.newMessage().deliverAfter(3L, TimeUnit.Minute).value("Hello Pulsar!").send();//deliverAt发送
producer.newMessage().deliverAt(1670574629343L).value("Hello Pulsar!").send();消息压缩
消息压缩是优化信息传输的手段之一,我们通常看见一些大型文件都会是以一个压缩包的形式提供下载,在我们消息队列中我们也可以用这种思想,我们将一个batch的消息,比如有1000条可能有1M的传输大小,但是经过压缩之后可能就只会有几十kb,增加了我们和broker的传输效率,但是与之同时我们的cpu也带来了损耗。Pulsar客户端支持多种压缩类型,如 lz4、zlib、zstd、snappy 等。
client.newProducer()
.topic(“test-topic”)
.compressionType(CompressionType.LZ4)
.create();消费者
消息确认 Acknowledgement
| 模式 | 模式 |
|---|---|
| acknowledge individually | 消息立即确认,消费者消费后每一条消息都会给broker发送一个确认请求 |
| acknowledged cumulatively | 消息累计确认,消费者仅提交最后一条消息,流中的所有消息直到(并包括)所提供的消息都不会重新投递给该消费者。 |
// 立即提交api
consumer.acknowledge(msg);// 累计提交api
consumer.acknowledgeCumulative(msg);如果是Shared订阅类型,消息确认只能使用acknowledge individually。因为Shared模式所有消费者共享一条数据。
消息重试
Negative acknowledgement
消息否定机制可以在consumer未成功使用消息时,向broker发送nack,从而将消息重新投递给consumer。
和Acknowledgement一样,消息是立即确认还是累计确认,取决于订阅类型。
Consumer<byte[]> consumer = pulsarClient.newConsumer()
.topic(topic)
.subscriptionName("sub-negative-ack")
.subscriptionInitialPosition(SubscriptionInitialPosition.Earliest)
// the default value is 1 min
.negativeAckRedeliveryDelay(2, TimeUnit.SECONDS)
.subscribe();
Message<byte[]> message = consumer.receive();
// 发送消息否认
consumer.negativeAcknowledge(message);
message = consumer.receive();
// 发送消息确认
consumer.acknowledge(message);redelivery backoff 可以设置重试的时间间隔策略,指定最大和最小时间,在这段时间内通过计算因子计算每次间隔时间:
Consumer<byte[]> consumer = pulsarClient.newConsumer()
.topic(topic)
.subscriptionName("sub-negative-ack")
.subscriptionInitialPosition(SubscriptionInitialPosition.Earliest)
.negativeAckRedeliveryBackoff(MultiplierRedeliveryBackoff.builder()
//最小1s
.minDelayMs(1000)
//最大60s
.maxDelayMs(60 * 1000)
//计算因子 1s 2s 4s 6s 8s 16s …… 60s
.multiplier(2)
.build())
.subscribe();| Redelivery count | Redelivery delay |
|---|---|
| 1 | 1 seconds |
| 2 | 2 seconds |
| 3 | 4 seconds |
| 4 | 8 seconds |
| 5 | 16 seconds |
| 6 | 32 seconds |
| 7 | 60 seconds |
| 8 | 60 seconds |
只有在Shared和Key_Shared订阅类型中,消费者可以逐个否定消息, Exclusive 和 Failover 消费者只确认他们收到的最后一条消息。
如果是对消息有序性有要求,在否定消息后,顺序无法得到保证
Acknowledgement timeout
如果指定了ack超时时间,且未提交确认消息,客户端会向broker发送重新发送未确认消息的请求,与Negative acknowledgement 相比,不建议使用。因为很难去设置超时时间。
当消息处理时间超出超时时间时,会发起不必要的消息重试。
如果想使用nack,需要保证在acknowledgment timeout前将消息进行提交,不对ack timeout进行设置即可
Consumer<byte[]> consumer = pulsarClient.newConsumer()
.topic(topic)
.ackTimeout(2, TimeUnit.SECONDS) // 默认值为0
.ackTimeoutTickTime(1, TimeUnit.SECONDS) //每s检查一次
.subscriptionName("sub")
.subscriptionInitialPosition(SubscriptionInitialPosition.Earliest)
.subscribe();
Message<byte[]> message = consumer.receive();
// 等待至少2s
message = consumer.receive();
consumer.acknowledge(message);Retry letter topic
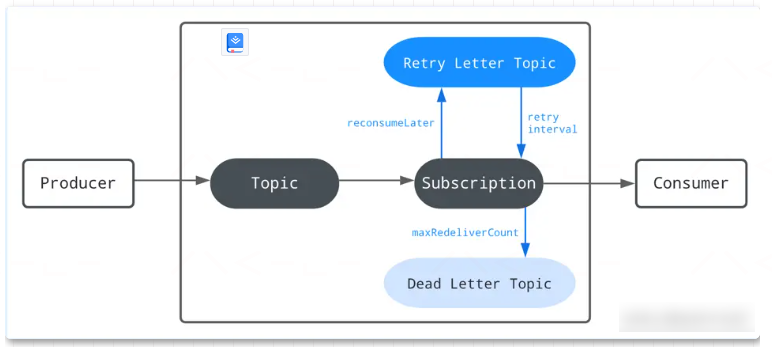
Retry letter topic允许您存储未能使用的消息,并在以后重试使用它们。使用此方法,您可以自定义重新传递消息的间隔。原始主题上的消费者也会自动订阅重试信件主题。一旦达到最大重试次数,未使用的消息将被移动到死信主题以进行手动处理。
目前在Shared和Key_Shared订阅类型下才能使用
使用 Retry letter topic 与 delayed message delivery 两者都旨在稍后使用消息,区别在于Retry letter topic 用于故障处理,确保关键数据不会丢失,而delayed message delivery 是以指定的延迟时间传递消息。
与nack相比,Retry letter topic更适合于需要大量重试且重试间隔可配置的消息。因为Retry letter topic中的消息被持久化到BookKeeper,而由于nack需要重试的消息被缓存到客户端。
缺省情况下,禁用自动重试功能。您可以将enableRetry设置为true,在consumer上启用自动重试。使用以下API来消费来自Retry letter topic的消息。当达到maxRedeliverCount的值时,未使用的消息将被移动到Dead letter topic
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
//开启重试
.enableRetry(true)
.deadLetterPolicy(DeadLetterPolicy.builder()
//最大重试次数,超过发送到死信队列
.maxRedeliverCount(maxRedeliveryCount)
.build())
.subscribe();retryLetterTopic 用来设置重试队列的topic名称,如果不设置默认为:
<topicname>RETRY<subscriptionname>使用以下API将消息存储在重试队列中。
consumer.reconsumeLater(msg, 3, TimeUnit.SECONDS);死信队列 Dead letter topic
Dead letter topic服务于消息的重新发送,它由acknowledgement timeout 、negative acknowledgement、retry letter topic触发,消费失败的消息
目前在Shared和Key_Shared订阅类型下才能使用。如果设置了maxRedeliverCount 会默认开启死信队列的投递。
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.build())
.subscribe();如果不设置名称,系统默认为
<topicname>DLQ<subscriptionname>默认情况下,在DLQ主题创建期间没有订阅。如果不及时订阅DLQ主题,可能会丢失消息。要为DLQ自动创建初始订阅,可以指定initialSubscriptionName参数。如果设置了这个参数,需要保证broker侧的配置allowAutoSubscriptionCreation是开启的,才能有效创建DLQ生成器。
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.deadLetterTopic("my-dead-letter-topic-name")
.initialSubscriptionName("init-sub")
.build())
.subscribe();消息延迟投递
延迟消息传递使您可以稍后使用消息。在这种机制中,消息存储在BookKeeper中。在消息发布到broker之后,DelayedDeliveryTracker在内存中维护时间索引(time -> messageId)。一旦指定的延迟结束,该消息将被传递给使用者。
延迟消息传递仅适用于Shared类型。在Exclusive和Failover类型中,延迟消息将立即分派。
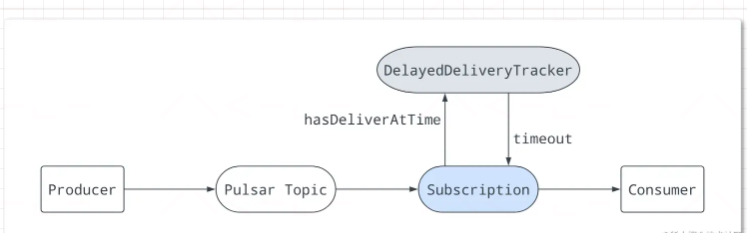
broker保存消息而不进行任何检查。当consumer消费时,如果消息被设置为延迟,则该消息将被添加到DelayedDeliveryTracker。subscription从DelayedDeliveryTracker检查并获取超时的消息。
事务消息
Pulsar 事务消息的适用场景为一次事务中需要发送多个消息的情况,保证多个消息之间的事务约束,即多条消息要么都发送成功,要么都发送失败,而不是保证本地事务的执行和发送消息的事务约束
这里以一个资金流转场景举例,分账系统收到订单系统发送的一条信息A,然后进行自己的逻辑处理后,需要往余额系统投递两条信息B、C
这里的ack A、send B、send C,三个动作即构成一个事务
//在初始化pulsarClient的时候需要开启enableTransaction
PulsarClient pulsarClient = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
//开启事务支持
.enableTransaction(true)
.build();
//收到消息A
message = consumer.receive(10, TimeUnit.SECONDS);
//自己的各种业务逻辑.....
//开启一个事务
Transaction transaction = pulsarClient.newTransaction()
.withTransactionTimeout(5, TimeUnit.MINUTES)
.build().get();
//发送消息B
producer.newMessage(transaction).value("B".getBytes()).sendAsync();
//发送消息C
producer.newMessage(transaction).value("C".getBytes()).sendAsync();
//ack消息A
consumer.acknowledgeAsync(message.getMessageId(), transaction);
//提交事务
transaction.commit().get();
//或者回滚事务
transaction.abort().get();主题 topic
命名规则
与其他pub-sub系统一样,pulsar中的主题被命名为通道,用于将消息从生产者传输到消费者。topic的定义应遵循以下结构:
{persistent|non-persistent}😕/tenant/namespace/topic
| Topic name component | Description |
|---|---|
persistent / non-persistent | Pulsar支持两种类型的的topic: persistent and non-persistent.默认是持久化的,表示所有消息都持久化在磁盘上,而未非持久化的主题不会存储在磁盘上 |
tenant | 实例内的主题租户。租户对于Pulsar中的多租户至关重要,并且分布在集群中。 |
namespace | 管理主题的单元,类似于分组机制,大多数主题都配置在 namespace 上. 每一个租户可以有多个 namespaces. |
topic | 名字组成的最后的一部分,它在pulsar中没有特殊的含义 |
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
.build();
// 指定非持久化topic
String npTopic = "non-persistent://public/default/my-topic";
String subscriptionName = "my-subscription-name";
Consumer<byte[]> consumer = client.newConsumer()
.topic(npTopic)
.subscriptionName(subscriptionName)
.subscribe();Multi-topic
当消费者订阅一个pulsar主题时,默认情况下它会订阅一个特定的主题,例如persistent://public/default/my-topic。然而,从1.23.0版本开始,pulsar可以同时订阅多个主题。可以用两种方式定义主题列表:
- 基于正则表达式(regex),例如persistent://public/default/finance-.*
- 通过显式定义主题列表
当通过regex订阅多个主题时,所有主题必须在相同的名称空间中。
当生产者向单个主题发送消息时,所有消息都保证以相同的顺序从该主题读取。然而,这些保证并不适用于Multi-topic。因此,当生产者向多个主题发送消息时,从这些主题读取消息的顺序不能保证相同。
// 订阅所有 namespace 下所有topic
Pattern allTopicsInNamespace = Pattern.compile("persistent://public/default/.*");
Consumer<byte[]> allTopicsConsumer = pulsarClient.newConsumer()
.topicsPattern(allTopicsInNamespace)
.subscriptionName("subscription-1")
.subscribe();
// 订阅某个 namespace 下所有topic
Pattern someTopicsInNamespace = Pattern.compile("persistent://public/default/foo.*");
Consumer<byte[]> someTopicsConsumer = pulsarClient.newConsumer()
.topicsPattern(someTopicsInNamespace)
.subscriptionName("subscription-1")
.subscribe();Partitioned topics
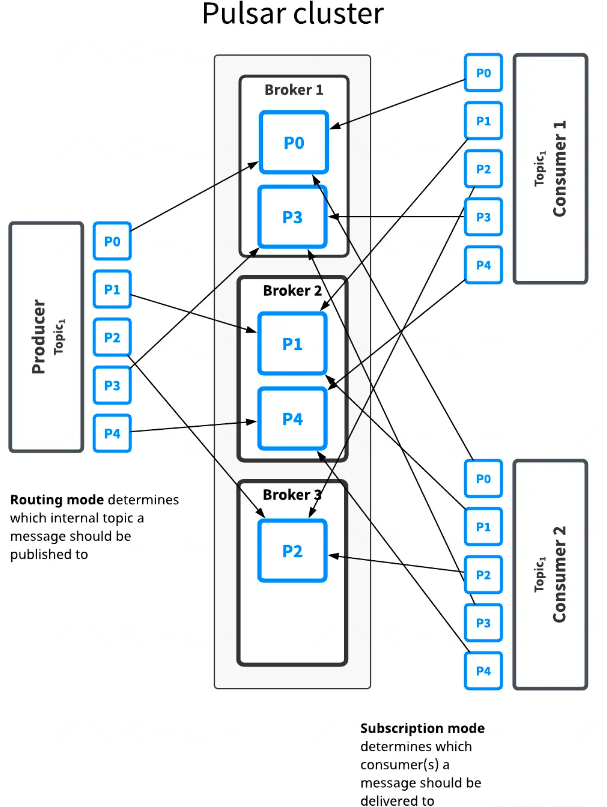
如图所示,topic1中有5个分区(p0-p4),他们分布在3个broker上,因为partition比broker多,所以两个broker一次处理2个partition,另一个代理只处理一个partition。
这个topic的消息将广播给2个消费者,路由模式决定每条消息应该发布到哪个分区,而订阅类型决定哪些消息发送给哪个消费者,在大多数情况下,可以分别决定路由和订阅模式。通常,吞吐量问题应该使用分区/路由决策,而订阅类型的决策取决于应用程序具体的使用场景。
Routing modes 路由模式
| Mode | Description |
|---|---|
RoundRobinPartition | 如果没有提供key,生产者将以轮询方式跨所有分区发布消息,以实现最大吞吐量。请注意,轮循不是针对单个消息进行的,而是将其设置为相同的批处理延迟边界,以确保批处理有效。如果在消息上指定了一个键,则分区生产者将对该键进行散列,并将消息分配给特定的分区。这是默认模式。 |
SinglePartition | 如果没有提供key,生产者将随机选择一个分区,并将所有消息发布到该分区中。如果在消息上指定了一个键,则分区生产者将对该键进行散列,并将消息分配给特定的分区。 |
CustomPartition | 使用将被调用的自定义消息路由器实现来确定特定消息的分区。用户可以使用实例创建自定义路由模式使用 Java client 并实现 MessageRouter 接口。 |
如果消息附加了一个键,当使用SinglePartition或RoundRobinPartition模式时,消息将根据ProducerBuilder中HashingScheme指定的散列方案路由到相应的分区。
| Ordering guarantee | Description | Routing Mode and Key |
|---|---|---|
| Per-key-partition | 具有相同键的所有消息将按顺序排列并放置在同一分区中. | 使用SinglePartition或RoundRobinPartition模式,Key由每条消息提供。 |
| Per-producer | 来自同一生产者的所有消息都是有序的。 | 使用SinglePartition模式,不为每条消息提供Key。 |
HashingScheme是一个枚举,它表示在为特定消息选择分区时可用的标准散列函数集。 有两种类型的标准哈希函数可用:JavaStringHash和Murmur3_32Hash。生产者的默认哈希函数是JavaStringHash。请注意,当生产者可以来自不同的多语言客户端时,JavaStringHash是没有用的,在这种情况下,建议使用Murmur3_32Hash。
订阅者 Subscriptions
订阅类型
pulsar中有四种订阅类型:exclusive、shared、failover和key_shared。这些类型如下图所示。
根据消息传递的顺序性和实时性可以将消息模型分为两类:
- queuing 模型主要是采用无序或者共享的方式来消费消息。
- streaming 模型要求消息的消费严格排序或独占消息消费
订阅模式
| Subscription mode | Description | Note |
|---|---|---|
Durable | cursor是持久的,它保留消息并持久保存当前位置。如果代理从故障中重新启动,它可以从持久存储(BookKeeper)中恢复cursor,这样就可以从上次消费的位置继续消费消息。 | Durable 是默认的订阅模式。 |
NonDurable | cursor是非持久的。一旦代理停止,cursor将丢失,并且永远无法恢复,因此消息不能从最后消费的位置继续消费。 | Reader的订阅模式本质上是NonDurable的,它不阻止主题中的数据被删除。Reader的订阅模式无法更改。 |
可以使用java client api 进行设置
Consumer<byte[]> consumer = pulsarClient.newConsumer()
.topic("my-topic")
.subscriptionName("my-sub")
.subscriptionMode(SubscriptionMode.Durable)
.subscribe();
Consumer<byte[]> consumer = pulsarClient.newConsumer()
.topic("my-topic")
.subscriptionName("my-sub")
.subscriptionMode(SubscriptionMode.NonDurable)
.subscribe();