生产事件
1、线上 pod 反复重启
- [20230621] 伟酱
1.1、问题描述
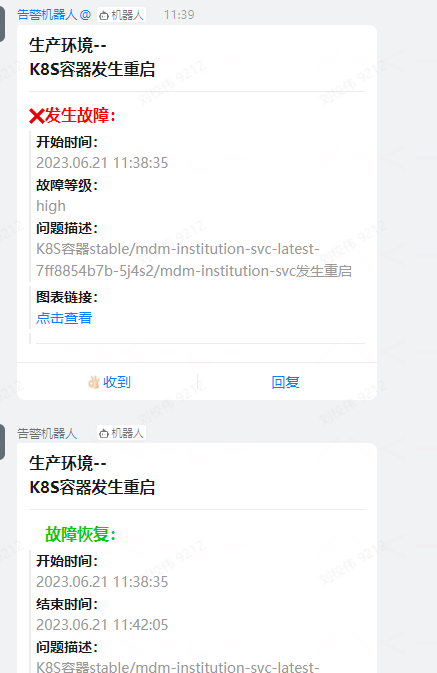
1.k8s pod mdm-institution-svc-latest-7ff8854b7b-5j4s2 从凌晨开始 反复 重启
1.2、问题定位
1.通过告警查看 grafa 监控 查看服务 JVM
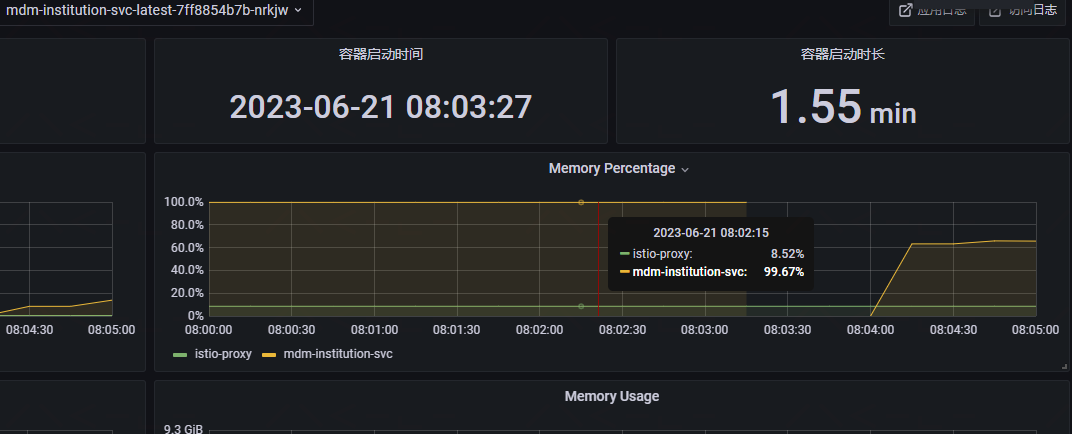
服务占用pod内存几乎打满
2.定位慢接口或接口请求
通过skyingwalking 发现 /departmentTrading/list 这个接口的请求相对较多

但接口响应是正常的
3.进入pod查看 jvm配置和 pod内存


分析一波GC 感觉也没什么问题
这样一看 似乎不是 jvm本身的问题,问题指向到运维K8s POD那边

CICD上看了一下这个服务的JVM配置
最小和最大堆内存 设置为 8G
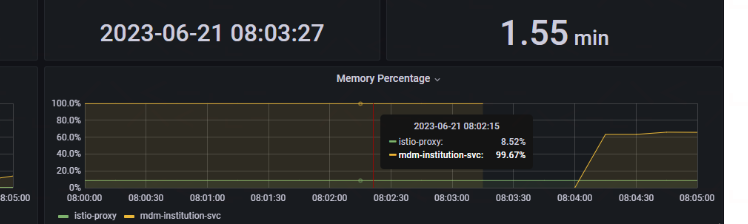
JVM堆内存分配多了!
当jvm服务JVM内存+堆外内存 超过 POD内存 limit ,POD直接 kill 了
1.3、解决方案
最后重新合理分配一下 JVM 堆内存
-Xms6144m -Xmx6144m
重新滚动一下服务
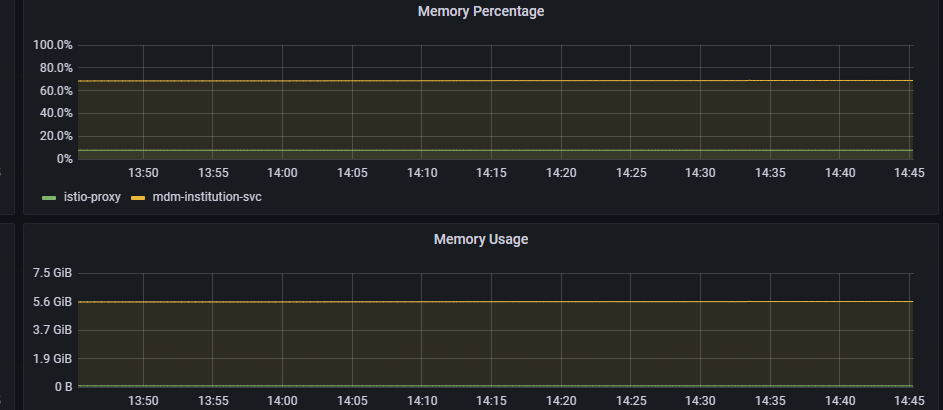
监控正常 服务也没有再发生告警!
解决问题!
堆外内存 是如何被使用的?[待续...]